



Introduction to Person Re-Identification
Last Updated on November 5, 2023 by Editorial Team
Author(s): Aditya Mohan
Originally published on Towards AI.
Person re-identification is a process that identifies individuals who appear in different non-overlapping camera views. This process does not rely on facial recognition but instead considers clothing details, body shape features, and other attributes related to appearance.
In this article, I will introduce the concepts, terminologies, challenges, datasets, and methods associated with developing a person ReID system.
Given an image of a person, the goal of ReID is to determine whether this person has been captured earlier by any of the cameras that are part of the system. This image is known as the query image. Sometimes, the query can also be in the form of a video sequence.
What makes Person ReID challenging?
- Occlusions
- Different Viewpoints
- Low image resolutions
- Cluttered backgrounds
- Changes in illumination
- Inaccurate pedestrian detection
- Few training samples for each class
Person ReID is a task that consists of numerous classes (each person is essentially a class) but only few samples for each class are available during training. Therefore, learning representations for a single class from a few samples can be quite difficult. Learning meaningful representations from a few examples per class is called Few-Shot learning.
Some ways of solving this problem include methods like data augmentation to increase samples per class, unsupervised representation learning (CLIP) etc. Read more about dealing with few-shot learning here.
- Cross-domain generalization
It has been observed that ReID models trained on one dataset do not perform well on other datasets. Some techniques have been introduced to address this issue. For instance, unsupervised representation learning-based methods like CLIP can be used to learn better general representations which can be then used to fine-tune the model on different datasets.
Important terminologies in ReID Domain
Person ID: The unique ID assigned to a person in the dataset. This “id” in most applications will get reset every day. We can think of a person ID as the class label used in a traditional classification task.
Camera ID: The unique ID assigned to a given camera in the ReID system
Types of Split
Training/Test Split: The train/test split has the same purpose as any other machine learning task.
Once the model is trained, the gallery and the query help in evaluating the model.
Gallery/Query Split:
The images in the gallery are used by the model to learn the feature representations of individual persons. A gallery can contain multiple images for a single person ID. Please note that the gallery is different from the training set.
The images in the query split consist of the images for testing the model performance on person ID representations learned from the gallery split.
An Overview of a Person ReID System
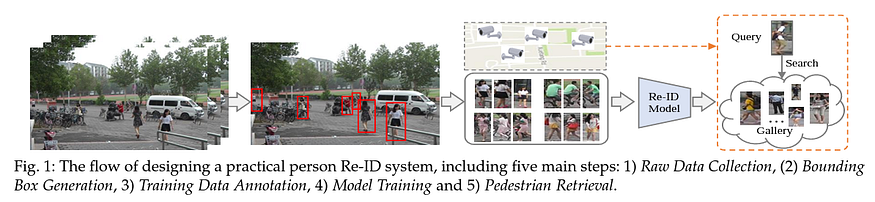
One of the main applications of this process is surveillance. In public spaces like universities, schools, shopping malls, and parking lots, this adds a layer of security to track down perpetrators of illegal activities.
Dataset Preparation
To make datasets more challenging and reflect a real-world distribution, capturing videos at different times of the day is a common practice to account for illumination changes. However, this does not apply to videos captured in indoor setups.
For example, cameras placed outside an airport terminal might collect data with varying illumination due to changes in weather and the time of the day. Whereas cameras inside the airport where the illumination is provided by artificial lighting, the illumination remains mostly constant.
Cameras are usually placed at different angles which adds the complexity of different viewpoints in a dataset. Sometimes, different camera settings also lead to variations in data, which better resembles real-world data.
Some datasets, such as the CUHK-CYSU scrape images from movie scenes in addition to images captured by camera as they mostly contain the same actors in different scenes.
Below is an overview of the famous ReID datasets
CUHK03
The CUHK03 consists of 14,097 images of 1,467 different person identities, where 6 campus cameras were deployed for image collection and each identity is captured by 2 campus cameras. This dataset provides two types of annotations: manually labeled bounding boxes and bounding boxes produced by a pedestrian detector. The dataset also provides 20 random train/test splits in which 100 identities are selected for testing and the rest for training.
