



Can Contrastive Learning Work? — SimCLR Paper Explained
Last Updated on July 15, 2023 by Editorial Team
Author(s): Boris Meinardus
Originally published on Towards AI.
A comprehensive summary of the SimCLR framework and its important findings.
In my last blog post, we talked about the goal of representation learning, specifically using Self-Supervised Learning.
We then came up with the idea of contrastive learning and will now have a look at one of the most important papers in Self-Supervised Learning that successfully implements this idea but also has key weaknesses: A Simple Framework for Contrastive Learning of Visual Representations (T. Cheng et al.), or for short, SimCLR. You can find the paper on Arxiv!
This is their framework, and if we look at it, we can recognize almost every element!
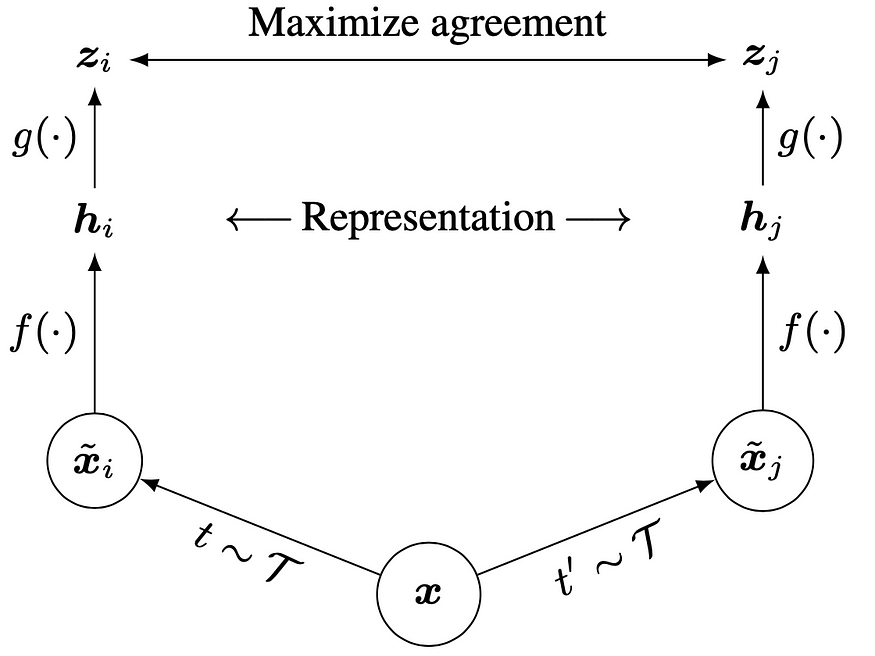
We have our original image x. We now apply two different sets of random augmentations t and t’ to get the two different views x~_i and x~_j. We now pass them through the same neural network to get our hidden representations and eventually maximize the agreement between the two embedding vectors.
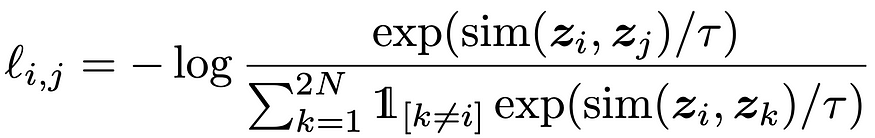
Maximizing the agreement here simply means we minimize our contrastive loss, in other words, we maximize the similarity between our positive samples and minimize the similarity between those positive and other negative examples.
Previously, we simply talked about directly minimizing the Euclidean distance between the two representation vectors, but SimCLR uses cosine similarity as their measure of similarity.

So far, there is nothing that we didn’t already know, but as mentioned, the devil lies in the detail. This base idea is very sensitive, and getting it to actually work requires specific care!
You might have already asked yourself why there are two functions, f(x) and g(x). f(x) is the neural network that produces the hidden representations we want to use for our downstream tasks. However, applying our contrastive loss to those representations directly simply empirically doesn’t return the best results. Instead, the authors introduce a second projection network that then returns the embeddings to we actually apply our loss to.
Additionally, this framework is very sensitive to the set of augmentations we apply and how large the batch size is during training!
Why is the batch size so important? Well, because all the negative samples used in our contrastive loss by design come with our batch!
