



Active Learning with Autogluon
Last Updated on July 17, 2023 by Editorial Team
Author(s): Ulyana Tkachenko
Originally published on Towards AI.
Train accurate models with minimal data labeling via Active Learning and AutoML
Training supervised machine learning models with large amounts of data can be expensive, time-consuming, and oftentimes unnecessary effort. Comparable results can be achieved with smaller sets of data, if you thoughtfully decide which datapoints to label. One popular class of techniques to decide what data to label in order to train the best model is called active learning.
Active learning utilizes an already trained model to help you decide which batch of additional data will be best to collect labels for under a fixed labeling budget. To obtain a good model with limited data labeling, we train an initial model on a small initial labeled training dataset, and then iterate the following steps: active learning to decide which data is most informative to label next (based on our current model), collect labels for this data and add them to our training dataset, re-train our model on all the data labeled thus far.
By selecting the most informative samples for labeling over multiple rounds, active learning can improve the model’s accuracy and reduce the overall labeling cost to train a model that achieves a particular accuracy.
In this article, I’ll demonstrate how to implement active learning with any image classification dataset using open-source Python tools: an AutoML package from Amazon called AutoGluon, and a recently published active learning algorithm called ActiveLab. If you want to jump straight to the implementation, check out my code here.
How does Active Learning work?
In Active Learning, a model is trained on a small, initial subset of labeled data. The trained model is then given all the unlabeled data points from which it actively selects which additional data points should be added to the labeled group. The model is then retrained on these additional labels and the process repeats until a large enough group is created. The size of the final training dataset is usually a lot smaller than if these same additional labels were selected randomly.
There are different strategies that a model can use to select additional data points for labeling during active learning. The most basic approach is to just randomly choose which data to label next. Another common approach is uncertainty sampling, which selects examples that the model is most uncertain about or has the lowest confidence in its predictions. ActiveLab is an advanced variant of such uncertainty sampling, which has been shown to train better classifiers than other popular active learning methods via extensive benchmarks.
AutoML with AutoGluon
AutoGluon is an open-source automated machine-learning library developed by Amazon that aims to simplify the process of building machine-learning models. It automates many aspects of the machine learning pipeline, such as transfer learning, feature engineering, model selection, and hyperparameter tuning, which can be time-consuming and require advanced expertise. Both AutoGluon and ActiveLab can be used not only for images, but other data modalities like text or tabular data as well. Thus you can use the same pipeline demonstrated here to efficiently label many types of data!
Experiment
For my experiment, I used the caltech256 dataset, which is a classification dataset of 256 different classes, each with roughly ~80 images per class and one background class. I began by splitting the data into a train-test split where df_train was used in the active learning experiment and df_test as kept as held-out data used only for reporting model performance after every active learning round.
The dataset object can be any dataset in the format labels, image_path that AutoGluon requires and a train-test split is only necessary if you are trying to report performance results.
Select initially labeled dataset
Select a small labeled dataset to start that is representative of the data you want to classify or predict. In my code, I choose to start with 8 samples randomly selected from each class.
Train the model on labeled data & obtain predicted class probabilities for the unlabeled data
I then train an AutoGluon model on the initially labeled dataset df_labeled and have it predict on the still unlabeled train data, df_unlabeled.
The full training code for the model is available here.
Obtain active learning scores
I then use the ActiveLab function get_active_learning_scores (from the cleanlab library) as my active learning strategy to compute active learning scores for the labeled and unlabeled data.
Select more samples for labeling.
Then I select a subset of the unlabeled data based on the lowest model confidence and my batch size and add the newly labeled samples to the training set to set up for the next round.
Repeat
I repeat the process above by retraining the model on the expanded labeled data until the desired level of performance is achieved. The final pseudocode loop is written out below, or check out the full example notebook for more details and complete code.
Results
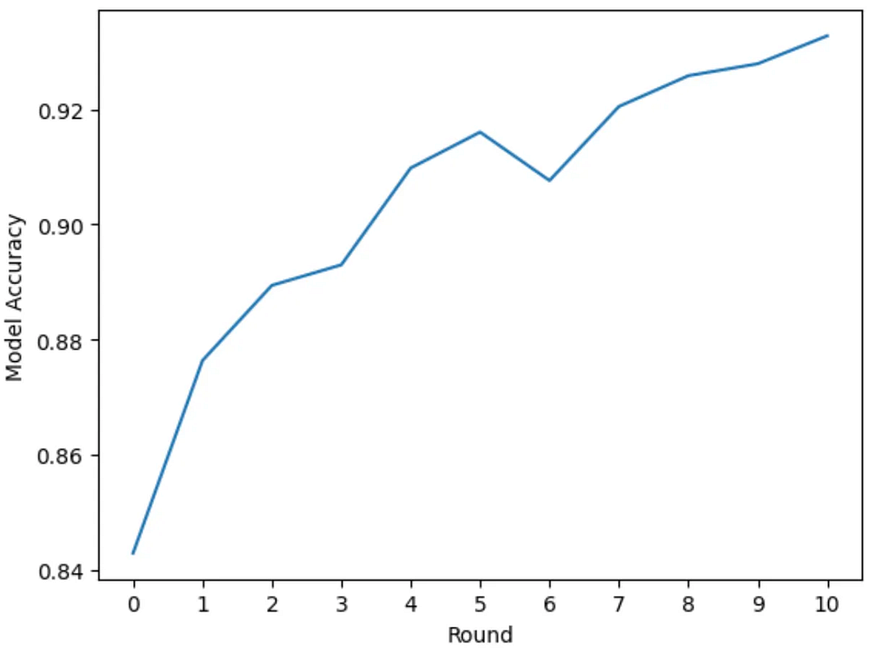
During each round, after selecting new samples, a model was trained on the current round’s labeled data and it’s accuracy was measured on the holdout df_test set for that round. In this example, the steps above were repeated for 10 rounds, adding 150 examples per round with the accuracy shown below.
As you can see, the accuracy of the model improves nicely over each successive round as more data are labeled.
Resources
- Code you can use to reproduce the steps from this article to efficiently label any image classification dataset via active learning: https://colab.research.google.com/github/cleanlab/examples/blob/master/active_learning_single_annotator/active_learning_single_annotator.ipynb
- Tutorial on how to use ActiveLab for active learning with data re-labeling when multiple data annotators are available: https://github.com/cleanlab/examples/blob/master/active_learning_multiannotator/active_learning.ipynb
- Tutorials on how to use AutoGluon for image classification and other supervised learning tasks: https://auto.gluon.ai/
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