Market1501
Market-1501 is a large-scale public benchmark dataset for person re-identification. It contains 1,501 identities, which are captured by six different cameras, and 32,668 pedestrian image bounding boxes obtained using the Deformable Part Models pedestrian detector. The dataset is split into two parts: 750 identities are utilized for training and the remaining 751 identities are used for testing.
MSMT 17
MSMT17 is a multi-scene, multi-time person re-identification dataset. The dataset consists of 180 hours of videos, captured by 12 outdoor cameras, 3 indoor cameras, and during 12 time slots. The videos cover a long period and present complex lighting variations, and they contain a large number of annotated identities, i.e., 4,101 identities and 126,441 bounding boxes.
Bounding Box Generation
This stage focuses on extracting the bounding boxes that contain image crops of people from the raw video data. It is tough to crop all the person images in large-scale datasets manually. Earlier, the bounding boxes were usually obtained by off-the-shelf object detection models like the Deformable Part Model but nowadays, better object detection algorithms like YOLO can be used. Panoptic segmentation can also be used for a more finer localization.
Many datasets also manually annotate images and some provide a mixture of manually annotated and the ones predicted by the pedestrian detector to create a more challenging and real-world dataset as the pedestrians would need to be detected in real-time by a pedestrian detector in the ReID system.
Model Training
This stage focuses on training a discriminative and robust ReID model with annotated person images/videos. This step is the core for developing a ReID system and is the most widely studied paradigm in the literature. Extensive models have been developed to handle the various challenges, concentrating on feature representation learning, distance metric learning, or their combinations.
Supervised Person ReID
Casting ReID as a pedestrian retrieval problem, most of the existing works adopt the network architectures used for image classification as the backbone. The ResNet50 network is used frequently as the backbone for extracting image feature vectors.
There are three categories of existing supervised ReID approaches:
- Learning global features from the whole image, with model training through a classification loss.
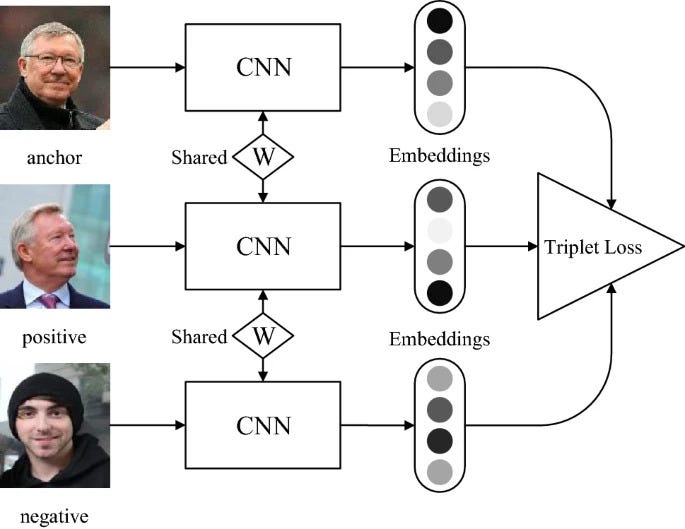
- Using a hard triplet loss on the global feature to ensure that same-person feature representations are closer. (see figure below)
- Learning a part-based feature instead. This involves partitioning an image into multiple horizontal strips and learning finer features from all the body parts. These methods try to use the classification loss on the parts.
Unsupervised Representation Learning
Contrastive learning and unsupervised pre-training methods can learn feature representations with comparable quality to that learned from supervised approaches. There have been proposals that stored representations in a memory bank. MoCo and MoCo v2 are self-supervised learning methods adopted by some research papers to perform unsupervised pre-training.
Loss Functions
A significant amount of research in this domain also focuses on introducing newer loss functions for developing better ReID models. The main objective of this task is to decrease intra-class variations and increase inter-class variations.