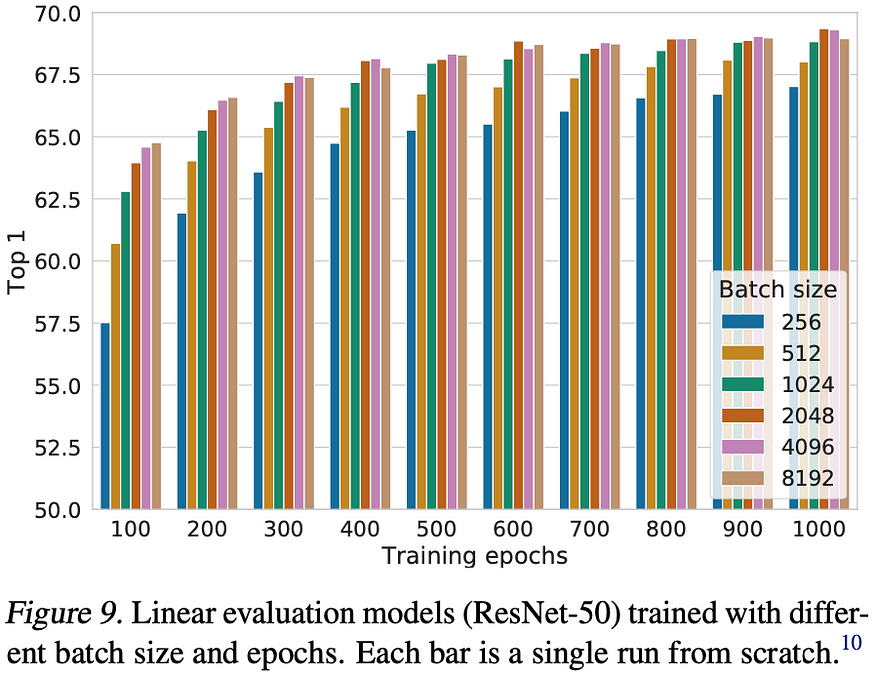
If we look at the Top-1 accuracy during training for different batch sizes, we can clearly see, that larger batch sizes are crucial, which makes sense, right? The more negative samples we have, the better the model can assess where NOT to place the embeddings in the representation space.
Before you ask, simply using one sample from the batch as a positive example and the remaining samples as negative examples, simply by chance, might lead to minimizing the similarity between two samples that, in reality, include the same object.
And you can imagine, that with fewer different objects, or classes, in the training dataset, the chance of having samples containing the same object is more likely.
But, okay! Up until now, we know we need an additional projection head and a very large batch size. And what about the sensitivity to augmentations?

Well, since it’s Google we’re talking about here, with virtually endless resources, they simply went ahead and did a full grid search over all combinations of two augmentations that can be applied. And we can clearly see that some augmentations increase the accuracy significantly more than others. We can see that cropping out a part of the image and resizing it overall seems to be very important. But cropping in combination with color distortions is the best combination. Cropping, in particular, is really powerful as it has the strongest learning signal when it comes to understanding the context of an image!
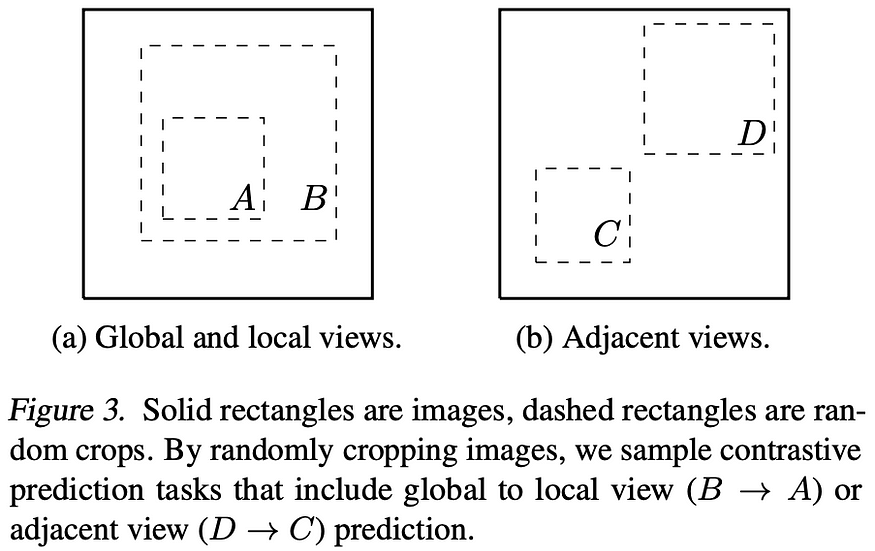
While cropping two different parts of the same image, we pretty much integrate a new prediction task into our contrastive loss. In one case, the model needs to understand global to local context, i.e., the model needs to understand that the smaller crop out is part of the larger crop out that itself belongs to the original, full object we are looking for. Or, in the other case, it has to understand the context between adjacent views, where two different parts actually belong to the same object.
