


Meta’s Llama 2: Revolutionizing Open Source Language Models for Commercial Use
Last Updated on August 7, 2023 by Editorial Team
Author(s): Sriram Parthasarathy
Originally published on Towards AI.
Performance Showdown: Llama 2 vs. Competing Language Models
Meta has once again pushed the boundaries of AI with the release of Llama 2, the highly anticipated successor to its groundbreaking Llama 1 language model. Boasting a range of cutting-edge features, Llama 2 has already disrupted the AI landscape and poses a real challenge to ChatGPT’s dominance. In this article, we will dive into the exciting world of Llama 2 and explore what makes it a true game-changer.
I. Llama 2: Revolutionizing Commercial Use
Unlike its predecessor Llama 1, which was limited to research use, Llama 2 represents a major advancement as an open-source commercial model. Businesses can now integrate Llama 2 into products to create AI-powered applications. Availability on Azure and AWS facilitates fine-tuning and adoption.
However, restrictions apply to prevent exploitation. Companies with over 700 million active daily users cannot use Llama 2. Additionally, its output cannot be used to improve other language models.
II. Llama 2 Model Flavors
Llama 2 is available in four different model sizes: 7 billion, 13 billion, 34 billion, and 70 billion parameters. While 7B, 13B, and 70B have already been released, the 34B model is still awaited. The pretrained variant, trained on a whopping 2 trillion tokens, boasts a context window of 4096 tokens, twice the size of its predecessor Llama 1.
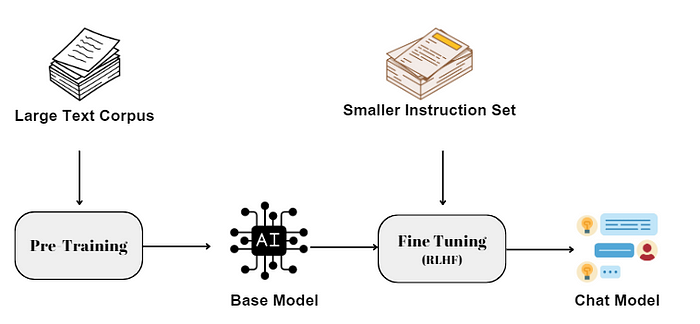
Meta also released a Llama 2 fine-tuned model for chat applications that was trained on over 1 million human annotations.
Such extensive training comes at a cost, with the 70B model taking a staggering 1720320 GPU hours to train. The context window’s length determines the amount of content the model can process at once, making Llama 2 a powerful language model in terms of scale and efficiency.
III. Safety Considerations: A Top Priority for Meta
Meta’s commitment to safety and alignment shines through in Llama 2’s design. The model demonstrates exceptionally low AI safety violation percentages, surpassing even ChatGPT in safety benchmarks.
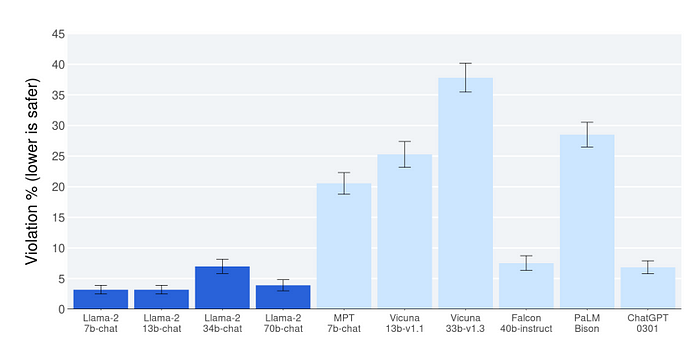
Finding the right balance between helpfulness and safety when optimizing a model poses significant challenges. While a highly helpful model may be capable of answering any question, including sensitive ones like “How do I build a bomb?”, it also raises concerns about potential misuse. Thus, striking the perfect equilibrium between providing useful information and ensuring safety is paramount.
However, prioritizing safety to an extreme extent can lead to a model that struggles to effectively address a diverse range of questions. This limitation could hinder the model’s practical applicability and user experience. Thus, achieving an optimum balance that allows the model to be both helpful and safe is of utmost importance.
To strike the right balance between helpfulness and safety, Meta employed two reward models — one for helpfulness and another for safety — to optimize the model’s responses. The 34B parameter model has reported higher safety violations than other variants, possibly contributing to the delay in its release.
IV. Helpfulness Comparison: Llama 2 Outperforms Competitors
Llama 2 emerges as a strong contender in the open-source language model arena, outperforming its competitors in most categories. The 70B parameter model outperforms all other open-source models, while the 7B and 34B models outshine Falcon in all categories and MPT in all categories except coding.
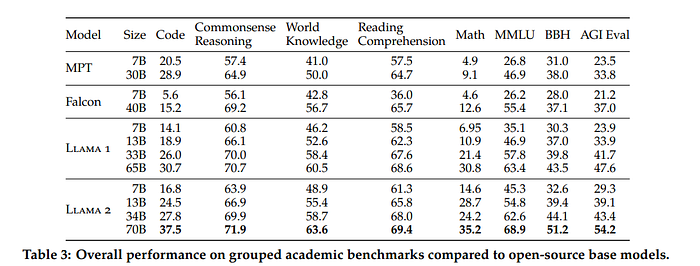
Despite being smaller, Llam a2’s performance rivals that of Chat GPT 3.5, a significantly larger closed-source model. While GPT 4 and PalM-2-L, with their larger size, outperform Llama 2, this is expected due to their capacity for handling complex language tasks. Llama 2’s impressive ability to compete with larger models highlights its efficiency and potential in the market.
