



6 Types of AI Bias Everyone Should Know
Last Updated on October 8, 2021 by Editorial Team
Author(s): Ed Shee
Fairness
In my previous blog, we looked at the difference between Bias, Fairness, and Explainability in AI. I included a high-level view of what Bias is but this time we’ll go into more detail.
Bias appears in machine learning in lots of different forms. The important thing to consider is that training a machine learning model is a lot like bringing up a child.
When a child develops, they use senses like hearing, vision and touch to learn from the world around them. Their understanding of the world, their opinions, and the decisions they end up making are all heavily influenced by their upbringing. For example, a child that grows up and lives in a sexist community may never realise there is anything biased about the way they view different genders. Machine learning models are exactly the same. Instead of using senses as inputs, they use data — data that *we* give them! This is why it’s so important to try and avoid bias in the data used for training machine learning models. Let’s take a closer look at some of the most common forms of bias in machine learning:
Historical Bias
While gathering data for training a machine learning algorithm, grabbing historical data is almost always the easiest place to start. If we’re not careful, however, it’s very easy to include bias that was present in the historical data.
Take Amazon, for example; In 2014 they set out to build a system for automatically screening job applicants. The idea was to just feed the system hundreds of CVs and have the top candidates picked out automatically. The system was trained on 10 years worth of job applications and their outcomes. The problem? Most employees at Amazon were male (particularly in technical roles). The algorithm learned that, because there were more men than women at Amazon, men were more suitable candidates and actively discriminated against non-male applications. By 2015 the whole project had to be scrapped.
Sample Bias
Sample bias happens when your training data does not accurately reflect the makeup of the real world usage of your model. Usually one population is either heavily overrepresented or underrepresented.
I recently saw a talk from David Keene and he gave a really good example of sample bias.
When training a speech-to-text system, you need lots of audio clips together with their corresponding transcriptions. Where better to get lots of this data than audiobooks? What could be wrong with that approach?
Well, it turns out that the vast majority of audiobooks are narrated by well educated, middle aged, white men. Unsurprisingly, speech recognition software trained using this approach underperforms when the user is from a different socio-economic or ethnic background.
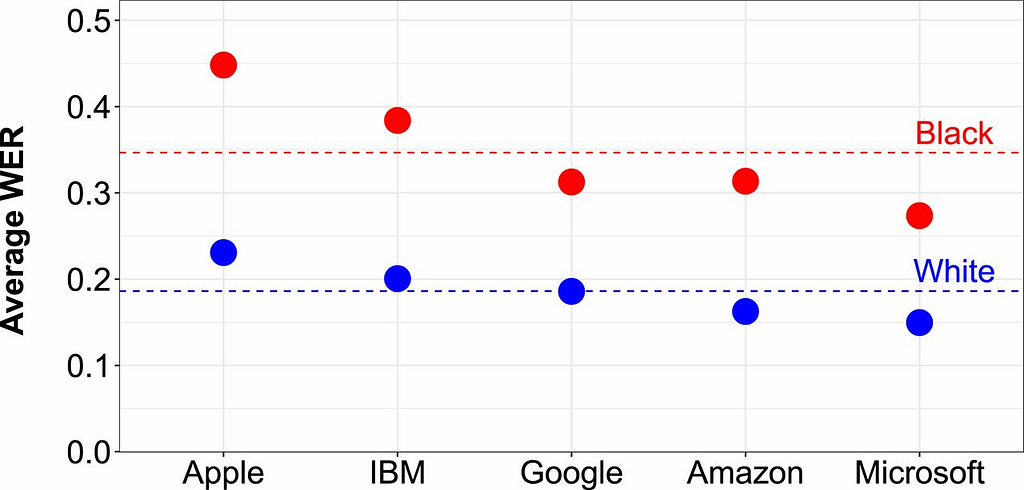
The chart above shows the word error rate [WER] for speech recognition systems from big tech companies. You can clearly see that all of the algorithms underperform for black voices vs white ones.
Label Bias
A lot of the data required to train ML algorithms needs to be labelled before it is useful. You actually do this yourself quite a lot when you log in to websites. Been asked to identify the squares that contain traffic lights? You’re actually confirming a set of labels for that image to help train visual recognition models. The way in which we label data, however, varies a lot and inconsistencies in labelling can introduce bias into the system.

Imagine you train a system by labeling lions using the boxes on the images above. You then show your system this image:

