



From Experiments 🧪 to Deployment 🚀: MLflow 101 | Part 01
Last Updated on August 9, 2023 by Editorial Team
Author(s): Afaque Umer
Originally published on Towards AI.
From Experiments U+1F9EA to Deployment U+1F680: MLflow 101 U+007C Part 01
Uplift Your MLOps Journey by crafting a Spam Filter using Streamlit and MLflow
The WhyU+2753
Picture this: You’ve got a brand new business idea, and the data you need is right at your fingertips. You’re all pumped up to dive into creating that fantastic machine-learning model U+1F916. But, let’s be real, this journey is no cakewalk! You’ll be experimenting like crazy, dealing with data preprocessing, picking algorithms, and tweaking hyperparameters till you’re dizzy U+1F635U+1F4AB. As the project gets trickier, it’s like trying to catch smoke — you lose track of all those wild experiments and brilliant ideas you had along the way. And trust me, remembering all that is harder than herding cats U+1F639
But wait, there’s more! Once you’ve got that model, you gotta deploy it like a champ! And with ever-changing data and customer needs, you’ll be retraining your model more times than you change your socks! It’s like a never-ending roller coaster, and you need a rock-solid solution to keep it all together U+1F517. Enter MLOps! It’s the secret sauce that brings order to the chaos U+26A1
Alright, folks, now that we’ve got the Why behind us, let’s dive into the What and the juicy How in this blog.
