



Understanding Flash-Attention and Flash-Attention-2: The Path to Scale The Context Lenght of Language Models
Last Updated on November 6, 2023 by Editorial Team
Author(s): Jesus Rodriguez
Originally published on Towards AI.
I recently started an AI-focused educational newsletter, that already has over 160,000 subscribers. TheSequence is a no-BS (meaning no hype, no news, etc) ML-oriented newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers, and concepts. Please give it a try by subscribing below:
TheSequence U+007C Jesus Rodriguez U+007C Substack
The best source to stay up-to-date with the developments in the machine learning, artificial intelligence, and data…
thesequence.substack.com
Scaling the context of large language models(LLMs) remains one of the biggest challenges to expanding the universe of use cases. In recent months, we have seen vendors such as Anthropic or OpenAI pushing the context lengths of their models to new heights. This trend is likely to continue, but it's likely to require some research breakthroughs. One of the most interesting works in this area was recently published by Stanford University. Dubbed FlashAttention, this new technique has been rapidly adopted as one of the main mechanisms for increasing the context of LLMs. The second iteration of FlashAttention, FlashAttention-2, was recently published. In this post, I would like to review the fundamentals of both versions.
FashAttention v1
In the realm of cutting-edge algorithms, FlashAttention emerges as a game-changer. This algorithm not only reorders attention computation but also harnesses classical techniques like tiling and recomputation to achieve a remarkable boost in speed and a substantial reduction in memory usage. The shift is transformative, moving from a quadratic to a linear memory footprint in relation to sequence length. For most scenarios, FlashAttention does pretty well, but it does come with a caveat — it wasn’t fine-tuned for exceptionally lengthy sequences, where parallelism is lacking.
When tackling the challenge of training large Transformers on extended sequences, employing modern parallelism techniques like data parallelism, pipeline parallelism, and tensor parallelism is key. These approaches divide data and models across numerous GPUs, which can result in minuscule batch sizes (think batch size of 1 with pipeline parallelism) and a modest number of heads, typically ranging from 8 to 12 with tensor parallelism. It’s precisely this scenario that FlashAttention seeks to optimize.
For every attention head, FlashAttention adopts classical tiling techniques to minimize memory reads and writes. It shuttles blocks of query, key, and value from the GPU’s HBM (main memory) to its speedy SRAM (fast cache). After performing attention computations on this block, it writes back the output to HBM. This memory read/write reduction yields a substantial speedup, often ranging from 2 to 4 times the original speed in most use cases.
The initial iteration of FlashAttention ventured into parallelization over batch size and the number of heads. Those well-versed in CUDA programming will appreciate the deployment of one thread block to process each attention head, resulting in a grand total of batch_size * num_heads thread blocks. Each thread block is meticulously scheduled to run on a streaming multiprocessor (SM), with an A100 GPU boasting a generous count of 108 of these SMs. This scheduling prowess truly shines when batch_size * num_heads reaches considerable values, say, greater than or equal to 80. In such instances, it allows for the efficient utilization of nearly all the GPU’s computational resources.
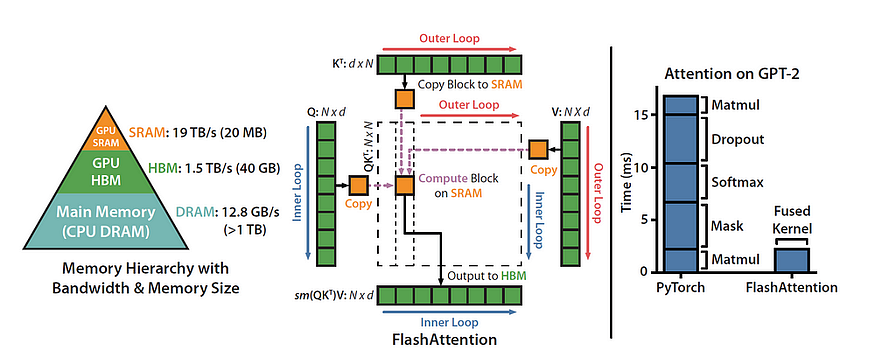
However, when it comes to handling lengthy sequences — usually associated with small batch sizes or a limited number of heads — FlashAttention takes a different approach. It now introduces parallelization over the sequence length dimension, resulting in remarkable speed enhancements tailored to this specific domain.
When it comes to backward pass, FlashAttention opts for a slightly altered parallelization strategy. Each worker takes charge of a block of columns within the attention matrix. These workers collaborate and communicate to aggregate the gradient concerning the query, employing atomic operations for this purpose. Interestingly, FlashAttention has discovered that parallelizing by columns outperforms parallelizing by rows in this context. The reduced communication between workers proves to be the key, as parallelizing by columns entails aggregating the gradient of the query, while parallelizing by rows necessitates aggregating the gradient of the key and value.

