



Decision Tree Classification — What is Expected from It?
Last Updated on July 25, 2023 by Editorial Team
Author(s): Sujeeth Kumaravel
Originally published on Towards AI.
You have a dataset of 20 cars. Among them, 10 are luxury cars, and the other 10 are non-luxury. This dataset is represented in the node shown below. A node is essentially a set containing members — in this case, cars. The green plus signs are luxury cars, and the red minus signs are non-luxury.
In this dataset, there are an equal number of luxury and non-luxury cars. Such datasets are called balanced datasets.
The dataset has values of 3 features of each car.
- price
- fuel economy
- automation level
Example values of these features:
- Price — 12 lakh Indian Rupees. This is represented as 12L. This is a continuous variable.
- Fuel economy — there are 2 values for this feature — high and low. For example, high can be fuel economy ≥ 15 kmph. Then low is fuel economy < 15 kmph. fuel economy is an ordinal categorical variable (ordinal because there is an order among its two values).
- Automation level — there are 6 levels of driving automation in a car, represented as L0, L1, to L5. L0 is the lowest, and L5 is the highest. Let us assume the cars we are considering in this problem will either be L1 or L2. So, this feature is also an ordinal categorical variable.
In the dataset, we are given which cars are luxury and which are non-luxury. Our objective is:
- We will be given a car in the future with values for the 3 features. But, we will not know whether it is luxury or non-luxury.
- We need to predict whether it is a luxury or a non-luxury one.
This problem is called binary classification. Since the dataset given to us is balanced, the classification is called balanced classification.
As a first step, let us divide the dataset into 2 subsets. The hope in this splitting process is to generate subsets in such a way that each subset is as homogenous as possible. What this means is that the members within each subset are as similar as possible to each other. The splitting process is done using the 3 features.
Let us split the dataset using the price feature. Let us put the members that have a price ≥ 15L into one subset and those below 15L into another.
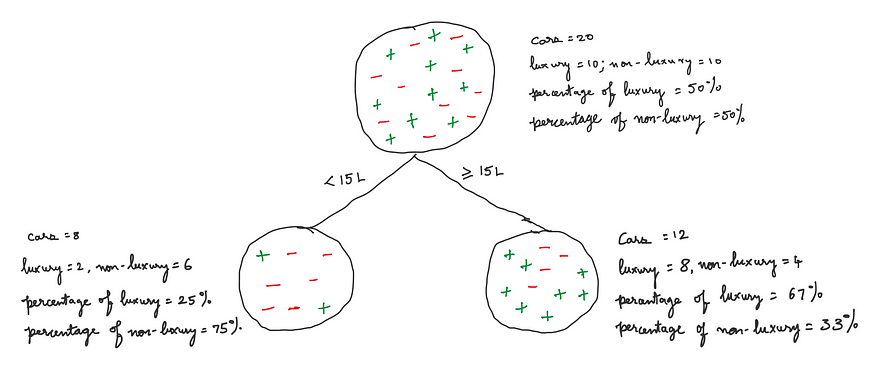
The parent node has 20 cars, the left child node has 8, and the right one has 12. In the left child node, there are 2 luxury cars and 6 non-luxury. So, there is a higher percentage of non-luxury, i.e., most of the cars are non-luxury. In the right child node, most of the cars are luxury. This makes sense because luxury cars will be more expensive.
If a new car with values for the 3 features is given to us, we see its price and ask a question, which of the child nodes will the new car fall into? Whichever class is the majority in that child node, we will predict that as a class of the car. For example, if the price of the new car is 18L, we predict that as a luxury one.
One of the benefits we get from this splitting process is that we can be more confident in predicting a new car as luxury/non-luxury using the child nodes than using the parent node alone. In the parent node, there is no clear majority, and we will not be able to say confidently that the new class is luxury or non-luxury. But since the distribution of cars in each of the child nodes is skewed towards one class, we will be able to say with more confidence that the new car belongs to the majority class in whichever child node it falls under.
But, we have performed the splitting process with one feature variable only. Now 2 questions arise:
- Why was the value 15L chosen for the price to split the dataset?
- What kind of split will we get if we use either of the other 2 features?
Let us perform the split based on the fuel economy. The split looks like

Now, let us perform the split based on the automation level. The split looks like

The split based on automation level makes sense because luxury cars are more likely to have L2 automation than non-luxury ones. Similar reasoning applies to L1 automation.
We have created 3 different decision trees each based on one of the 3 feature variables. In each tree, we have split the dataset into 2 subsets based on a decision. In decision trees, each node is a set of members in the dataset, and each edge is a decision.
The 2 decision trees are shown below.

Which of these 3 decision trees gives us more confidence to us in predicting whether a new car given to us in the future with values for the 3 features is luxury or not? Ideally, we would have liked all luxury cars to be in one child node and all non-luxury ones in the other node.
The decision tree created using the automation level feature is able to segregate luxury and non-luxury cars better. The left child node in which the luxury cars are present as the majority has 80% of all members as luxury. But, in the 2 other decision trees, the percentage of luxury cars in the child nodes with the majority of luxury cars is less than 80%. So, the decision tree based on automation level is better in terms of prediction confidence as it has produced almost pure child nodes.
So, the expectation from a decision tree in a classification setting is that it produces child nodes that contain one of the classes with as high homogeneity as possible so that we can make a prediction with high confidence based on which child node a new datapoint falls into.
This decision tree-building process can be performed for multiclass classification and imbalanced classification as well. I will explain how to mathematically perform the splitting process in future posts.
Signing off now!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