One of the most widely used loss functions is the triplet loss. Its primary goal is to create a representation space in which the similarity between related samples is closer together than between distinct examples. By enforcing the order of distances between anchor, positive, and negative examples, the triplet loss encourages the model to learn embeddings that place samples with identical labels nearer to each other while maintaining a considerable separation from samples with different labels. As a result, the triplet loss effectively embeds models to facilitate the proximity of samples sharing identical labels while maintaining a significant distance between samples with different labels. Other loss functions that build on the triplet loss and exhibit better results are center loss and circle loss.
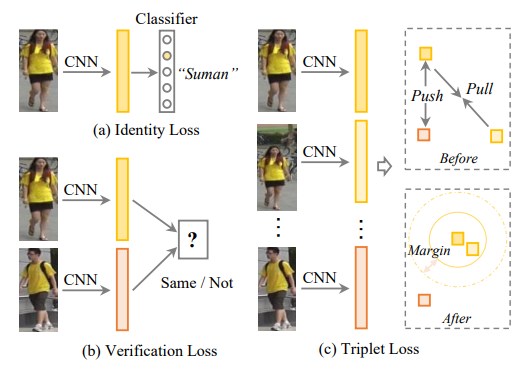
Identity loss is another kind of loss function that is used for ReID. It treats ReID as an image classification problem. This loss is computed by the cross-entropy.
Another kind of loss function used is the verification loss that optimizes the pairwise relationship either with a contrastive loss or binary verification loss.
Evaluation Metrics
To evaluate a ReID system, Cumulative Matching Characteristics (CMC) and mean Average Precision (mAP) are two widely used measurements.
CMC represents the probability that the correct match appears in the top-k ranked retrieved results.
Another metric, i.e., mean Average Precision (mAP) measures the average retrieval performance with multiple ground truths. For ReID, it can help address the issue of two models performing equally well in searching for the first ground truth, but having different performances for other hard matches.
Re-Ranking
Given a query image, the system will retrieve a set of candidate images from the gallery set that are similar to it based on some similarity metric like the Euclidean distance. After this initial ranking list is obtained, a good practice consists of adding a re-ranking step. This is required as sometimes the initial list might consist of false positive images as well. So re-ranking algorithms have been developed with the expectation that the true positive images will receive higher ranks in the re-ranked list [6].
Re-ranking methods have been successfully studied to improve object retrieval accuracy. Several works utilize the k-nearest neighbors to explore similarities between the neighbors to address the re-ranking problem. But sometimes, false positive matches might also get included in the k-nearest neighbors of the query image and compromise the final result.
Therefore, many methods also use k-reciprocal nearest neighbor. Two images are said to be k-reciprocal neighbors when both of them appear in the k-nearest neighbors of each other [6]. Therefore, this added constraint better ensures that true matches are included in the re-ranking.
Key Takeaways
There are many challenges with ReID that need to be tackled. Cross-domain generalization is an important issue that needs to be addressed. The size of the datasets particularly samples for each person is also a factor affecting the performance of this system. Similar colored clothing on different people can also cause performance degradation. These are some issues that warrant further research to build better ReID systems.
ReID can be used to bolster security in public spaces, financial institutions, schools, and many other places of significance. It has been a field of research for many years and with the advent of self-supervised learning and contrastive learning techniques that help in learning better representations, it holds the potential to be incorporated into real-world security solutions soon.
References
[1] Fu, Dengpan, et al. “Unsupervised pre-training for person re-identification.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021.
[2] Wieczorek, Mikołaj, Barbara Rychalska, and Jacek Dąbrowski. “On the unreasonable effectiveness of centroids in image retrieval.” Neural Information Processing: 28th International Conference, ICONIP 2021, Sanur, Bali, Indonesia, December 8–12, 2021, Proceedings, Part IV 28. Springer International Publishing, 2021.
[3] Ye, Mang, et al. “Deep learning for person re-identification: A survey and outlook.” IEEE transactions on pattern analysis and machine intelligence 44.6 (2021): 2872–2893.
[4] Xiao, Tong, et al. “Joint detection and identification feature learning for person search.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
[5] Sun, Yifan, et al. “Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline).” Proceedings of the European conference on computer vision (ECCV). 2018.
[6] Zhong, Zhun, et al. “Re-ranking person re-identification with k-reciprocal encoding.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")