Okay, that’s really powerful, but why is the addition of changing the color of both views so important?

Well, what often happens with different crops of one image is that the pixel intensities over all channels (RGB) appear to have very similar distributions.
If we look at the respective pixel intensity histograms over 4 crops of the same image, we can see that they are pretty much the same! So, what happens is that the model learns a shortcut! It pretty much learns to map those histograms as embeddings into representation space, instead of extracting the more important features that include complex shapes.
If we now apply random color distortions to the crops or different views, we can see that the histograms are completely different.
It’s somewhat like forcing a child to learn to solve maths problems without a calculator. That way it must learn the underlying rules and patterns of maths to solve the problem, instead of simply learning to use the calculator.
But with those little tricks and implementation details, the authors successfully realized a simple framework that implemented the base idea of contrastive learning and was the new state-of-the-art model for self-supervised learning.
Results
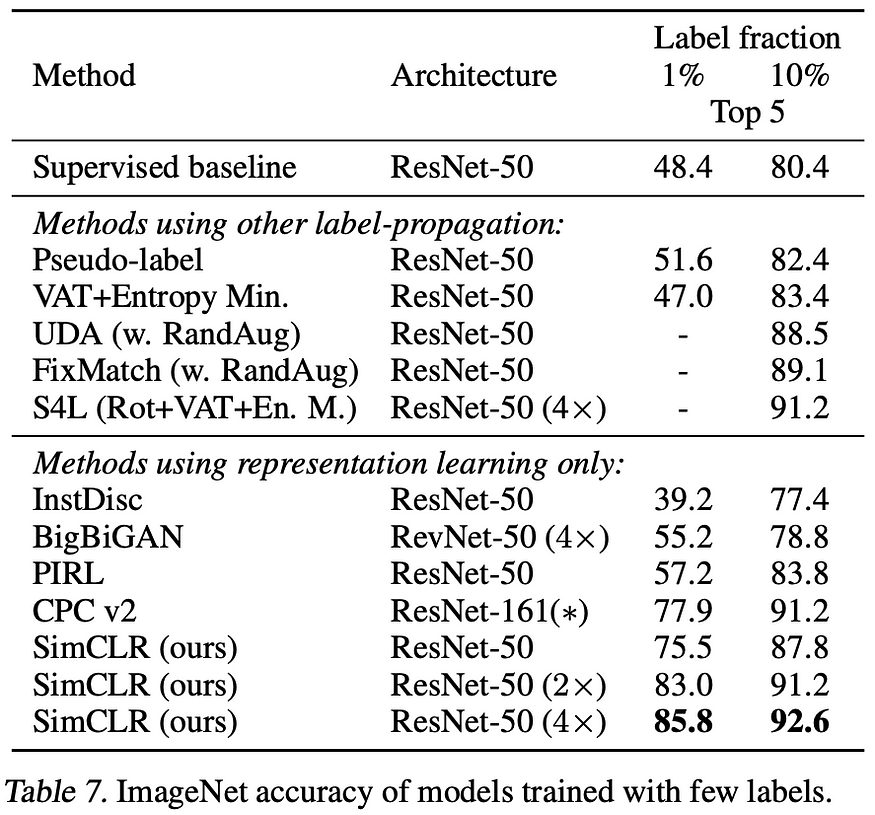
When comparing SimCLR to different approaches that all use the ResNet50 architecture and either supervised or representation learning only as pretraining we can clearly see that SimCLR outperforms all of them. Especially the larger models, i.e., models where the width or number of neurons in a layer of the model are increased by 2x or 4x, respectively.
On this transfer-learning task specifically, the advantage of using self-supervised pre-training instead of supervised starts to become evident. Not only does one have access to a lot more data, since we don’t need any labels, but the learning signal is also stronger. I will elaborate on that a bit more in a future video! After pre-training all parameters of the model, i.e., the new prediction head and the pre-trained feature extractor, the model is fine-tuned on 1% and 10% of the ImageNet dataset, respectively. The supervised model is also fully trained but only on that 1 and 10% of the data. All baseline models, the fully supervised trained model especially, perform worse than SimCLR.
