



10 Research Papers You Shouldn’t Miss
Last Updated on November 4, 2022 by Editorial Team
Author(s): Sergi Castella i Sapé
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Trends in AI — November 2022
Argo.AI shutdown, Jasper.AI, and Stability.AI get massive funding, FLAN-T5 LLM, Neural Audio Compression from Meta, You-only-live-once, Dreamfusion, the new MTEB benchmark for sentence embeddings, Imitation Learning for Urban Driving, and much, much more.
With the biggest AI research conference (NeurIPS 2022) on the horizon, we enter the home stretch of the year 2022. We’re properly excited to go back to an in-person NeurIPS conference a month from now, but first, let’s review what’s happened recently in the world of AI. Let’s start highlighting some news and code releases!
🗞 News
- Jasper.ai — an AI content generation platform — raises $125 million at a $1.5B valuation. Especially since GPT-3 two years ago, AIs for content creation (text, images…) are on the rise, and investors keep betting on it. On a similar line, Stability AI — the startup behind the famous text-to-image model Stable Diffusion — raised $101 million at a $1B valuation.
- On the flip side, many autonomous driving initiatives have failed to deliver on their grand promise of full autonomy in just a few years, and big players are giving up on the race. Argo.AI — the autonomous driving company once valued at $7B and owned by the giant's Ford and Volkswagen — is shutting down.
- The US-China trade war around key silicon technology bumps up the temperature as the US announces more strict bans on exporting high-tech chip designs and manufacturing equipment.
👾 Code
- Kernl is an inference engine written in OpenAI’s Triton to accelerate inference of Transformers.
- DiffDock: Implementation of DiffDock: Diffusion Steps, Twists, and Turns for Molecular Docking. A molecular docking technique that uses diffusion, quickly gaining traction.
- img-to-music: A model that imagines how images sound like!
🔬 Research
Every month we analyze the most recent research literature and select a varied set of 10 papers you should know of. This month we’re covering topics such as Reinforcement Learning (RL), Diffusion Models, Autonomous Driving, Language Models, and more.
1. Scaling Instruction-Finetuned Language Models
By Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay et al.
❓ Why → A year ago, Google’s FLAN¹ showed how to improve the generalizability of Language Models (LMs) by reformulating labeled NLP examples as natural language instructions and including them in the pretraining corpus. Now we get to know what it’s like to scale up that technique.
💡 Key insights → One of the foundational constraints from OpenAI’s famous GPT LMs series is the training on unlabeled data. But that doesn’t mean that autoregressive LMs cannot be trained using labeled data: annotations can be injected into the training of the model without any architecture change. The key idea is to — instead of having classification heads to output labels for an input — reformulate labeled examples as instructions written in natural language. For instance, a labeled example of sentiment classification can be converted into a statement with the following template:
The film had a terrific plot and magnific acting. [POSITIVE]
The film [is good/bad because it] had a terrific plot and magnific acting.
Big caveat: to compare zero-shot performance with fully self-supervised models such as GPT-3, one must make sure that the tasks used in the evaluation are not included in the training instructions!
The original FLAN paper showed the power of this technique on 137B params model, with a maximum of 30k extra instructions from a few dozen NLP tasks. In this paper, they go to the next level by scaling (1) the number of tasks up to 1836, (2) the model size up to 540B parameters, and (3) adding chain-of-thought prompting.
The results show that adding instructions bumps performance, particularly for smaller models, but the raw model scale is still the biggest factor.
