


Meet HUSKY: A New Agent Optimized for Multi-Step Reasoning
Author(s): Jesus Rodriguez
Originally published on Towards AI.

I recently started an AI-focused educational newsletter, that already has over 170,000 subscribers. TheSequence is a no-BS (meaning no hype, no news, etc) ML-oriented newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers, and concepts. Please give it a try by subscribing below:
TheSequence | Jesus Rodriguez | Substack
The best source to stay up-to-date with the developments in the machine learning, artificial intelligence, and data…
thesequence.substack.com
Reasoning is highly acknowledged as the next frontier in generative AI. By reasoning, we refer to the ability to decompose a task into smaller subsets and solve those individually. Chain-of-Thought, Tree-of-Tought, Skeleton-of-Thought, and Reflexion are some of the recent techniques that have tackled reasoning capabilities in LLMs. Reasoning also involves peripherical capabilities such as accessing external data or tools. In the last couple of years, we have seen models to perform extremely well in specific reasoning techniques, but they failed to generalize across domains. This is not a surprise if we consider that reasoning is a very computationally expensive task. This is precisely the challenge that researchers from Meta AI, Allen Institute of AI and the University of Washington address in a recent paper.
HUSKY is an open-source language agent designed to handle a variety of complex tasks involving numerical, tabular, and knowledge-based reasoning. Unlike other agents that focus on specific tasks or use proprietary models, HUSKY operates within a unified framework to manage diverse challenges. It works in two stages: first, it generates the next action needed to solve a task; second, it executes this action using expert models, updating the solution as it progresses.