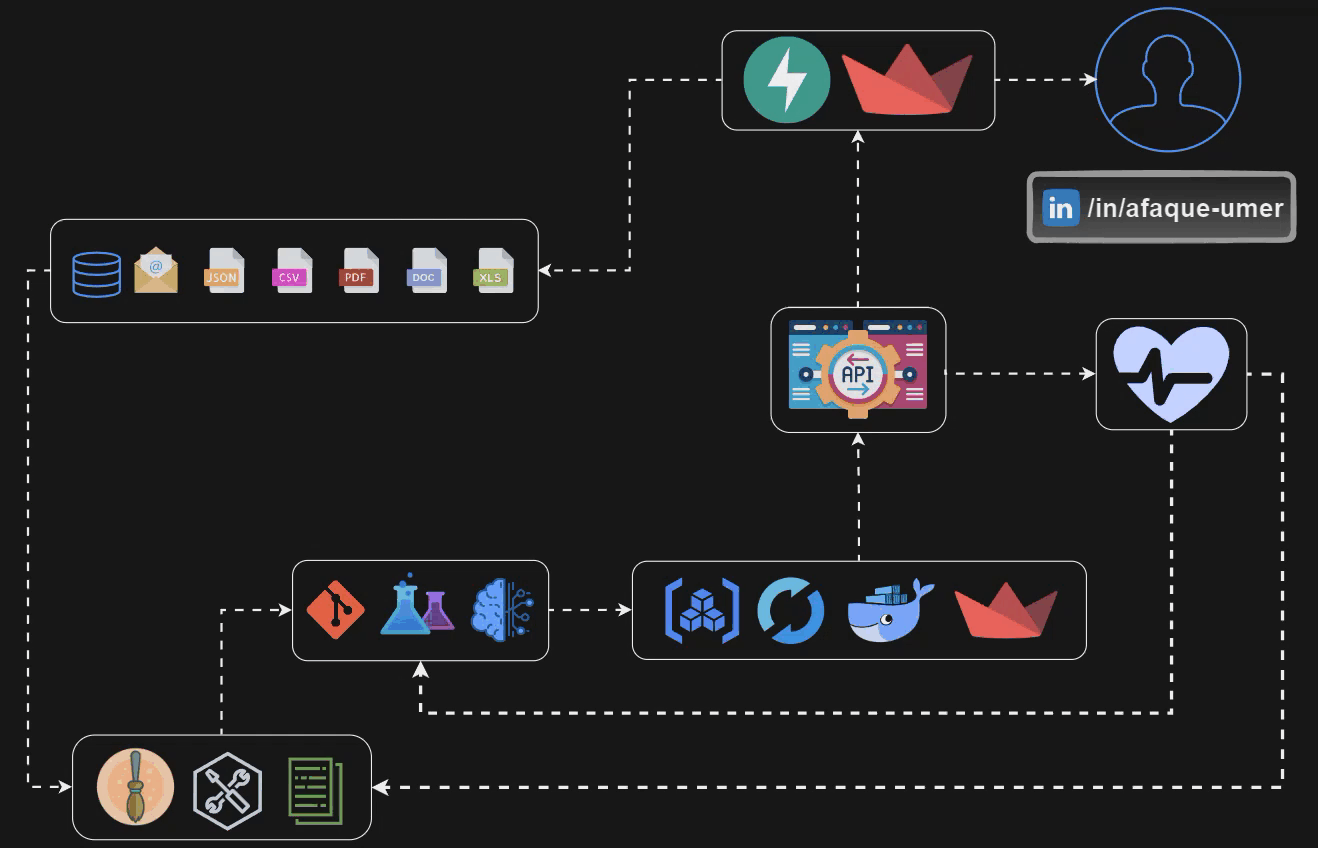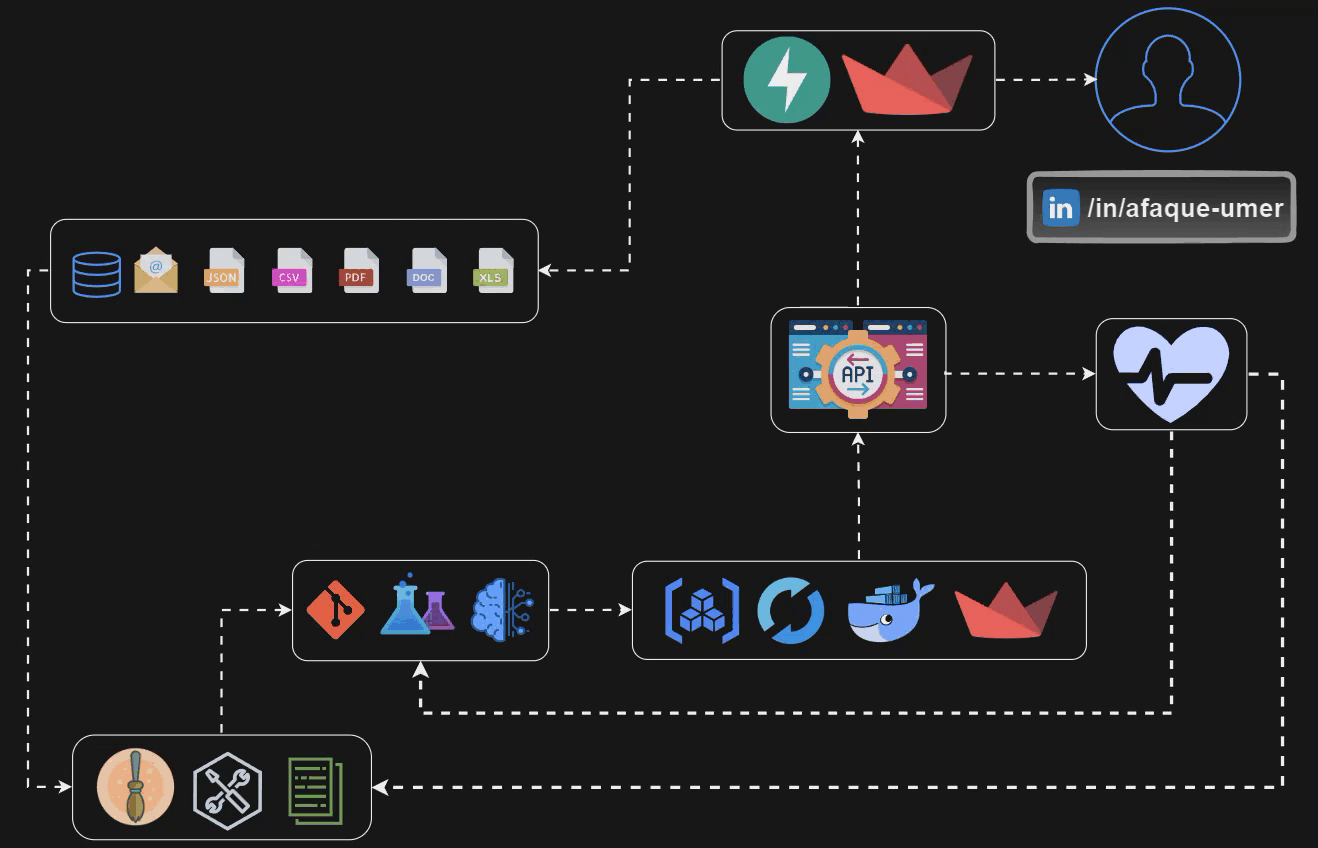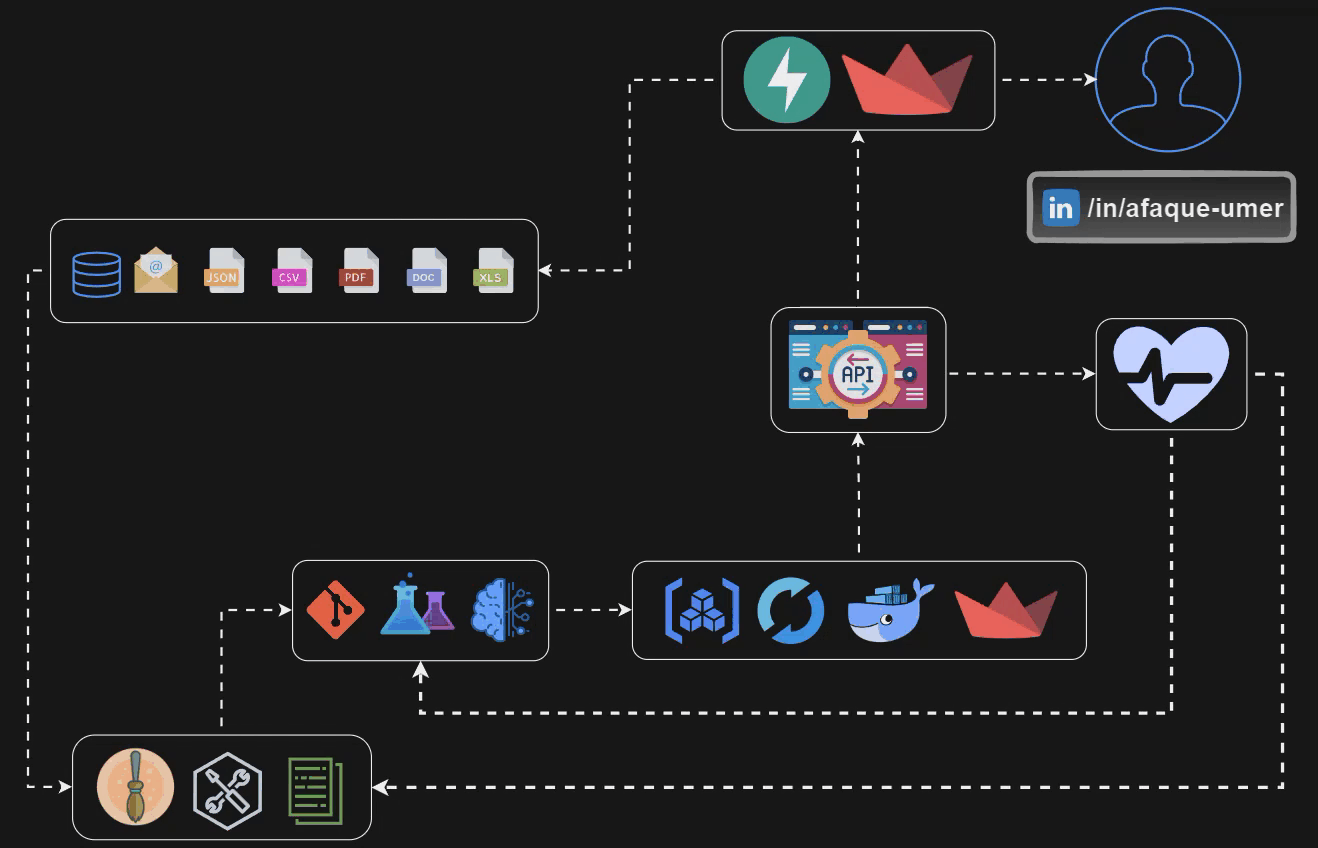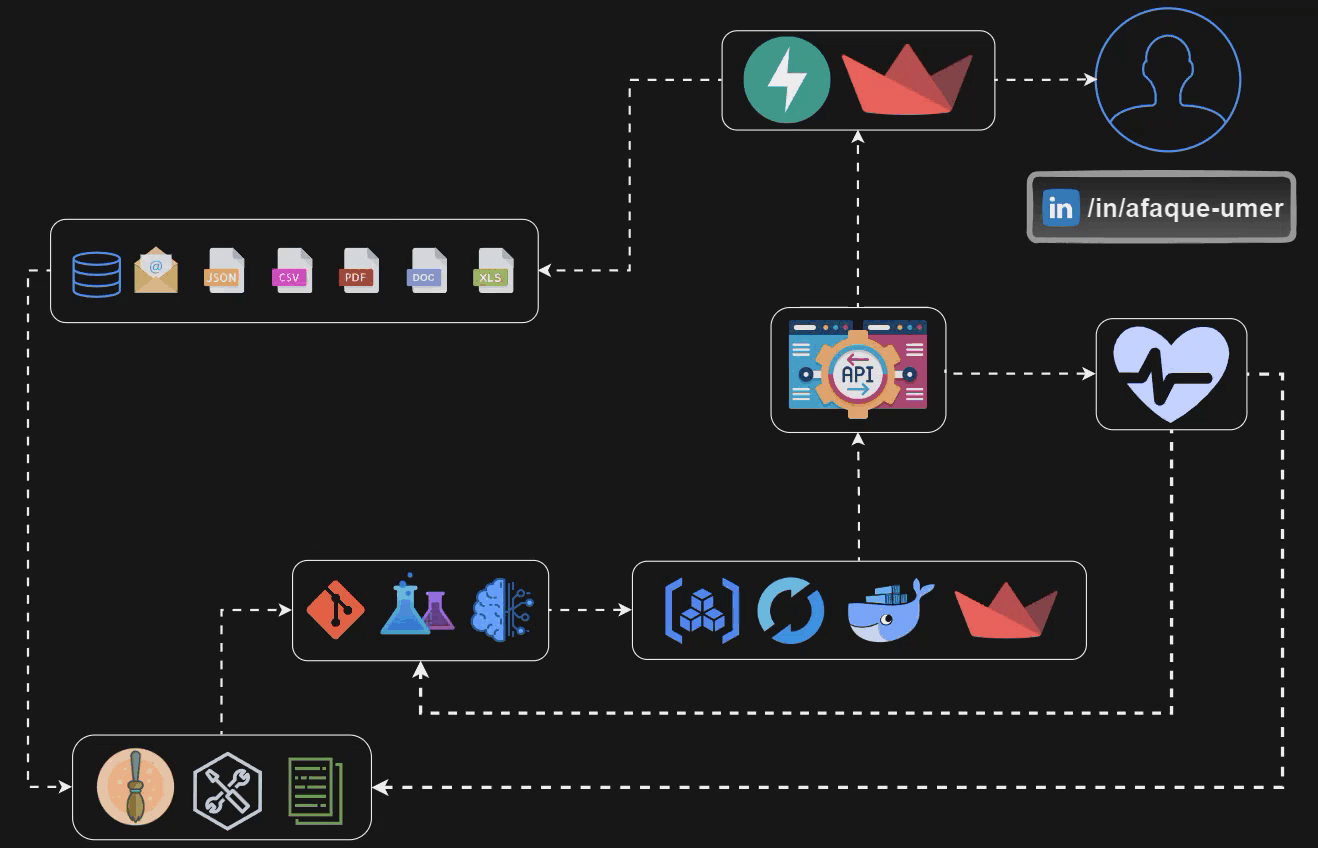
Let’s take a look at the pipeline that we are gonna build by the end of this blog U+1F446
Hold on tight, ’cause this ain’t gonna be a quick read! because condensing it would mean missing out on essential details. We’re crafting an end-to-end MLOps solution, and to keep it real, I had to split it into three sections, However, due to certain publication guidelines, I’ll have to split it as a series of 2 blog posts.
