



Unlocking New Insights with Vision Transformer
Last Updated on August 1, 2023 by Editorial Team
Author(s): Anay Dongre
Originally published on Towards AI.
The Vision Transformer (ViT) is a state-of-the-art deep learning model designed to process and interpret visual information. It utilizes a novel attention-based approach to identify key features and patterns within images, resulting in highly accurate and efficient image analysis.
Introduction
The Vision Transformer, or ViT for short, is a technology that seems to have been plucked straight out of science fiction. Using the power of deep learning and attention-based processing, the ViT has the ability to analyze and interpret visual information in ways that were once thought impossible.
At its heart, the ViT represents a new approach to computer vision, one that is based on the fundamental principles of human cognition. By leveraging the power of attention, the ViT is able to identify key features and patterns within visual data with incredible accuracy and speed.
But the ViT is more than just a technological advancement. It is a tool that has the potential to transform the way we see and interact with the world around us. From healthcare to transportation to manufacturing, the ViT has the ability to enable more efficient and accurate analysis of visual data, and to unlock new levels of understanding and insight into the world around us.
In many ways, the ViT is a reflection of our ongoing efforts to understand and replicate the remarkable abilities of the human brain. It is a reminder of the remarkable power of attention, and a testament to our ongoing quest to push the boundaries of what is possible.
Background
In recent years, there has been a growing interest in developing new deep learning models for computer vision tasks, with the goal of improving performance and reducing the need for domain-specific engineering. One such model is the Vision Transformer (ViT), proposed by Dosovitskiy et al. (2021), which applies the Transformer architecture originally designed for natural language processing to the task of image classification.
The ViT model builds upon earlier work that explored the use of self-attention mechanisms for image processing. Parmar et al. (2018) proposed using local multi-head dot-product self-attention blocks to replace convolutions in image recognition, while Sparse Transformers (Child et al., 2019) employed scalable approximations to global self-attention. Other researchers have explored the combination of convolutional neural networks (CNNs) with self-attention, such as by augmenting feature maps (Bello et al., 2019) or further processing CNN outputs (Hu et al., 2018; Carion et al., 2020).
Another related model is the image GPT (iGPT) (Chen et al., 2020a), which applies Transformers to image pixels after reducing image resolution and color space. The model is trained in an unsupervised fashion as a generative model and has achieved impressive classification performance on ImageNet.
The ViT model has demonstrated promising results on a variety of computer vision tasks, including image classification, object detection, and segmentation. In addition, other recent works have explored the use of additional data sources and larger datasets to improve performance, such as Mahajan et al. (2018), Touvron et al. (2019), and Xie et al. (2020).
Idea Behind Vision Transformer
Vision Transformers (ViT) work by breaking down an image into smaller patches, which are then fed into a Transformer architecture, similar to the one used in natural language processing. The Transformer is composed of multiple layers of self-attention mechanisms, which allow the model to attend to different parts of the image at different levels of abstraction.
During training, the model is fed a large dataset of images and learns to identify different patterns and features that are common across the dataset. This pre-training process allows the model to develop a strong understanding of visual concepts that can then be fine-tuned for specific image recognition tasks.
When presented with a new image during inference, the model first breaks the image down into patches and feeds them through the pre-trained Transformer. The model then aggregates the information from the different patches and makes a prediction about the content of the image. This process can be repeated for multiple images to perform tasks such as image classification, object detection, and segmentation.
Architecture of Vision Transformer

At a high level, the ViT architecture consists of two main components: an image patch embedding module and a Transformer encoder. The image patch embedding module takes as input an image and divides it into a grid of patches, which are then flattened and passed through a linear projection layer to obtain a set of embeddings. These embeddings are then fed into the Transformer encoder, which processes them to produce a final output that represents the image.
The Transformer encoder itself consists of a stack of identical layers, each of which contains a multi-head self-attention mechanism and a feedforward neural network. The self-attention mechanism allows the model to attend to different parts of the input embeddings, while the feedforward network provides non-linear transformations to the embeddings. The outputs from each layer are then passed to the next layer in the stack.
The ViT architecture is defined by several parameters, including:
- Image size: The size of the input image determines the number of patches that will be extracted from the image. The larger the image size, the more patches will be extracted, resulting in more fine-grained spatial information being captured.
- Patch size: The patch size determines the size of the spatial information captured by each patch. The larger the patch size, the more spatial information will be captured by each patch, but at the cost of increased computational complexity.
- Number of patches: The number of patches extracted from the image is determined by the image size and patch size. The total number of patches is equal to the number of horizontal patches times the number of vertical patches.
- Embedding dimension: The embedding dimension determines the size of the embedding vectors that represent each patch. The embedding dimension is a hyperparameter that can be tuned to optimize model performance.
- Number of attention heads: The number of attention heads determines how many separate attention mechanisms are used in the multi-head attention mechanism. Increasing the number of attention heads can improve the model’s ability to capture fine-grained relationships between patches.
- Number of transformer layers: The number of transformer layers determines the depth of the network. Deeper networks can capture more complex relationships between patches, but at the cost of increased computational complexity.
- Dropout rate: Dropout is a regularization technique used to prevent overfitting. The dropout rate determines the probability that each element in the network will be set to zero during training.
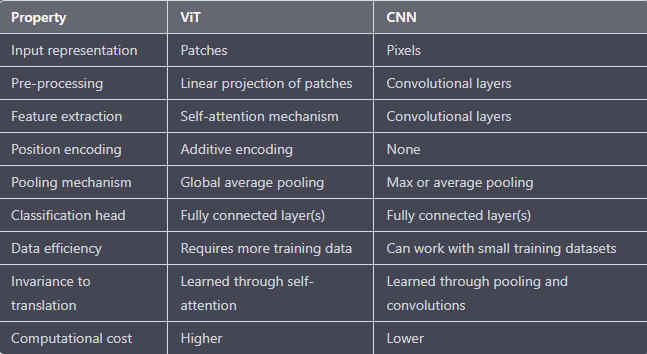
How is ViT different from CNN
How does ViT perform with different dataset ?

Table shows the comparison with state of the art on popular image classification benchmarks.
Conclusion
In conclusion, Vision Transformer (ViT) is a novel architecture for image recognition that replaces convolutional layers with self-attention mechanisms. ViT has shown promising results in various image classification tasks, outperforming the traditional Convolutional Neural Network (CNN) architecture. It has demonstrated its effectiveness on different datasets and has achieved state-of-the-art results on ImageNet.
One of the main advantages of ViT is its ability to learn global features of an image, which can be crucial in some recognition tasks. It also requires less computational resources than traditional CNNs for training, which can be beneficial for practical applications. However, ViT requires a large amount of data to be effective, which can limit its application in certain contexts.
Despite the success of ViT, there is still much research to be done in exploring its full potential and optimizing its architecture for different tasks. It is also important to investigate how ViT can be adapted to handle other types of data, such as video and 3D data.
References
- Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., … & Houlsby, N. (2021). An image is worth 16×16 words: Transformers for image recognition at scale. In International Conference on Learning Representations. https://openreview.net/pdf?id=YicbFdNTTy
- Kolesnikov, A., Beyer, L., Zhai, X., Puigcerver, J., Yung, J., Gelly, S., & Houlsby, N. (2019). Big transfer (bit): General visual representation learning. arXiv preprint arXiv:1912.11370.
- Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems (pp. 1097–1105).
- Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
- He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770–778).
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

