



AI at Rescue: Claims Prediction
Last Updated on July 5, 2022 by Editorial Team
Author(s): Supreet Kaur
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Overview
The insurance industry is one of the early adopters of vanilla algorithms such as Logistic Regression. The insurance industry has seen a recent surge in leveraging predictive analytics to analyze the probable future of a claim. Results of these algorithms provide decision support to claim managers.
Mentioning some of the many use cases in the insurance and re-insurance industries below:
- Build a risk scorecard to flag the riskiest claims so that claim managers can focus on these claims and build strategies to mitigate it
- Organize the claims data better to understand the customer journey through the entire lifecycle
- Predicting the expected number of claims for a year or quarter
The use case I would describe in this blog is to predict the expected number of claims in a year for a particular vehicle. Once you indicate the claims, you can also flag them from less risky to most risky.
This can also be used in other industries, and there is no need to limit it to the automobile industry.
Data Pre-processing
To produce accurate predictions, you must procure data from multiple sources and perform feature engineering and data wrangling to create your final input. Below is the list of attributes/datasets that you might need to begin the modeling process:
- Policy Details(Number, Date, Tenure, etc.)
- Premium and Loss Information(Premium Amount, Losses, etc. )
- Vehicle Information(Number, description, Year of Make, location information, Business Use, etc.)
- Historical Claim Information(Number of Claims, Reason Code, etc.)
Optional Attributes:
- Census Information( Population of the area, Income, etc. )
- Driver Information
Also, it is recommended to have a good history(maybe 4 to 5 years) as such datasets tend to be sparse.
It is also important to divide your dataset into train, test, and holdout at this point. You will build the model on training data, tune your hyperparameters on test data and perform model validation on holdout data.
We will start with a simple model like Decision Tree and then progress towards more complex algorithms like Gradient Boosting Model.
Modeling
- Decision Trees
Decision trees are a simple yet widely used algorithm for classification. For our use case, we will use Decision Trees Regressor. Decision Trees leverage binary rules to arrive at a decision(target value). It uses MSE(Mean Squared Error) to decide to split the node into one or more sub-nodes. It chooses the values with the lowest MSE. The final predictions made by the decision tree are the average values of the dependent variable(number of claims) in that leaf/terminal node.
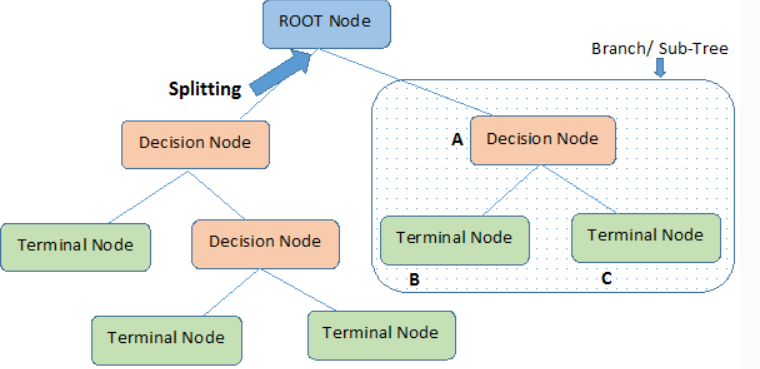
Important Parameters
The model can be easily implemented in R or Python using sklearn. Some of the parameters are as follows:
- Criterion: function to measure the quality of split(mean squared error for our use case)
- Maximum Features: Number of features to use for the best split
- Learning Rate: how much the contribution of each tree will shrink
- Maximum Depth: Maximum depth of the individual regression estimators. The maximum depth limits the number of nodes in the tree.
Advantages
- Easy to understand
- Less Data Preparation required
Disadvantages
- Overfitting
- Unstable(slight variations in data can lead to entirely different results)
- Less accurate for continuous variables
2. Gradient Boosting Models
It is based on the idea that multiple weak learners combine to form a strong learner. The goal of the algorithm is to reduce the error at each step. When the target variable is continuous(like in our use case), we will use Gradient Boosting Regressor. Since the objective here is to reduce the loss function, the loss function used here will be MSE(Mean Squared Error). In simple terms, the loss function would be based on the error between the actual and predicted number of claims.
Important Parameters and Hyperparameter tuning
The model can be easily implemented in R or Python. Some of the attributes are as follows:
- Loss Function
- Learning Rate: how much the contribution of each tree will shrink
- Number of Estimators: The number of boosting stages to perform. Gradient boosting is relatively robust to over-fitting, so a large number usually results in better performance.
- Maximum Depth: Maximum depth of the individual regression estimators. The maximum depth limits the number of nodes in the tree.
An essential feature in the GBM modeling is the Variable Importance. You can achieve this by using the summary function to the output. The table and plot generated as part of this would provide the most critical variables in the training set or the ones that led to the decision-making process.
Since the GBM tends to overfit, it is essential to perform hyperparameter tuning. This is typically achieved on your test set. This would give you the ideal number for each parameter that should be specified in your model before it starts to overfit. It avoids overfitting by attempting to select the inflection point where performance on the test dataset starts to decrease. In contrast, performance on the training dataset continues to increase as the model starts to overfit.
You can test your model’s performance by computing MSE(Mean Squared Error) or RMSE on your train, test and hold out data and compare the results.
Advantages
- Treats missing values
- Better Model Performance
- Provides flexibility with hyperparameter tuning
Disadvantages
- Prone to overfitting
- Computationally expensive
I hope this helps you understand how ML algorithms can come to your rescue to predict claims and mitigate losses.
Thank you to all my followers and readers. I hope you enjoy the AI at rescue series.
Please subscribe and follow for more such content 🙂
References
- The Expanding Use of Predictive Analytics in Claims Management | Gen Re
- Insurance Claim Prediction Using Machine Learning Ensemble Classifier
- Predicting auto insurance claims with deep learning
- Gradient Boosting Algorithm: A Complete Guide for Beginners
- Understanding Gradient Boosting Machines
- A Gentle Introduction to the Gradient Boosting Algorithm for Machine Learning – Machine Learning Mastery
- Gradient Boosting | Hyperparameter Tuning Python
- sklearn.ensemble.GradientBoostingRegressor
- Gradient Boosting Machines
- Decision Tree Regressor explained in depth
- sklearn.tree.DecisionTreeRegressor
AI at Rescue: Claims Prediction was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