Annoyingly, it is unable to identify the very obvious lion in the picture. By labeling faces only, you’ve inadvertently made the system bias toward front-facing lion pictures!
Aggregation Bias
Sometimes we aggregate data to simplify it, or present it in a particular fashion. This can lead to bias regardless of whether it happens before or after creating our model. Take a look at this chart, for example:
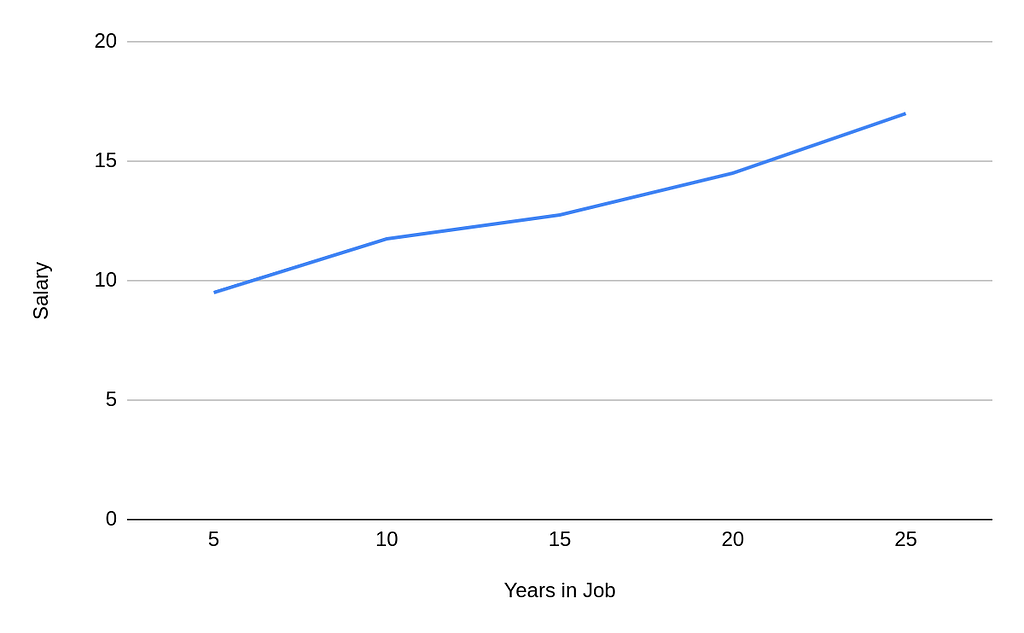
It shows how salary increases based on the number of years worked in a job. There’s a pretty strong correlation here that the longer you work, the more you get paid. Let’s now look at the data that was used to create this aggregate though:
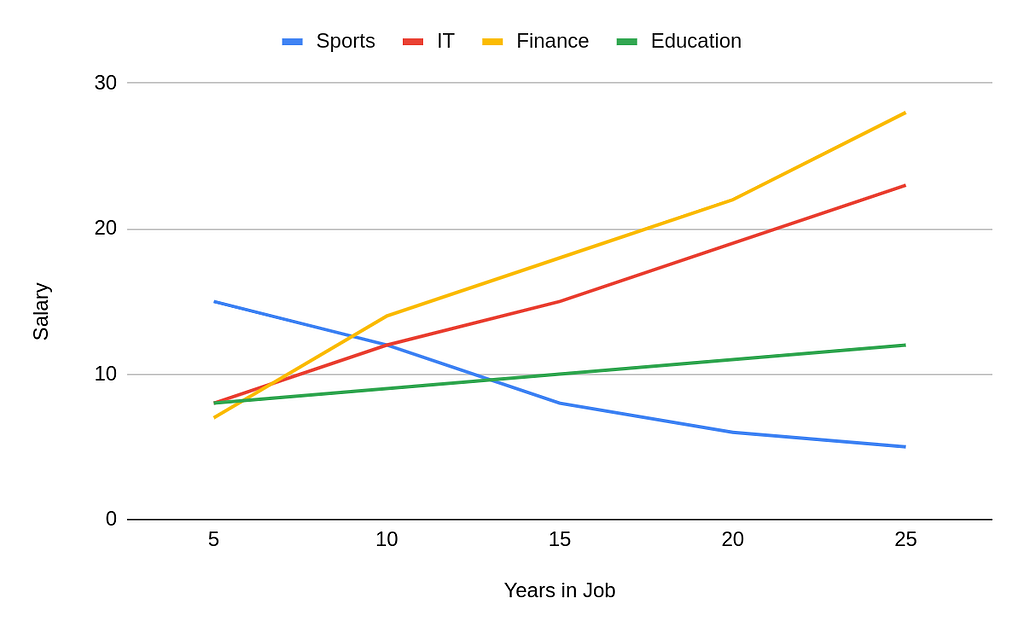
We see that for athletes the complete opposite is true. They are able to earn high salaries early on in their careers while they are still at their physical peak but it then drops off as they stop competing. By aggregating them with other professions we’re making our algorithm biased against them.
Confirmation Bias
Simply put, confirmation bias is our tendency to trust information that confirms our existing beliefs or discard information that doesn’t. Theoretically, I could build the most accurate ML system ever, without bias in either the data or the modelling, but if you’re going to change the result based on your own “gut feel”, then it doesn’t matter.
Confirmation bias is particularly prevalent in applications of machine learning where human review is required before any action is taken. The use of AI in healthcare has seen doctors be dismissive of algorithmic diagnosis because it doesn’t match their own experience or understanding. Often when investigated, it turns out that the doctors haven’t read the most recent research literature which points to slightly different symptoms, techniques or diagnosis outcomes. Ultimately, there are only so many research journals that one doctor can read (particularly while saving lives full-time) but an ML system can ingest them all.
Evaluation Bias

Let’s imagine you’re building a machine learning model to predict voting turnout across the country during a general election. You’re hoping that, by taking a series of features like age, profession, income and political alignment, you can accurately predict whether someone will vote or not. You build your model, use your local election to test it out, and are really pleased by your results. It seems you can correctly predict whether someone will vote or not 95% of the time.
As the general election rolls around, you are suddenly very disappointed. The model you spent ages designing and testing was only correct 55% of the time — performing only marginally better than a random guess. The poor results are an example of evaluation bias. By only evaluating your model on people in your local area, you have inadvertently designed a system that only works well for them. Other areas of the country, with totally different voting patterns, haven’t been properly accounted for, even if they were included in your initial training data.
Conclusion
You’ve now seen six different ways that bias can impact machine learning. Whilst it’s not an exhaustive list, it should give you a good understanding of the most common ways in which ML systems end up becoming biased. If you’re interested in reading further, I’d recommend this paper from Mehrabi et al.
6 Types of AI Bias Everyone Should Know was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