Section 1: We’ll lay down the foundations and theories U+1F4DC
Section 2: Now that’s where the action is! We’re building a spam filter and tracking all those crazy experiments with MLflow U+1F97CU+1F9EA
Section 3: We’ll focus on the real deal — deploying and monitoring our champ model, making it production-ready U+1F680
Let’s rock and roll with MLOps!
Section 1: The Essentials U+1F331
What is MLOps U+2754
MLOps represents a collection of methodologies and industry best practices aimed at assisting data scientists in simplifying and automating the entire model training, deployment, and management lifecycle within a large-scale production environment.

It is gradually emerging as a distinct and standalone approach for managing the entire machine-learning lifecycle. The essential stages in the MLOps process include the following:
- Data Gathering: Collecting relevant data from diverse sources for analysis.
- Data Analysis: Exploring and examining the collected data to gain insights.
- Data Transformation/Preparation: Cleaning, transforming, and preparing the data for model training.
- Model Training & Development: Designing and developing machine learning models using the prepared data.
- Model Validation: Evaluating the model’s performance and ensuring its accuracy.
- Model Serving: Deploying the trained model to serve real-world predictions.
- Model Monitoring: Continuously monitoring the model’s performance in production to maintain its effectiveness.
- Model Re-training: Periodically retraining the model with new data to keep it up-to-date and accurate.
How We’re Gonna Implement It? While several options are available like Neptune, Comet, and Kubeflow, etc. we will stick with MLflow. So, let’s get acquainted with MLflow and dive into its principles.
MLflow 101
MLflow is like the Swiss army knife of machine learning — it’s super versatile and open-source, helping you manage your entire ML journey like a boss. It plays nice with all the big-shot ML libraries(TensorFlow, PyTorch, Scikit-learn, spaCy, Fastai, Statsmodels, etc.). Still, you can also use it with any other library, algorithm, or deployment tool you prefer. Plus, it’s designed to be super customizable — you can easily add new workflows, libraries, and tools using custom plugins.

MLflow follows a modular and API-based design philosophy, breaking its functionality into four distinct parts.

Now, let’s check out each of these parts one by one!
MLflow Tracking:It is an API and UI that allows you to log parameters, code versions, metrics, and artifacts during your machine learning runs and visualize the results later. It works in any environment, enabling you to log in to local files or a server and compare multiple runs. Teams can also utilize it for comparing results from different users.Mlflow Projects:It is a way to package and reuse data science code easily. Each project is a directory with code or a Git repository and a descriptor file to specify dependencies and execution instructions. MLflow automatically tracks the project version and parameters when you use the Tracking API, making it simple to run projects from GitHub or your Git repository and chain them into multi-step workflows.Mlflow Models:It enables you to package machine learning models in different flavors and offers various tools for deployment. Each model is saved as a directory with a descriptor file listing its supported flavors. MLflow provides tools to deploy common model types to various platforms, including Docker-based REST servers, Azure ML, AWS SageMaker, and Apache Spark for batch and streaming inference. When you output MLflow Models using the Tracking API, MLflow automatically tracks their origin, including the Project and run they came from.Mlflow Registry:It is A centralized model store with APIs and UI to collaboratively manage the entire lifecycle of an MLflow Model. It includes model lineage, versioning, stage transitions, and annotations for effective model management.
That’s a wrap for our basic understanding of MLflow’s offerings. For more in-depth details, refer to its official documentation here U+1F449U+1F4C4. Now, armed with this knowledge, let’s dive into Section 2. We’ll kick things off by creating a simple spam filter app, and then we’ll go full-on experiment mode, tracking different experiments with unique runs!