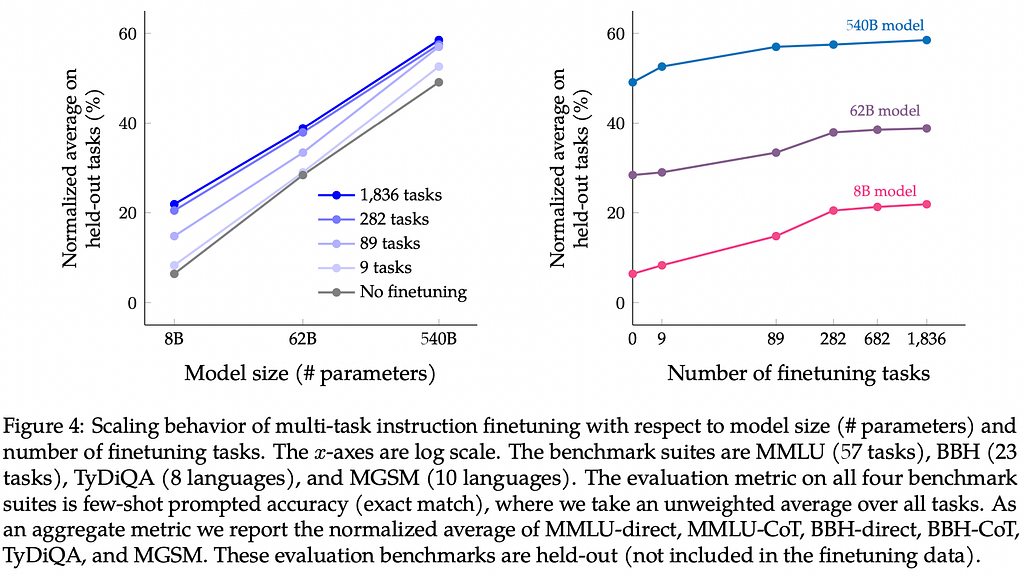
The full models are publicly released on Google’s Research Github Repository.
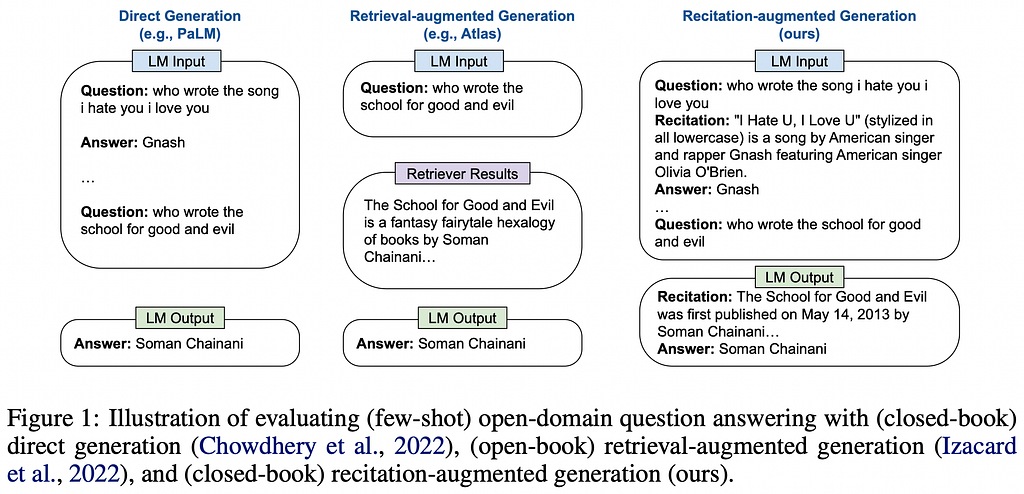
2. Recitation-Augmented Language Models
By Zhiqing Sun, Xuezhi Wang, Yi Tay, Yiming Yang, and Denny Zhou.
❓ Why → Clever prompting techniques continue to expand on the power of pretrained Language Models without the need for new complicated modeling techniques.
💡 Key insights → Retrieval Augmented Language Models³ often retrieve passages from a corpus and append them to the prompt as text, allowing them to access memory explicitly. This makes them much more efficient and factually correct but at the cost of adding substantial complexity to their training and implementation.
RECITE is a new spin on the Language Model prompting, where the prompting template nudges the model to recite from memory a relevant passage from its training corpus before generating an answer. By providing examples in the prompt containing passages from the training corpus, the model will often correctly recite exact passages from it.
This method leverages the spookily good memorization capabilities of large LMs to boost performance in question answering without the need for explicit retrieval from a corpus. In a similar tradition as previous off-the-shelf advanced prompting techniques like chain-of-thought².
An important caveat applies though! This method doesn’t do wonders just like that out of the box. For it to work well, it often requires multiple path decoding⁴, which consists of sampling multiple completion given a prompt (e.g., 20) and then choose an answer based on majority votes, and sampling more paths often results in better performance with the downside of a much higher inference cost.
