



MLCoPilot: Empowering Large Language Models with Human Intelligence for ML Problem Solving
Last Updated on May 9, 2023 by Editorial Team
Author(s): Sriram Parthasarathy
Originally published on Towards AI.
Solving Machine Learning Tasks with MLCoPilot: Harnessing Human Expertise for Success
Many of us have made use of large language models (LLMs) like ChatGPT to generate not only text and images but also code, including machine learning code. This code can cover a diverse array of tasks, such as creating a KMeans cluster, in which users input their data and ask ChatGPT to generate the relevant code.
In the realm of data science, seasoned professionals often carry out research to comprehend how similar issues have been tackled in the past. They investigate the most suitable algorithms, identify the best weights and hyperparameters, and might even collaborate with fellow data scientists in the community to develop an effective strategy.
But what if LLMs could also engage in a cooperative approach? This is where ML CoPilot enters the scene. Despite their extensive abilities, LLMs do not have the expertise to resolve every existing problem. By supplying various solved machine learning problems as training data, LLMs can acquire and amass knowledge from previous experiences. This allows them to access their knowledge repository when faced with new predictive tasks and choose the most appropriate course of action.
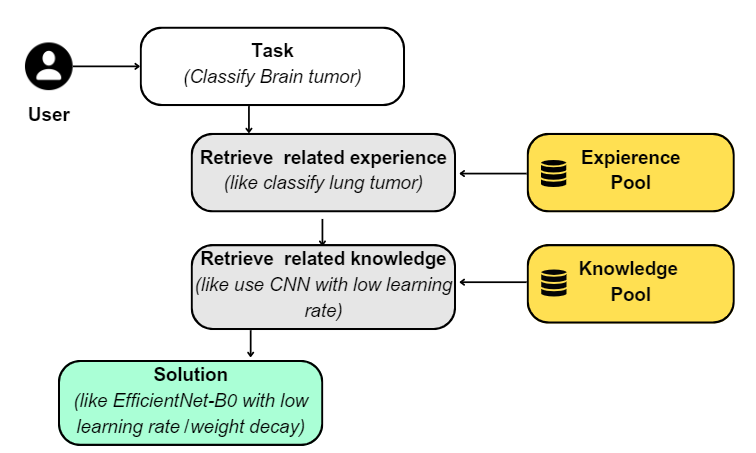
In this paper, the authors suggest the use of LLMs to make use of past ML experiences to suggest solutions for new ML tasks. This is where the utilization of vector databases like Pinecone becomes valuable to store all the past experiences and aids as the memory for LLMs.
Storing past ML insights to guide decision making