Section 2: Experiment U+1F9EA and Observe U+1F50D
Alright, folks, get ready for an exciting journey! Before we dive into the lab and get our hands dirty with experiments, let’s lay out our plan of attack so we know what we’re building. First up, we’re gonna rock a spam classifier using the random forest classifier (I know Multinomial NB works better for doc classification, but hey, we wanna play around with random forest’s hyperparams). We’ll intentionally make it not-so-good at first, just for the thrill of it. Then, we’ll unleash our creativity and track various runs, tweaking hyperparams and experimenting with cool stuff like Bag of Words and Tfidf. And guess what? We will use MLflow UI like a boss for all that sweet tracking action and prep ourselves for the next section. So buckle up, 'cause we’re gonna have a blast! U+1F9EAU+1F4A5
Becoming One with the Data U+1F5C3️
For this task, we will use the Spam Collection Dataset available on Kaggle. This dataset contains 5,574 SMS messages in English, tagged as ham (legitimate) or spam. However, there is an imbalance in the dataset, with around 4,825 ham labels. To avoid deviation and keep things concise, I decided to drop some ham samples, reducing them to around 3,000, and saved the resulting CSV for further use in our model and text preprocessing. Feel free to choose your approach based on your needs — this was just for brevity. Here’s the code snippet showing how I achieved this.
Building a Basic Spam Classifier U+1F916
Now we have the data ready to roll, let’s swiftly build a basic classifier. I won’t bore you with the old cliché that computers can’t grasp text language, hence the need to vectorize it for text representation. Once that’s done, we can feed it to ML/DL algorithms and I won't tell you if you need a refresher or have any doubts, don't fret – I've got you covered in one of my previous blogs for you to refer to. You know that already, right? U+1F917
Mastering Regression Models: A Comprehensive Guide to Predictive Analysis
Introduction
levelup.gitconnected.com
Alright, let’s get down to business! We’ll load the data, and preprocess the messages to remove stopwords, punctuations, and more. We’ll even stemmize or lemmatize them for good measure. Then comes the exciting part — vectorizing the data to get some amazing features to work with. Next up, we’ll split the data for training and testing, fit it into the random forest classifier, and make those juicy predictions on the test set. Finally, it’s evaluation time to see how our model performs! let’s walk the talk U+26A1
In this code, I’ve provided several options for experiments as comments, such as preprocessing with or without stop words, lemmatizing, stemming, etc. Similarly, for vectorizing, you can choose between Bag of Words, TF-IDF, or embeddings. Now, let’s get to the fun part! We’ll train our first model by calling these functions sequentially and passing hyperparameters.
Yeah, I totally agree, this model is pretty much useless. The precision is nearly zero, which leads to an F1 score close to 0 as well. Since we have a slight class imbalance, the F1 score becomes more crucial than accuracy as it gives an overall measure of precision and recall — that’s its magic! So, here we have it — our very first terrible, nonsensical, and useless model. But hey, no worries, it’s all part of the learning journey U+1FA9C.
Now, let’s fire up MLflow and get ready to experiment with different options and hyperparameters. Once we fine-tune things, it will all start to make sense. We’ll be able to visualize and analyze our progress like pros!
Getting Started with MLflow U+267E️
First things first, let’s get MLflow up and running. To keep things neat, it’s recommended to set up a virtual environment. You can simply install MLflow using pip U+1F449pip install mlflow
Once it’s installed, fire up the MLflow UI by running U+1F449mlflow ui in the terminal (make sure it’s within the virtual environment where you installed MLflow). This will launch the MLflow server on your local browser hosted at http://localhost:5000. You will see a page similar to U+1F447

Since we haven’t recorded anything yet, there won’t be much to check on the UI. MLflow offers several tracking options, like local, local with a database, on a server, or even on the cloud. For this project, we’ll stick to everything local for now. Once we get the hang of the local setup, passing the tracking server URI and configuring a few parameters can be done later — the underlying principles remain the same.
Now, let’s dive into the fun part — storing metrics, parameters, and even models, visualizations, or any other objects, also known as artifacts.
MLflow’s tracking functionality can be seen as an evolution or replacement of traditional logging in the context of machine learning development. In traditional logging, you would typically use custom string formatting to record information such as hyperparameters, metrics, and other relevant details during model training and evaluation. This logging approach can become tedious and error-prone, especially when dealing with a large number of experiments or complex machine-learning pipelines whilst Mlflow automates the process of recording and organizing this information, making it easier to manage and compare experiments leading to more efficient and reproducible machine learning workflows.