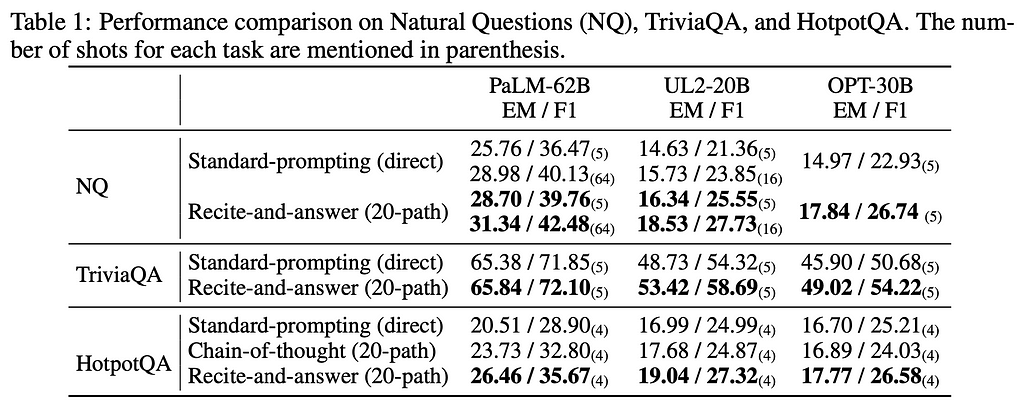
If you’re interested in Language Models, you’ll also like this follow-up work on chain-of-thought prompting: Large Language Models Can Self-Improve.
3. Toward Next-Generation Artificial Intelligence: Catalyzing the NeuroAI Revolution
By Anthony Zador and 26 other renowned researchers in AI and Neuroscience.
❓ Why → The founding figures of AI, such as Turin or Minsky, were driven by a strong curiosity about how brains work and how they can be replicated by machines. In contrast, modern ML practitioners are mostly inclined to think as Computer Scientists, Logicians, and Statisticians, disconnected from research on how the brain works. Would the field benefit from tighter collaboration? Many high-profile figures in AI and Neuroscience think so.
💡 Key insights → The idea that a better understanding of the brain will provide insight into how to build intelligent machines is not new. Human brains and AI have been intertwined since the very beginning.
The position paper highlights existing challenges in artificially intelligent agents, especially when it comes to interacting with the world in a sensible way. While language is often portrayed as the pinnacle of human intelligence, learning human-level sensory motor skills is far from a solved task, whereas progress in natural language generation has been stunning to the point where some would consider the original Turing test to be solved.
The fundamental tenet of this manifesto is succinctly stated:
… a better understanding of neural computation will reveal basic ingredients of intelligence and catalyze the next revolution in AI.
As a response to this challenge, the authors propose the embodied Turing test as the successor to the original Turing test: a more holistic test that includes evaluating sensory motor skills besides explicit reasoning abilities.
The roadmap to solve the next-generation Turing test relies on 3 main pillars. (1) An AI curriculum that places equal emphasis on both camps such that a new generation of AI researchers is as with Computer Science as they are with Neuroscience, (2) a shared platform to test agents, and (3) increased funding for fundamental theoretical research on neural computation.
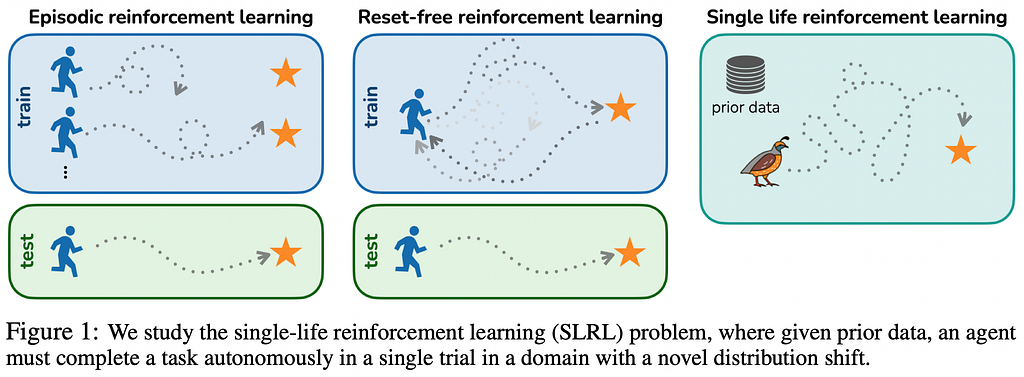
4. You Only Live Once: Single-Life Reinforcement Learning
By Annie S. Chen, Archit Sharma, Sergey Levine, and Chelsea Finn.
