



Information & Entropy
Last Updated on August 20, 2023 by Editorial Team
Author(s): Sushil Khadka
Originally published on Towards AI.
What, Why, and How explained
Use “entropy” and you can never lose a debate, von Neumann told Shannon because no one really knows what “entropy” is.
— William Poundstone
Let us begin with a bit of history.
In 1948, a mathematician named Claude E. Shannon published an article titled “A Mathematical Theory of Communication,” which introduced a pivotal concept in Machine Learning: Entropy.
While entropy measures disorder in physics, its meaning shifts in Information theory. Yet, both gauge disorder or uncertainty.
Let’s delve into the notion of “Information.”
I. Shannon’s Information
According to the paper, we can quantify the information that an event conveys, which can be interpreted as measuring the level of “surprise”. It signifies that the information content essentially represents the extent of surprise contained within an event.
Let’s take an example: Imagine someone tells you, “Animals need water to survive.” How surprised would you be upon hearing this sentence?
You would not be surprised at all because it’s a well-known and consistently true fact. In such a scenario, the quantity of surprise equates to 0, and consequently, the conveyed information would also amount to 0.
But what if someone were to say, “I got tails on tossing a coin”? Well, this event (getting tails) is not guaranteed, Is it? There’s always a 50–50 chance, that the outcome could be either heads or tails. Consequently, hearing this statement might invoke a certain level of surprise. Herein lies a captivating correlation between probability and surprise. When an event is absolutely certain (with a probability of 1), the measure of surprise diminishes (becomes 0). Conversely, as the probability decreases — meaning the event becomes less probable — the sense of surprise rises. This is the inverse relationship between probability and surprise.
Mathematically,
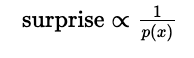
where p(x) is the probability of an event x.
We know that information is nothing more than a quantity of surprise. And since we’re trying to do some maths here so, we can replace the word “surprise” with “information.”
What if you do information = 1/p(x)?
Let’s examine this in some edge cases:
When p(x) = 0, information = 1/0 = ∞ (infinite/undefined). This outcome aligns with our intuition: an event that was deemed impossible but still happened would yield infinite or undefined surprise/information. (An impossible scenario) U+279F U+2705
When p(x)=1, information = 1/1 = 1, which contradicts our observation. Ideally, we aim for 0 surprises in the case of an absolutely probable event.
U+279F U+274C
Fortunately, the logarithmic function comes in handy. (Throughout this post, we’ll consistently use log₂ denoted as log.)
Information = log ( 1/p(x) ) = log(1) — log( p(x) ) = 0 — log( p(x) )
Information = -log( p(x) )
Let’s examine this new equation in some edge cases:
when p(x) = 0 , information = -log( 0 )= ∞ U+279F U+2705
when p(x) = 1, information = -log(1) = 0, which is indeed the desired outcome since an absolute probable event should carry no surprise/information U+279F U+2705
So to measure the amount of surprise or information conveyed by an event, we can make use of the formula:
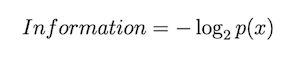
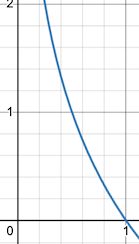
This -log function gives 0 when x = 1 (meaning that when the probability is 1, the information is 0). As x decreases, the corresponding y value sharply increases. When x = 0, the information becomes infinite or undefined. This curve accurately captures our intuitive understanding of information.
And for a series of events, it becomes
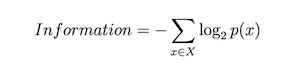
Which is nothing but a sum of information about each event. The unit of information is ‘bits’. Here’s another intuitive perspective:
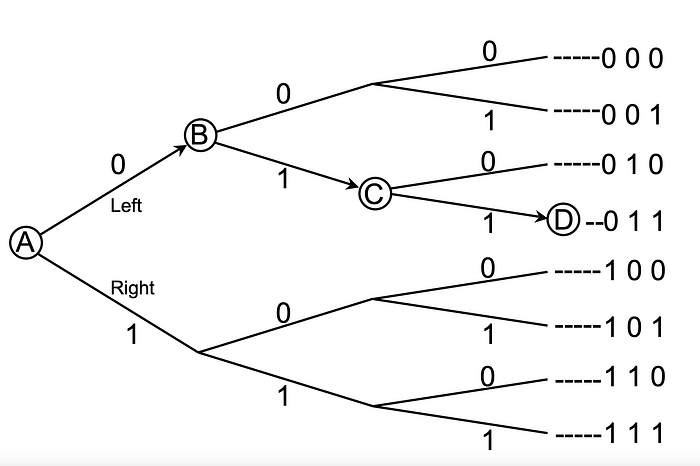
Imagine you’re at point A and you would want to reach point D. However, you have no clue of routes and have no visibility of adjacent points. Moreover, you can’t travel backward.
While you’re at A, you have two choices Left(0) and Right(1). I send you a single bit, 0, one bit of information which helps you to choose from 2 choices (second column). Upon your arrival at B, I provide you with a bit value of 1, totaling 2 bits, allowing you to choose from 2 * 2 = 4 options (third column). When you progress to C, I send you another 1, totaling 3 bits. This helps you to choose from 2 * 2 * 2 = 8 options(last column). And Interestingly, 1 is the logarithm of 2, 2 is the logarithm of 4, and 3 is the logarithm of 8.
‘n’ bits of information allow us to choose from ‘m’ options.
For instance, 8 = 2 ³ ( where m = 8 representing total possible outcomes, and n = 3 representing the number of bits)
In general,
m = 2ⁿ