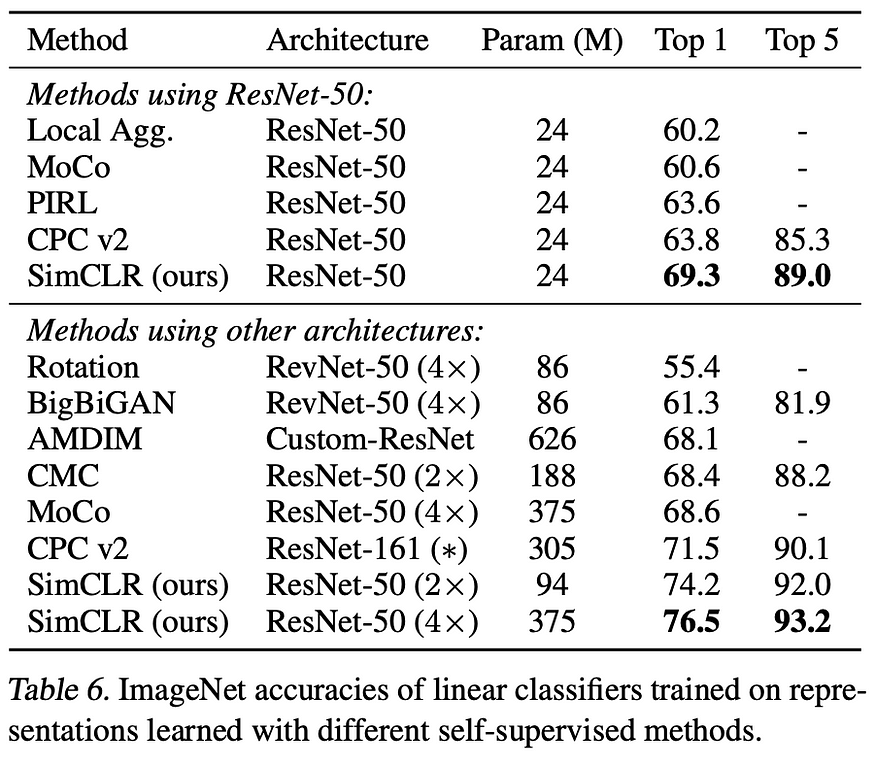
This also holds when comparing the performance on linear evaluation benchmarks, i.e., having fixed feature extractor weights and only finetuning the linear prediction head. Even when comparing different architectures of different sizes, the 94 Mio. Parameter SimCLR model outperforms larger models!

But as we can see, SimCLR still does not reach the performance of a fully supervised trained model.
Okay, that’s all great, but this sensitivity to the specific augmentations used and the necessity of very large batch sizes are really not ideal.
Especially the large batch size is a significant constraint since there are clear memory limitations and training costs that build up. Please, give it a try and start some computer vision training with a batch size of over 4000! Also, how do we sample those negative examples? There have been different approaches that use extra memory banks that store the sets of negative examples to avoid reliance on large batch sizes. But do we just sample random examples, or can we implement more sophisticated selection strategies? There are many ideas. E.g., instead of employing semantic-preserving transformations, in simple words, basic image augmentations, to generate positive instances, it is also feasible to extract positive pairs that naturally occur within the data.

Sermanet et al. introduced Time-Contrastive (TC) Learning, which utilizes video frames to establish an iconic triplet loss. In this approach, the positive pairs are derived from neighboring frames, while the negative pairs originate from distant frames.
Nevertheless, there are quite a few questions and problems that arise with the dependence on negative samples.
So, in short, negative examples are annoying! The question is: Do we really need them?
Let’s return to our dual-view pipeline and think of another idea, how to avoid collapse. But keep that for next time.
If you want to see this new idea, which, by the way, is completely weird and pure black magic, then you should read the next post! This idea is actually the origin of all of the newest state-of-the-art Self-Supervised models like DINO and the very new I-JEPA!
So, if the post is not up yet, don’t forget to give me a follow to not miss the upload!
P.S.: If you like this content and the visuals, you can also have a look at my YouTube channel, where I post similar content but with more neat animations!
All Images are taken from the SimCLR paper, created by the author with images the author has the rights to use, or by the referenced source.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