❓ Why → Can agents adapt to a new environment on the fly when deployed? Episodic Reinforcement Learning is not a suitable framework for problems that require agents to perform well in unseen environments.
💡 Key insights → In this work, the authors lay down the formalism for single-life reinforcement learning, a paradigm in which agents are tested in unseen environments. The goal then is to solve the task once without getting stuck instead of learning a policy for that environment, as one would do in traditional RL.
The authors also propose a new algorithm, Q-weighted adversarial learning (QWALE), which uses “distribution matching” to leverage previous experience as guidance in novel situations. Of course, their method amply outperforms the baselines, but as with most paradigm-challenging works, it’s unclear to what degree the choice of the evaluation was tailored to the specific model being proposed.
In any case, this RL paradigm has interesting parallels with zero-shot learning and generalization, which are areas gaining traction in ML, as the brittleness of the good-old supervised learning techniques has been uncovered. Will single-shot RL take off as a new must-include evaluation regime in RL papers? We hope so!
5. Model-Based Imitation Learning for Urban Driving | Code | Blog Post
By Anthony Hu, Gianluca Corrado, Nicolas Griffiths, Zak Murez, Corina Gurau, Hudson Yeo, Alex Kendall, Roberto Cipolla, and Jamie Shotton.
❓ Why → A leap in autonomous driving performance (well, in a simulated environment!)