This is the equation for information (number of useful bits).
The basic intuition behind information theory is that learning that an unlikely event has occurred is more informative than learning that a likely event has occurred.
— Page 73, Deep Learning, 2016.
II. Entropy
Let us consider a scenario where we want to generate random numbers from a given list [1, 2, 3, 4] using the probability distribution.
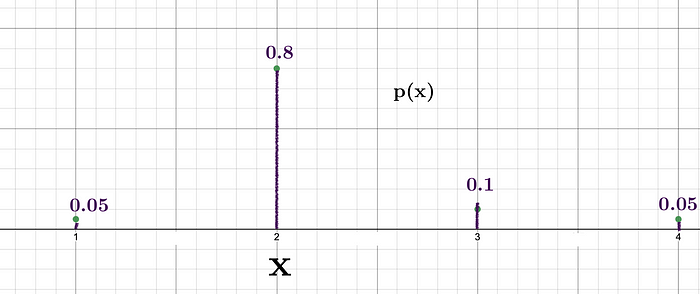
We can see that the probability of getting 2 is the highest, which means that the level of surprise upon getting 2 would be relatively lower compared to the surprise when getting 3, which has a probability of 0.1. The Shannon information for these two events are:
- Information for 2 = -log(0.8) = 0.32 bits
- Information for 3 = -log(0.1) = 3.32 bits
Notice that each time we generate a number, the information obtained varies.
Suppose we carry out this generation process 100 times following the provided distribution. To compute the total information, we need to sum up the individual information obtained in each instance.
Number of observations generating 1 = 0.05 * 100 = 5,
Number of observations generating 2 = 0.8 * 100 = 80
Number of observations generating 3 = 0.1 * 100 = 10
Number of observations generating 4 = 0.05 * 100 = 5
Now, Let’s calculate the total information conveyed by the 100 generations.
Information obtained when generated 1 for 5 times = — log(0.05) * 5 = 21.6 bits
Information obtained when generated 2 for 80 times = — log(0.8) * 80= 25.8 bits
Information obtained when generated 3 for 10 times = — log(0.1) * 10= 23.2 bits
Information obtained when generated 4 for 5 times = — log(0.05) * 5 = 21.6 bits
Total information = 92.2 bits
Hence, the total information conveyed by the 100 observations is 92.2 bits.
Wouldn’t it be nice if we calculated the information per observation (average)?
Average Information of the above distribution = 92.2 / 100 (because we had 100 observations )
Average Information = 0.922 bits
YESSS, this is the quantity we call ENTROPY.
Nothing fancy here, it is just an average(expected) amount of information conveyed by a probability distribution. Now let’s derive a formula for Entropy.

p(x) × N gives the number of occurrences of event x when N total observations are made.
So, the final general equation is
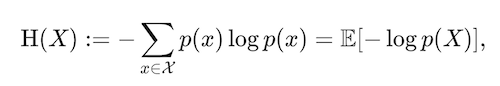
Where H is the entropy, and E is the expectation.
You can follow me as I’ll continue writing on AI and Mathematics.
References
[1] C. E. SHANNON, “A Mathematical Theory of Communication”, 1948
[2] Josh Stramer, “Entropy (for data science) Clearly Explained!!!”, Youtube, 2022
[3] James V Stone, “Information Theory: A Tutorial Introduction”, 2018
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