ML insights from the past play a crucial role in guiding the large language models (LLMs) to answer future machine learning (ML) tasks. To facilitate this, vector databases like Pinecone come into the picture. These databases store all the necessary knowledge required by the LLMs, essentially serving as their memory. Vector databases are specialized databases designed to efficiently store and retrieve high-dimensional information, such as vectors. They are commonly employed in systems that provide recommendations, find similar images or text, and group similar items together.
When given a query like “classify brain tumor,” the vector database can search for documents or phrases that have similar meanings to the query. It achieves this by comparing the vector representation of the query with the vectors of the stored documents, which encompass past experiences and accumulated knowledge. By identifying the closest matches in semantic space, LLMs can retrieve relevant documents based on their semantic similarity, moving beyond the limitations of keyword matching alone.
For instance, if a brain tumor ML task is presented, the LLM can potentially find a related experience or knowledge related to a lung tumor ML task from the knowledge base. By leveraging the similarities between these tasks, the LLM can access information about the algorithms used, the datasets employed, and other parameters and weights utilized in the previous ML task. This retrieved information then becomes invaluable input for the LLM as it endeavors to solve the new ML task at hand.
By utilizing vector databases to store and retrieve ML insights from the past, LLMs gain access to a vast repository of knowledge. This empowers them to make informed decisions, draw upon established methodologies, and leverage successful solutions that have been previously applied to similar ML tasks. As a result, the LLM’s capabilities are significantly enhanced, enabling it to provide more accurate and efficient solutions to a wide range of ML problems.
Leveraging past knowledge to solve ML tasks
The primary objective of ML CoPilot is to harness both machine intelligence and human knowledge to propose solutions for new machine learning (ML) tasks. Achieving this goal requires ML CoPilot to learn from the past experiences of human practitioners. To accomplish this, the authors of ML CoPilot explored ML benchmarks to extract valuable information, which was then converted into text format for better comprehension by the large language models (LLMs).
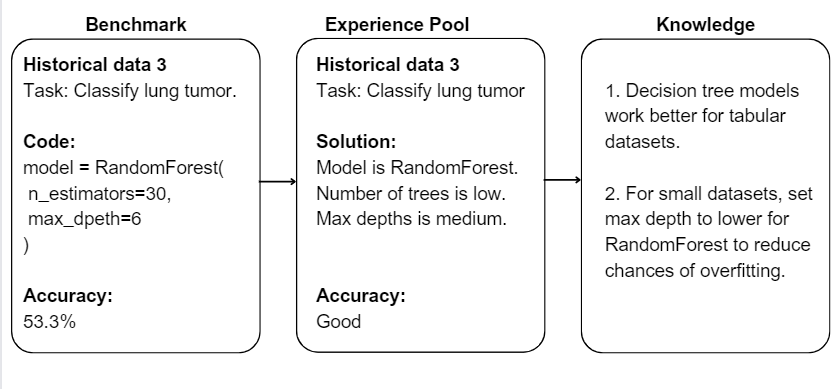
Text format is utilized because LLMs excel in understanding textual data rather than numerical values. Therefore, any information that the LLM needs to read and learn must be converted into a text-based format. This includes converting code into text summaries and transforming accuracy numbers into descriptive categories such as medium, good, and so on. These experiences are aggregated and transformed into knowledge, forming a repository of ML insights.
When a new ML task is presented, ML CoPilot leverages the accumulated experiences and knowledge to suggest the final solution. By drawing upon past ML experiences, ML CoPilot enhances its ability to provide valuable recommendations and guidance for the new task at hand. This collaborative approach effectively combines the strengths of machine intelligence and human expertise, leading to more effective and efficient solutions for novel ML tasks.
The next two sections explore the two steps below.
Step 1: Create an ML knowledge pool from historical ML tasks (from benchmark data)
To facilitate the learning process from previous machine learning (ML) work, three ML benchmarks, namely HPO-B, PD1, and HyperFD, were employed. These benchmarks encompass a wide range of ML tasks and datasets, spanning various scenarios such as tabular data classification and regression, image classification, and object detection. The primary objective is to convert these benchmarks into a knowledge format that can be utilized by large language models (LLMs).
HPO-B-v3, for instance, consists of 16 different sets of solutions for 101 datasets sourced from the OpenML platform. Each set focuses on a specific machine learning algorithm, such as random forest, SVM, or XGBoost. The main goal is to identify the optimal configuration for these algorithms when applied to a particular dataset. By exploring various configurations, the benchmarks aim to discover the best-performing settings for different ML algorithms and datasets.
PD1 Neural Net Tuning Dataset, on the other hand, comprises diverse classification tasks that encompass areas like image classification, next token prediction, and translation. Each task is associated with a specific neural network architecture, such as CNN or transformer. The dataset concentrates on fine-tuning the performance of these neural networks by adjusting the parameters of an SGD optimizer with Nesterov momentum. Through this fine-tuning process, the benchmarks aim to optimize the neural networks for improved performance across different classification tasks.
HyperFD represents a benchmark system designed to enhance the accuracy of a neural face detector on a novel dataset. This is achieved by appropriately adjusting various aspects, including data augmentation, neural architecture, loss function, and training recipe. By optimizing these elements, the benchmarks aim to enhance the performance of the neural network, specifically in the context of face detection tasks.

The purpose of utilizing these ML benchmarks is to extract valuable knowledge from their outcomes and convert it into a format that LLMs can effectively utilize. By capturing the insights and experiences gained from these benchmarks, the LLMs can leverage this knowledge to provide valuable suggestions and solutions for new ML tasks. The benchmarks offer a diverse range of scenarios and datasets, enabling the LLMs to gain a comprehensive understanding of ML challenges and their corresponding solutions.

Step 2: Suggest solutions for ML tasks based on knowledge from the past
When ML CoPilot receives a new task, it searches the experience pool for related tasks. For instance, if the task is to classify a brain tumor, ML CoPilot looks for ML tasks that are related to this domain. One example of a related task could be the classification of lung tumors.
ML CoPilot also explores related knowledge recommendations associated with these tasks. The gathered information is then provided to the large language models (LLMs) and utilized to generate the final solution for the given problem. By leveraging the experiences and knowledge derived from similar ML tasks, ML CoPilot enhances its ability to provide accurate and effective solutions for the new task.

The presence of ML experiences and knowledge is crucial for the proper functioning of this system. Without either of them, or in the absence of both, the reliability of end-to-end predictions diminishes. The availability and incorporation of ML experiences and knowledge serve as the foundation for ML CoPilot to provide accurate and dependable solutions to novel ML tasks.
Conclusion
In conclusion, the collaborative approach of ML CoPilot, which combines the power of large language models (LLMs) with the accumulated knowledge from past machine learning (ML) experiences, offers immense potential in solving novel ML tasks. By leveraging vector databases to store and retrieve insights from ML benchmarks, LLMs can gain access to a wealth of information that guides their decision-making processes.
ML CoPilot serves as a bridge between machine intelligence and human knowledge, incorporating the expertise of experienced practitioners by using established methodologies and successful approaches used in similar ML tasks.
However, the success of this system heavily relies on the availability of ML experiences and knowledge. The absence of either one or both of these components undermines the reliability of end-to-end predictions. Therefore, the continuous accumulation and storage of ML insights become critical in enhancing the effectiveness and dependability of ML CoPilot.
In conclusion, by leveraging past experiences, knowledge, and the expertise of the ML community, ML CoPilot opens up new possibilities and advances the field of machine learning towards more intelligent and effective solutions.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