💡 Key insights → Learning online from interactions with the world vs. learning offline from demonstrations (imitation learning) is one of the most basic divides in RL. Broadly speaking, the former is robust but inefficient, and the latter is efficient but brittle.
This paper advances the state-of-the-art on using Imitation Learning for autonomous driving on the CARLA⁵ simulator. Advances in Imitation Learning are particularly useful because they translate better to physical world situations. Learning a driving policy online learning in the real world would often be too dangerous and expensive. Nobody wants to buy a new car for every episode reset!
The model proposed here (MILE) learns the world dynamics in latent space by trying to infer what latent features resulted in the expert observations provided in training. You can find an overview of how the model works in the figure below.
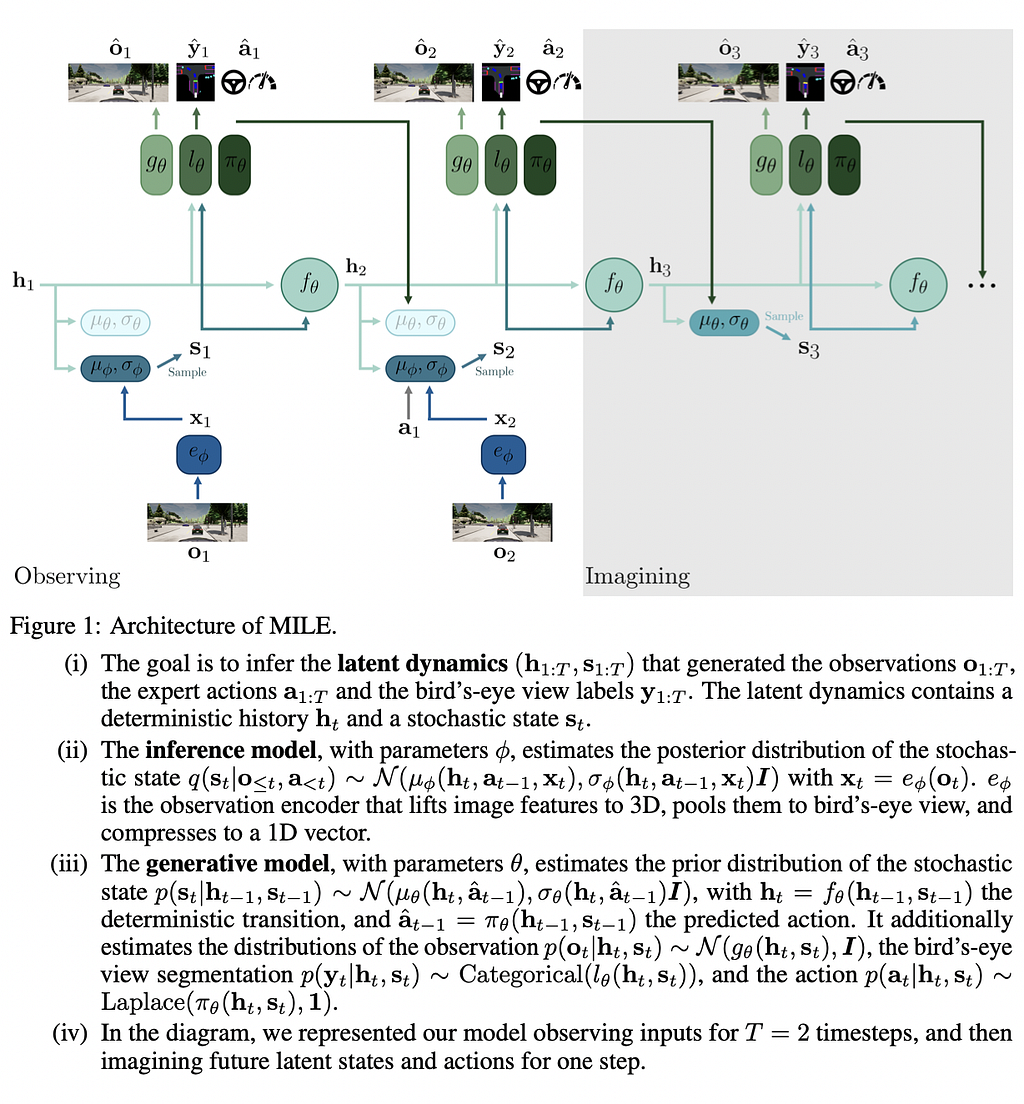
When it comes to results, MILE shines especially in out-of-domain evaluation: unseen towns and unseen weather conditions.
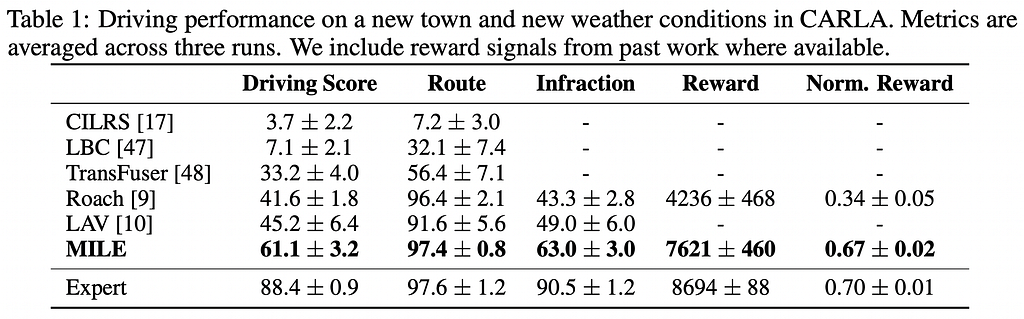
6. DreamFusion: Text-to-3D using 2D Diffusion | Project Page | Unofficial Implementation (Stable DreamFusion)
By Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall.
❓ Why → The meteoric rise of Diffusion Models continues beyond a plain text-to-image generation.
💡 Key insights → 3D generation is hard (among other challenges) because there are not that many 3D models out there to train an end-to-end 3D generator on, unlike with 2D images. In this work, they circumvent this limitation by leveraging the power of existing 2D image generators to bootstrap the generation of 3D assets.