Inside HUSKY
HUSKY employs a detailed action plan to address complex tasks. Initially, it generates the next step, which includes the action and the tool required. Then, it executes the action using specialized models, updating the solution state. This approach allows HUSKY to function like a modern version of classical planning systems, using large language models (LLMs) to optimize performance.
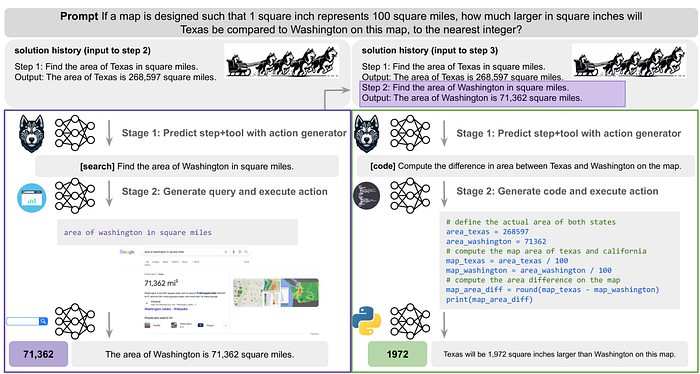
For tasks requiring multi-step reasoning, HUSKY predicts the next action and the corresponding tool, then executes it with an expert model. This process continues until the final answer is found. HUSKY uses multiple LLMs to coordinate expert models, akin to a team of huskies pulling a sled together.
Action and Tool Selection
HUSKY iterates between generating actions and executing them until reaching a terminal state. The action generator predicts the next high-level step and assigns a tool from a predefined set: code, math, search, or commonsense. Based on the tool assigned, HUSKY calls the expert model, performs the action, and updates the solution state, optionally converting the output to natural language.
Training HUSKY
HUSKY’s training involves creating tool-integrated solution trajectories using a teacher model. These trajectories help build training data for the action generator and expert models. The training pipeline is simplified and generalizable, ensuring that HUSKY can handle a wide range of tasks without task-specific assumptions.
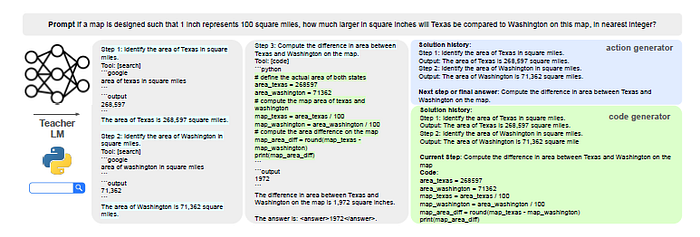
Inference Process
During inference, HUSKY integrates its trained modules to solve new, multi-step tasks. The action generator determines the first step and tool, then passes it to the expert model, which produces the output. This iterative process continues until the final solution is achieved, with the expert models providing specific outputs for each step.
Evaluation and Performance
Evaluating HUSKY involves testing its inference capabilities on complex reasoning tasks and scoring the results. Existing datasets often lack the diversity of tools HUSKY requires, so HUSKYQA, a new evaluation set, was created to test mixed-tool reasoning. This set includes tasks that require retrieving missing knowledge and performing numerical reasoning. Despite using smaller models, HUSKY matches or surpasses frontier models like GPT-4, demonstrating its effectiveness.
HUSKY was trained and evaluated alongside other baseline language agents on a variety of tasks requiring multi-step reasoning and tool use. Half of these tasks were used to train HUSKY’s modules based on their tool-integrated solution paths, while the other half were reserved for evaluation. All tasks were assessed in a zero-shot manner.
1) Numerical Reasoning Tasks
The numerical reasoning tasks included mathematics datasets ranging from elementary to high school competition levels. These datasets comprised GSM-8K, MATH, Google DeepMind mathematics tasks, and MathQA, taken from the LILA benchmark. For Google DeepMind mathematics, the focus was on Algebra, Basic Math, Calculus, Multiplication/Division, and Number Theory subsets. For MathQA, subsets included Gain, General, Geometry, Physics, and Probability. GSM-8K and MATH were used for training, providing a total of 13.7K tool-integrated solution paths.
2) Tabular Reasoning Tasks
Tabular reasoning tasks involved TabMWP, a dataset of tabular math-word problems, FinQA and TAT-QA, both finance question-answering datasets, and a subset of test questions from MultimodalQA, which required understanding both text and tabular data. TabMWP and FinQA were used for both training and evaluation, while TAT-QA and MultimodalQA were held out for evaluation. These datasets contributed a total of 7.2K tool-integrated solution paths.
3) Knowledge-based Reasoning Tasks
Knowledge-based reasoning tasks included HotpotQA, CWQ, Musique, Bamboogle, and StrategyQA. HotpotQA and Bamboogle were reserved for evaluation, CWQ and Musique were used for training, and StrategyQA was used for both. This collection resulted in a total of 7K tool-integrated solution paths.
Models
The evaluation included the following models:
Action Generator: For the action generator, HUSKY utilized LLAMA-2–7B, 13B, and LLAMA-3–8B models. Incorrect solution paths were removed from the training set, resulting in 110K instances across numerical, tabular, knowledge-based, and mixed-tool reasoning tasks. The action generator was fully fine-tuned on this multi-task training set.
Code Generator: The DEEPSEEKCODER-7B-INSTRUCT-V1.5 model, known for its robust coding abilities, was selected as the base for fine-tuning the code generator. Correct solution paths were used to extract all necessary code, resulting in 44K code instances for training.
Math Reasoner: The DEEPSEEKMATH-7B-INSTRUCT model was chosen for its advanced mathematical reasoning capabilities. Correct solution paths provided 30K math solution instances for fine-tuning the math reasoner.
Query Generator: For the query generator, LLAMA-2–7B was used as the base model. Correct solution paths yielded 22K search query instances for fine-tuning the query generator.
Some of the results are illustrated in the following matrix:
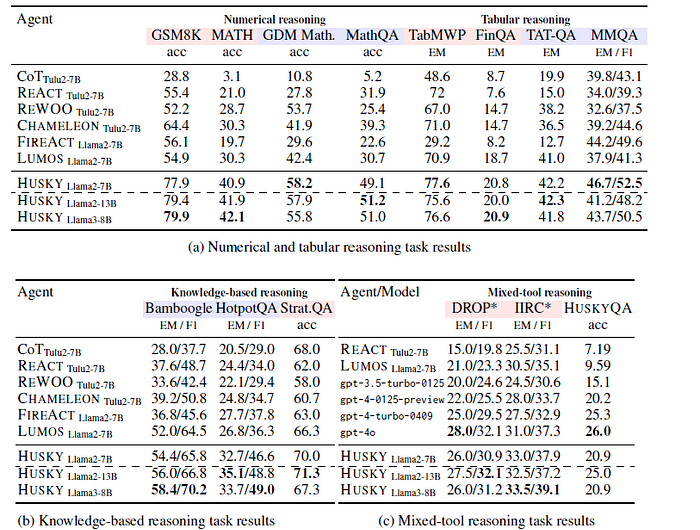
HUSKY represents a significant advancement in language agents, offering a versatile, open-source solution for complex reasoning tasks. Its holistic approach, combining action generation and execution with expert models, allows it to handle diverse challenges effectively. HUSKY’s performance, as seen in various evaluations, highlights its potential to redefine how language agents tackle complex problems.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Take our 90+ lesson From Beginner to Advanced LLM Developer Certification: From choosing a project to deploying a working product this is the most comprehensive and practical LLM course out there!
Towards AI has published Building LLMs for Production—our 470+ page guide to mastering LLMs with practical projects and expert insights!

Discover Your Dream AI Career at Towards AI Jobs
Towards AI has built a jobs board tailored specifically to Machine Learning and Data Science Jobs and Skills. Our software searches for live AI jobs each hour, labels and categorises them and makes them easily searchable. Explore over 40,000 live jobs today with Towards AI Jobs!
Note: Content contains the views of the contributing authors and not Towards AI.
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