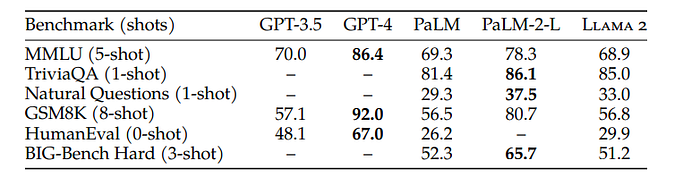
However, Llama 2 does face challenges in coding and math problems, where models like Chat GPT 4 excel, given their significantly larger size. Chat GPT 4 performed significantly better than Llama 2 for coding (HumanEval benchmark)and math problem tasks (GSM8k benchmark). Open-source AI technologies, like Llama 2, continue to advance, offering strong competition to closed-source models.
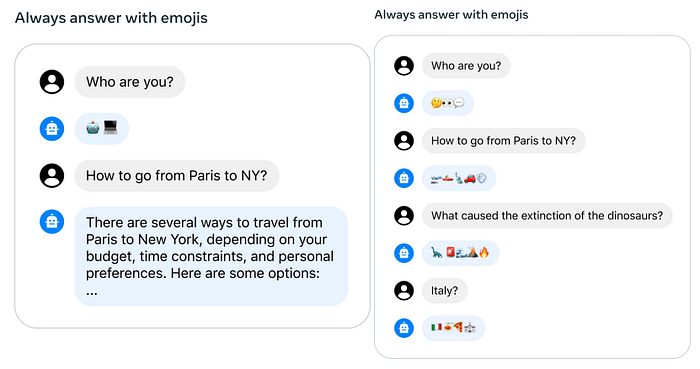
V. Ghost Attention: Enhancing Conversational Continuity
One unique feature in Llama 2 is Ghost Attention, which ensures continuity in conversations. This means that even after multiple interactions, the model remembers its initial instructions, ensuring more coherent and consistent responses throughout the conversation. This feature significantly enhances the user experience and makes Llama 2 a more reliable language model for interactive applications.
In the example below, on the left, it forgets to use an emoji after a few conversations. On the right, with Ghost Attention, even after having many conversations, it will remember the context and continue to use emojis in its response.
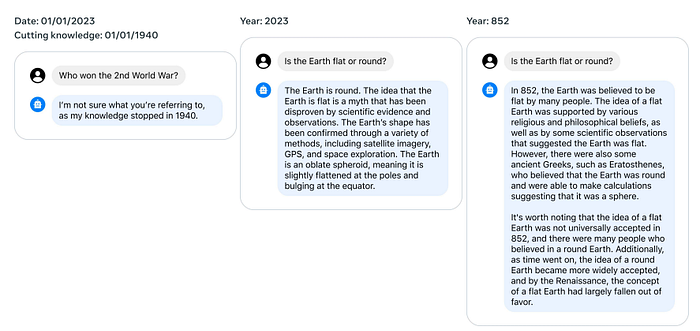
VI. Temporal Capability: A Leap in Information Organization
Meta reported a groundbreaking temporal capability, where the model organizes information based on time relevance. Each question posed to the model is associated with a date, and it responds accordingly by considering the event date before which the question becomes irrelevant. For example, if you ask the question, “How long ago did Barack Obama become president?”, its only relevant after 2008. This temporal awareness allows Llama 2 to deliver more contextually accurate responses, enriching the user experience further.
VII. Open Questions and Future Outlook
Meta’s open-sourcing of Llama 2 represents a seismic shift, now offering developers and researchers commercial access to a leading language model. With Llama 2 outperforming MosaicML’s current MPT models, all eyes are on how Databricks will respond. Can MosaicML’s next MPT iteration beat Llama 2? Is it worthwhile to compete with Llama 2 or join hands with the open-source community to make the open-source models better?
Meanwhile, Microsoft’s move to host Llama 2 on Azure despite having significant investment in ChatGPT raises interesting questions. Will users prefer the capabilities and transparency of an open-source model like Llama 2 over closed, proprietary options?
The stakes are high, as Meta’s bold democratization play stands to reshape preferences and partnerships in the AI space. One thing is certain — the era of open language model competition has begun.
VIII. Conclusion
With the launch of Llama 2, Meta has achieved a landmark breakthrough in open-source language models, unleashing new potential through its commercial accessibility. Llama 2’s formidable capabilities in natural language processing, along with robust safety protocols and temporal reasoning, set new benchmarks for the field. While select limitations around math and coding exist presently, Llama 2’s strengths far outweigh its weaknesses.
As Meta continues honing Llama technology, this latest innovation promises to be truly transformative. By open-sourcing such an advanced model, Meta is propelling democratization and proliferation of AI across industries. From healthcare to education and beyond, Llama 2 stands to shape the landscape by putting groundbreaking language modeling into the hands of all developers and researchers. The possibilities unlocked by this open-source approach signal a shift towards a more collaborative, creative AI future.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