The key ingredient is Score Distillation Sampling (SDS). This method enables transforming the output of a 2D text-to-image model to any parameter space — such as a 3D model — as long as the transformation is differentiable. To synthesize a scene from text, this method initializes a NeRF model randomly and repeatedly renders views for that NeRF from different camera positions and angles and then uses those renderings as inputs to the Diffusion Model + score distillation loss that is backpropagated through the NeRF. Initially, these views look like noise, but with enough diffusion optimization timesteps, they end up properly representing views of a 3D object.
Several tricks and regularizations are required to make the setup work, but the results are attention-grabbing, as you can check on their project page. You can also play with an unofficial open-source implementation powered by the also open-source text-to-image Stable Diffusion.
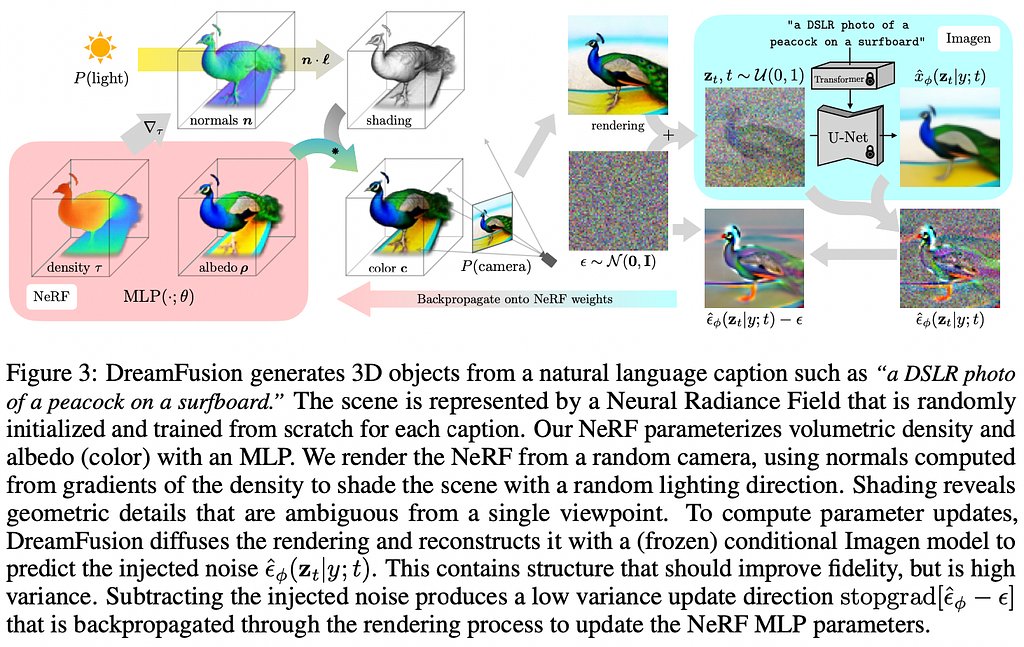
7. Imagic: Text-Based Real Image Editing with Diffusion Models
By Bahjat Kawar, Shiran Zada, Oran Lang, Omer Tov, Huiwen Chang, Tali Dekel, Inbar Mosseri, Michal Irani.
❓ Why → Image editing with diffusion models just got (even) better!
💡 Key insights → Staying on the topic of Diffusion Models, one of the strong applications of such models has been image editing constrained to a specific edit type, such as conditional inpainting or style transfer. This work demonstrates the ability to apply unconstrained, complex, semantically relevant, text-guided edits to images.

The technique relies on interpolating in the embedding space between the input and target images. Firstly (A), they align the text and image embeddings such that similar embeddings produce similar image generations given a frozen Pretrained Diffusion Model. Then (B) the Diffusion Model is finetuned on the aligned embedding, and finally, © the target and aligned embedding are interpolated and used to generate the edited image.
8. GoalsEye: Learning High-Speed Precision Table Tennis on a Physical Robot | Project Page
By Tianli Ding, Laura Graesser, Saminda Abeyruwan, David B. D’Ambrosio, Anish Shankar, Pierre Sermanet, Pannag R. Sanketi, Corey Lynch.
❓ Why → Another showcase of Imitation Learning and its power to transfer great performance onto physical robots.