Mlflow Tracking U+1F4C8
Mlflow tracking is centered around three main functions: log_param for logging parameters, log_metric for logging metrics, and log_artifact for logging artifacts (e.g., model files or visualizations). These functions facilitate organized and standardized tracking of experiment-related data during the machine learning development process.

When logging a single parameter, it is recorded using a key-value pair within a tuple. On the other hand, when dealing with multiple parameters, you would use a dictionary with key-value pairs. The same concept applies to logging metrics as well. Here’s a code snippet to illustrate the process.
# Log a parameter (key-value pair)
log_param("config_value", randint(0, 100))
# Log a dictionary of parameters
log_params({"param1": randint(0, 100), "param2": randint(0, 100)})
Understanding Experiment U+1F9EA vs Runs U+1F3C3U+2640️
An experiment acts as a container representing a group of related machine learning runs, providing a logical grouping for runs with a shared objective. Each experiment has a unique experiment ID, and you can assign a user-friendly name for easy identification.
On the other hand, a run corresponds to the execution of your machine-learning code within an experiment. You can have multiple runs with different configurations within a single experiment, and each run is assigned a unique run ID. The tracking information, which includes parameters, metrics, and artifacts, is stored in a backend store, such as a local file system, database (e.g., SQLite or MySQL), or remote cloud storage (e.g., AWS S3 or Azure Blob Storage).
MLflow offers a unified API to log and track these experiment details, regardless of the backend store in use. This streamlined approach allows for effortless retrieval and comparison of experiment results, enhancing the transparency and manageability of the machine learning development process.
To begin, you can create an experiment using either mlflow.create_experiment() or a simpler method, mlflow.set_experiment("your_exp_name"). If a name is provided, it will use the existing experiment; otherwise, a new one will be created to log runs.
Next, call mlflow.start_run() to initialize the current active run and start logging. After logging the necessary information, close the run using mlflow.end_run().
Here’s a basic snippet illustrating the process:
import mlflow
# Create an experiment (or use existing)
mlflow.set_experiment("your_exp_name")
# Start the run and begin logging
with mlflow.start_run():
# Log parameters, metrics, and artifacts here
mlflow.log_param("param_name", param_value)
mlflow.log_metric("metric_name", metric_value)
mlflow.log_artifact("path_to_artifact")
# The run is automatically closed at the end of the 'with' block
Creating UI for Hyperparameter Tuning using StreamlitU+1F525
Instead of executing scripts via the shell and providing parameters there, we’ll opt for a user-friendly approach. Let’s build a basic UI that allows users to input either the experiment name or specific hyperparameter values. When the train button is clicked, it will invoke the train function with the specified inputs. Additionally, we’ll explore how to query experiments and runs once we have a substantial number of runs saved.
With this interactive UI, users can effortlessly experiment with different configurations and track their runs for more streamlined machine-learning development.
I won’t delve into the specifics of Streamlit since the code is straightforward. I’ve made minor adjustments to the earlier train function for MLflow logging, as well as implemented custom theme settings. Before running an experiment, users are prompted to choose between entering a new experiment name (which logs runs in that experiment) or selecting an existing experiment from the dropdown menu, generated using mlflow.search_experiments(). Additionally, users can easily fine-tune hyperparameters as needed. Here is the code for the application U+1F447
and here is what the app will look like U+1F680

Alright, it’s time for a temporary farewell U+1F44B, but don’t you worry — we’ll reunite in the next installment of this blog series U+1F91D. In the upcoming part, we’re diving headfirst into the experiments and putting our models into to cage fight and only the best will thrive in the Colosseum of MLflow Tracking U+1F9BE. Once you’re in the groove, you won’t want to hit pause, so grab a cup of coffee U+1F375, recharge U+1F50B, and join us for the next exciting chapter U+26A1. Here’s the link to Part 02 U+1F447
Medium
Edit description
pub.towardsai.net
See you there U+1F440
Thanks for reading U+1F64FKeep rockingU+1F918Keep learning U+1F9E0 Keep Sharing U+1F91D and above all Keep experimenting! U+1F9EAU+1F525U+2728U+1F606
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