FlashAttention-2
With FlashAttention-2, the Stanford team implements thoughtful refinement to the initial version, focusing on minimizing non-matmul FLOPs within the algorithm. This adjustment holds profound significance in the era of modern GPUs, which come equipped with specialized compute units like Nvidia’s Tensor Cores, vastly accelerating matrix multiplications (matmul).
FlashAttention-2 also revisits the online softmax technique it relies on. The goal is to streamline rescaling operations, bound-checking, and causal masking, all while preserving the output’s integrity.
In its initial iteration, FlashAttention harnessed parallelism across both batch size and the number of heads. Here, each attention head was processed by a dedicated thread block, resulting in a total of (batch_size * number of heads) thread blocks. These thread blocks were efficiently scheduled onto streaming multiprocessors (SMs), with an exemplary A100 GPU boasting 108 such SMs. This scheduling strategy proved most effective when the total number of thread blocks was substantial, typically exceeding 80, as it allowed for the optimal utilization of the GPU’s computational resources.
To improve in scenarios involving lengthy sequences, often accompanied by small batch sizes or a limited number of heads, FlashAttention-2 introduces an additional dimension of parallelism — parallelization over the sequence length. This strategic adaptation yields substantial speed improvements in this particular context.
Even within each thread block, FlashAttention-2 must judiciously partition the workload among different warps, which represent groups of 32 threads operating in unison. Typically, 4 or 8 warps per thread block are employed, and the partitioning scheme is elucidated below. In FlashAttention-2, this partitioning methodology sees refinement, aimed at reducing synchronization and communication between various warps, thereby minimizing shared memory reads and writes.

In the previous configuration, FlashAttention divided K and V across 4 warps while maintaining Q’s accessibility for all warps, referred to as the “sliced-K” scheme. However, this approach exhibited inefficiencies, as all warps needed to write their intermediate results to shared memory, synchronize, and then aggregate these results. These shared memory operations imposed a performance bottleneck on FlashAttention’s forward pass.
In FlashAttention-2, the strategy takes a different course. It now allocates Q across 4 warps while ensuring K and V remain accessible to all warps. After each warp conducts matrix multiplication to obtain a slice of Q K^T, they simply multiply it with the shared slice of V to derive their respective output slice. This arrangement eliminates the need for inter-warp communication. The reduction in shared memory reads/writes translates into a significant speedup.
The earlier iteration of FlashAttention supported head dimensions up to 128, sufficient for most models but leaving some on the sidelines. FlashAttention-2 extends its support to head dimensions up to 256, accommodating models like GPT-J, CodeGen, CodeGen2, and StableDiffusion 1.x. These models can now harness FlashAttention-2 for enhanced speed and memory efficiency.
Furthermore, FlashAttention-2 introduces support for multi-query attention (MQA) and grouped-query attention (GQA). These are specialized attention variants where multiple heads of the query simultaneously attend to the same head of key and value. This strategic maneuver aims to reduce the KV cache size during inference, ultimately leading to significantly higher inference throughput.
The Improvements
The Stanford team evaluated FlashAttention-2 across different benchmarks with notable improvements over the original version and other alternatives. The tests included different variations on the attention architecture and the results were quite notable.
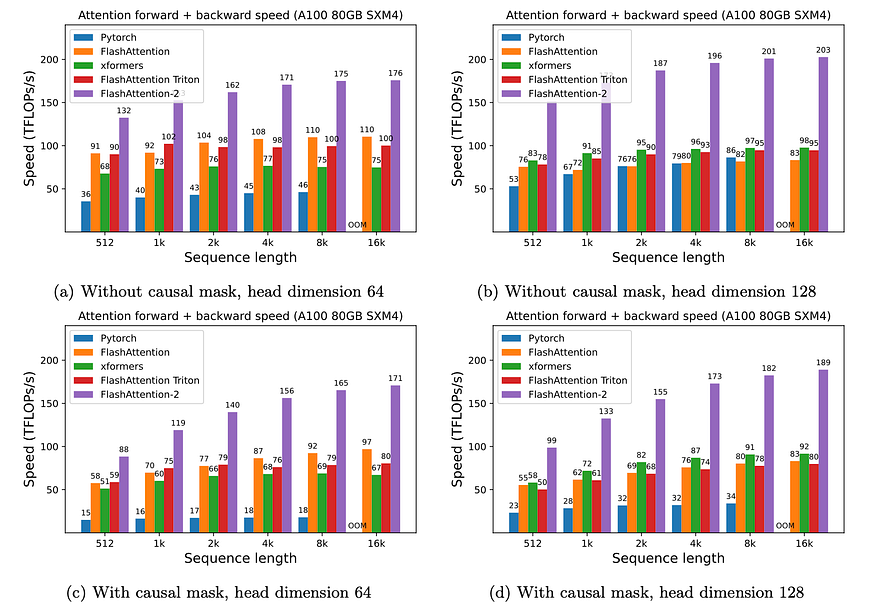
FlashAttention and FlashAttention-2 are two of the fundamental techniques used to scale the context of LLMs. The research represents one of the biggest research breakthroughs in this area and is influencing new methods that can help increase the capacity of LLMs.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