💡 Key insights → Still in 2022, one of the biggest challenges of RL systems is to make them work in the real world instead of in simulated environments. This is especially relevant — as we just mentioned in the context of autonomous driving vehicles — because online learning in RL is normally not feasible in the physical world: it’s still sample inefficient, and too many things would break too many times.
This paper shows how to teach a robot to play tennis using iterative supervised Imitation Learning, i.e., combining self-play with goal-oriented behavior cloning. The keys to success are to (1) start with a non-goal-directed bootstrap dataset of demonstrations of the robot just hitting the ball to overcome the inefficient initial exploration phase. (2) Hindsight relabeled goal-conditioned behavioral cloning (e.g., keeping a log of how the ball was hit and where it landed, then using it as a target). (3) Goal-directed iterative self-supervised play to hit targets.
Check out their project page to see all the video demonstrations of how their robot works!

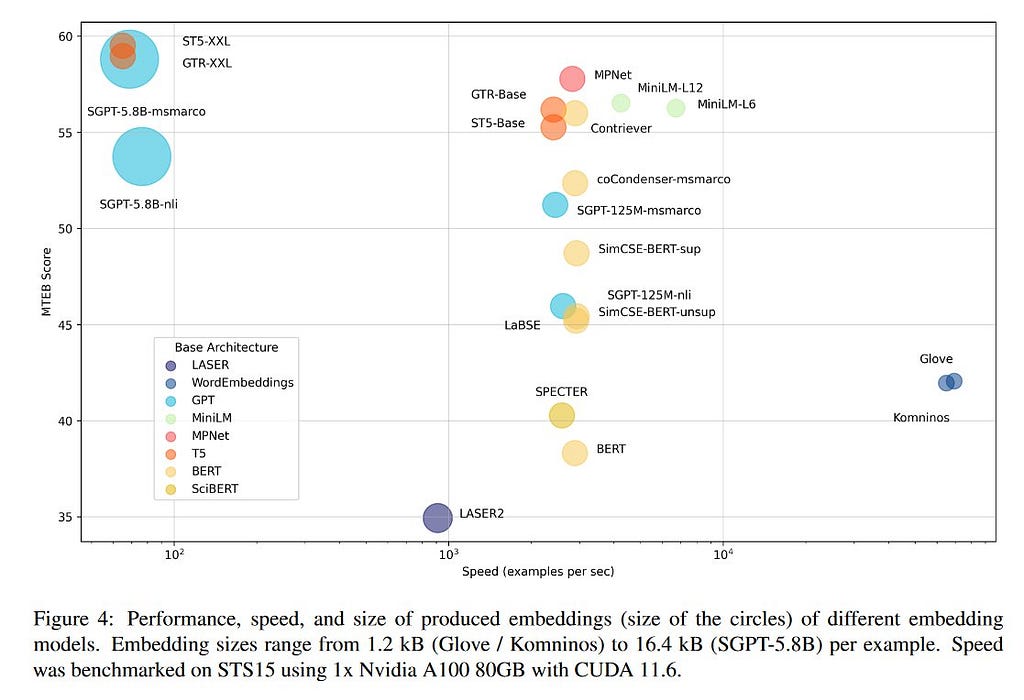
9. MTEB: Massive Text Embedding Benchmark | Code | Leaderboard
By Niklas Muennighoff, Nouamane Tazi, Loïc Magne, and Nils Reimers.
❓ Why → With the amount of off-the-shelf NLP embedding models available nowadays, choosing among them has become a challenge. This work facilitates the process.
💡 Key insights → One of the main reasons why generic language embeddings are extremely popular is their convenience: after converting text into vectors, performing NLP tasks like classification, semantic similarity, retrieval, or clustering, among others, becomes easy. But the promise of having one embedding to rule them all is still far from a reality, which is why benchmarking on a variety of tasks is key to finding the best model for generic use cases.
This benchmark consists of 8 embedding tasks covering a total of 56 datasets and 112 languages and is built with 4 fundamentals in mind:
- Diversity (8 tasks): classification, clustering, pair classification, reranking, retrieval, semantic textual similarity, and summarization.
- Simplicity: the benchmark is accessible via a plug-and-play API.
