



CLIP for Language-Image Representation
Last Updated on July 25, 2023 by Editorial Team
Author(s): Albert Nguyen
Originally published on Towards AI.
A multi-modal architecture bridges the gap between Natural Language and Visual understanding.
Have you ever wondered how machines can understand the meaning behind a photograph? CLIP, the Contrastive Language-Image Pre-training model, is changing the game of image-language understanding. In this post, we will explore why CLIP is so stunning with its ability.
We have seen AI’s potential to solve many problems in our world. The famous AI models such as ChatGPT, LLaMA, or DALLE, etc., changing our lives (In a good way, I suppose) are direct evidence. Large language models, like ChatGPT and LLaMA, have proven to be good tools to support our writing and searching. These models are trained on text data and only respond to text inputs. We call these unimodal models as they work with one data type. On the other hand, DALLE2 can generate images from texts and is a multimodal model. Such models require AI to understand both language and image data.
Traditional AI-based models had a hard time understanding both language and images. The problem was that natural language processing and computer vision were seen as two separate fields, making it challenging for machines to communicate effectively between the two.
However, CLIP’s multimodal architecture changes things by learning language and visual representation in the same latent space. Therefore, CLIP allows us to leverage other architecture using its ‘language-image representations’ for downstream tasks.
The architecture
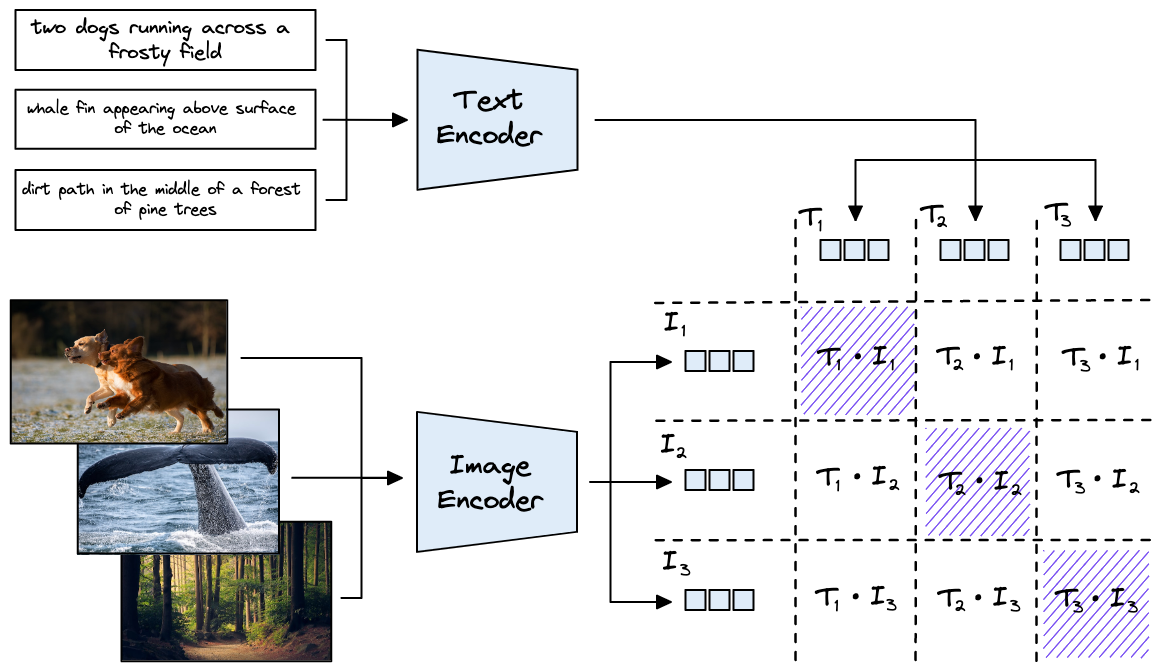
The CLIP architecture consists of two main components: an image encoder and a text encoder. Each encoder is capable of understanding information from either images or text, respectively, and embedding that information into vectors. The idea of CLIP is to train these encoders in a large dataset of image-text pairs and make the embeddings become similar.

“Given a batch of N (image, text) pairs, CLIP is trained to predict which of the N × N possible (image, text) pairings across a batch actually occurred.” It learns a multi-modal embedding space by jointly training its encoders to maximize the cosine similarity of the image and text embeddings of the N real pairs in the batch while minimizing the cosine similarity of the embeddings of the N2 − N incorrect pairings.
As CLIP is trained on a large pre-training dataset, it can generalize well in many downstream tasks. Since CLIP provides us with two encoders that can embed text and image into the same latent space, we can effectively use it for many applications.
The Applications
Here are some examples of downstream tasks that CLIP has been used for:
Image classification
CLIP has been used for image classification tasks, such as identifying different species of plants and animals in images.
CLIP’s ability to associate images with their corresponding text descriptions allows it to generalize well to new categories and improve performance compared to other image classification models.
For this one, there is a simple example provided by HuggingFace
from PIL import Image
import requests
from transformers import CLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
Image captioning
Image captioning can be used to solve various problems. For example, we can ask the model to summarise images about some survey results to create reports.
CLIP can be used for image captioning tasks, which involve generating natural language descriptions of images. By leveraging its ability to associate images with corresponding text descriptions, we can combine CLIP with other sequence-to-sequence models to use the embedding of CLIP to generate captions, etc. These models can be trained efficiently when taking benefits from CLIP. For some examples, we can refer to our CoCa (Contrastive Captioning), or CLIPCap, which combines CLIP with a GPT model to generate caption.
Text-to-Image
One interesting application of CLIP in the context of text-to-image generation is the Latent Diffusion model. This model uses CLIP as a way to guide the generation of realistic images from textual descriptions.
The use of CLIP in the Latent Diffusion model has several advantages. First, it allows the model to generate images that are more faithful to the textual description since CLIP can provide feedback on the semantic similarity between the generated image and the textual description. Second, it allows the model to generate images that are more diverse and creative since CLIP can guide the generation process toward less common but still plausible image representations.
Overall, CLIP’s ability to handle both image and text inputs and its pre-training process make it a versatile and powerful tool for a wide range of downstream tasks in various domains.
Conclusion
Clearly, CLIP’s ability to combine language and image representation into one has opened the door for many applications. While we humans can perceive different types of data, including text, data, audio, etc. AI-based models in the past have shown their weaknesses where they can only understand one modal. With CLIP, we can imagine a future where there are AI models that can “understand” the world just like us.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