- Extensibility: there’s a specified syntax and procedure to easily add new datasets to the existing benchmark through the HuggingFace hub.
- Reproducibility: versioning is a built-in feature of the distribution of this benchmark, making it possible to re-run any evaluation on any version of the benchmark.
The results show how modern Transformer-based models outperform classics such as GloVe, but also how performance often comes at the cost of speed, which is unacceptable for some applications. You can check the up-to-date results on the HuggingFace leaderboard.
10. High Fidelity Neural Audio Compression | Blog post | Code + models
By Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi.
❓ Why → Compression algorithms are the bread and butter of the internet. After many years of research in Neural codecs, they are properly catching up to the classical robust alternatives not only in quality but in convenience.
💡 Key insights → The method proposed by Meta to compress audio consists of a quantized autoencoder trained on a combination of reconstruction and adversarial losses. The reconstruction loss is both on the raw audio signal as well as on the mel-spectrogram, and the adversarial loss comes from a discriminator that needs to classify whether a compressed representation and the resulting audio correspond to each other. Finally, an extra regularization loss on the quantized representation is used to prevent the quantization to alter the compressed representation excessively.
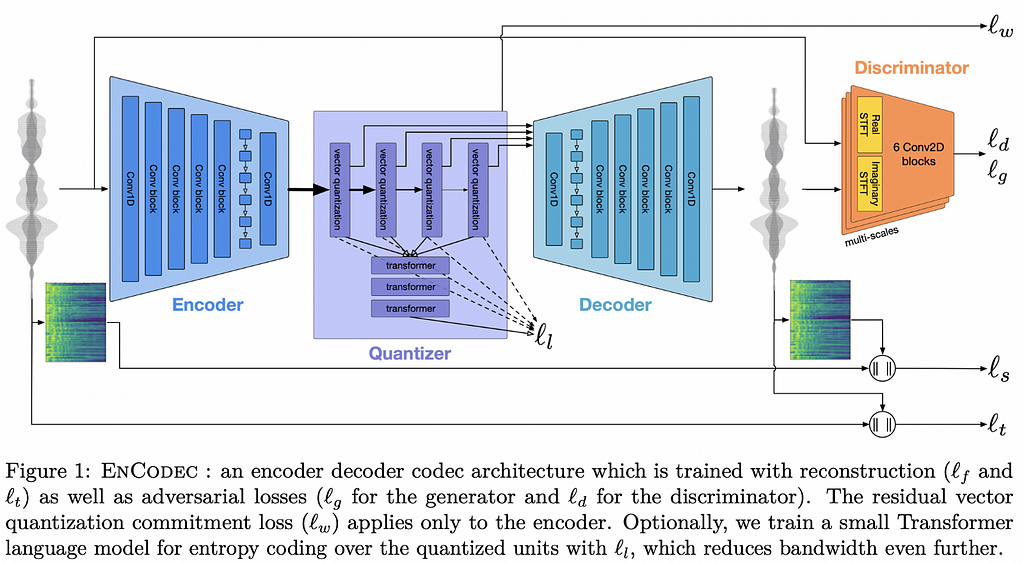
The method described is not particularly novel, but the high optimization and robustness are. The compression gains achieved by this method at a reasonable audio quality are impressive, encoding audio at down to 6kbps, retaining a quality comparable to a 64kbps mp3 codec, while decoding at around 10x real-time factor. You can listen to it yourself in this example.
But performance is not the only variable that matters though when it comes to compression codecs, convenience is where classical codecs are hard to beat. Judging by Meta’s blog post about the research, they believe this is a key enabling technology for their broader company mission involving the Metaverse, so we expect a strong push from the company to soon utilize these models in production.
References:
[1] “Finetuned Language Models Are Zero-Shot Learners” by Jason Wei et al, 2021.
[2] “Chain of Thought Prompting Elicits Reasoning in Large Language Models” by Jason Wei et al, 2022.
[3] “REALM: Retrieval-Augmented Language Model Pre-Training” by Kelvin Guu et al. 2020.
[4] “Self-Consistency Improves Chain of Thought Reasoning in Language Models” by Xuezhi Wang et al. 2022.
10 Research Papers You Shouldn’t Miss was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

