



Trends in AI — March 2023
Last Updated on July 25, 2023 by Editorial Team
Author(s): Sergi Castella i Sapé
Originally published on Towards AI.
LLaMA from Meta, an embodied PALM-E model from Google, Consistency Models, and new OpenAI API endpoints plus juicy pricing for ChatGPT: 0.002$/1k tokens.
The fast-paced development of Large Language Models keeps defining this first part of 2023. This month we’ve seen OpenAI releasing its ChatGPT API at 1/10th of the price of the full DaVinci endpoints, and other big tech Meta and Google release some of their latest models (LLaMA and UL2). Moreover, we got to play with Anthropic’s Claude using the Poe app and even though it’s still not publicly released, we were pleasantly surprised by its capabilities and how it’s totally on par with ChatGPT. Fierce competition in the space of chatbots will give us choices and force them to become better and cheaper.
Generative AI startups are taking off, and the rush to invest is stronger than ever. Here’s a comprehensive market map of the space with companies and investors by Ollie Forsyth.
U+1F52C Research
That said, let’s dive into the research! Every month we analyze the most recent research literature and select a varied set of 10 papers you should know. This month we’re covering topics such as Multimodal Language Models, Diffusion Models, Machine Translation, and more.
1. LLaMA: Open and Efficient Foundation Language Models
By Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample
U+2753 Why → A new set of base checkpoints to build upon. Well, if you work in academia!
U+1F4A1 Key insights → These new language models from Meta are pretty boring to be fair: the standard Transformers with rotatory position embeddings, trained on just over a Trillion tokens. You can see the architecture specs below:
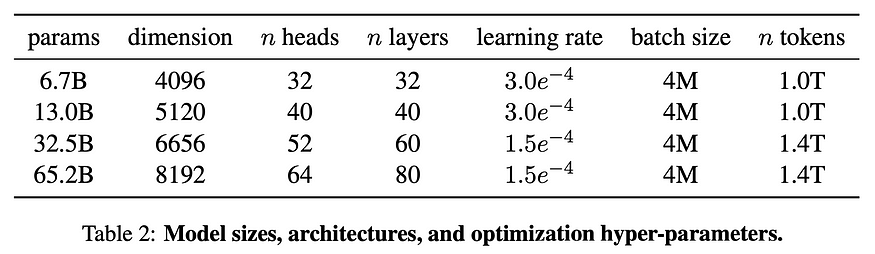
These models are trained on fully public data, and they manage to achieve strong performance on a variety of QA and Common Sense Reasoning tasks both in zero and few-shot.

However, we’ve played around with the 7B model, and it’s hard to make it do what you want to do. These models are neither instructed tunned nor RLHF’d, and it shows when it comes to how hard it is to interact with them.
Another point of controversy has been the fact that Meta has released this model solely for non-commercial research purposes, which strongly limits its applicability. Still, the checkpoints are out there in the world for people to play around and tinker with. If you want to know more about it, you can check out Yannic’s video on it.
Finally, one of the most interesting points is the fact that the decoding strategy for these models can have a huge impact on their usability, as @theshawwn points out on Twitter: increasing beam_search top_k, setting the temperature at 0.7 and repetition penalty at 0.85 produces noticeably better results!
2. Consistency Models U+007C Unofficial implementation
By Yang Song, Prafulla Dhariwal, Mark Chen, Ilya Sutskever.
U+2753 Why → Diffusion Models are expensive computationally cause they need to decode the output iteratively many times.
U+1F4A1 Key insights → Diffusion Models have been notorious for not needing to be outrageously big in terms of parameters to produce state-of-the-art results. This is because they are applied dozens of times iteratively, unrolling their computational graph to be much more expressive than what a single forward pass would allow. But that makes them slow, unlike GANs, VAEs, or Normalizing Flows.
This work proposes to learn a model that predicts the output of a diffusion process at an arbitrary depth level (see figure below).

The key insight into building these models is the realization that any jump f(x, t) needs to be consistent with the composition of its steps; when going from noise to data, different jumps need to end up in the same image; that is they need to be consistent, hence the name.
Previously, Progressive Distillation had shown a method to distill Diffusion Models into ones that required many fewer decoding steps (e.g., only 4), but in this work, a method for training standalone Consistency Models is proposed. The results on small images are not jaw-dropping but certainly promising for future research.

3. PaLM-E: An Embodied Multimodal Language Model
By Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, Pierre Sermanet, Daniel Duckworth, Sergey Levine, Vincent Vanhoucke, Karol Hausman, Marc Toussaint, Klaus Greff, Andy Zeng, Igor Mordatch, Pete Florence.
U+2753 Why → The latest incarnation of robots x LMs.
U+1F4A1 Key insights → Physical robots can only learn from a few samples because their training is not scalable (unless you do simulations, but they’re just not as expressive), and LMs encode powerful expressive priors and allow for very efficient learning via prompts. Why not use them together?
This thread was initiated by “Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents”, and this work takes a similar idea to the next level. Conceptually, it’s simple: tokenize images, states, and language into a shared vocabulary, then train a joint model for next-token prediction. To encode images, they use the Vision Transformer (ViT) and to encode text PaLM, both from Google and up to a combined 562 billion parameters (22B + 540B respectively).
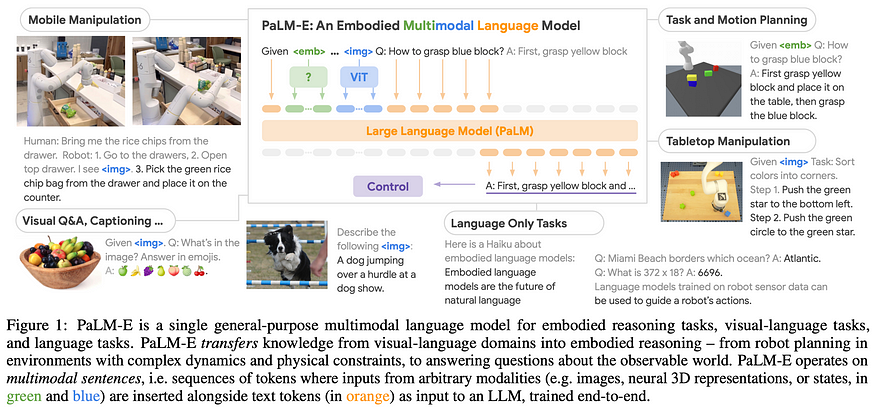
While this work sells itself as being an end-to-end solution, the truth is that robot control still heavily relies on traditional techniques, and the language model only provides high-level action instructions.
This results in strong visual question answering and reasoning performance, but perhaps the most relevant results are positive transfer: joint modality performance greatly surpassing the performance of models trained on each modality independently. While no strong positive transfer was exhibited by the similar GATO (which was vision + language + actions but not in the physical world), PaLM-E shows once again the relevance of scale when it comes to the emergence of certain phenomena.

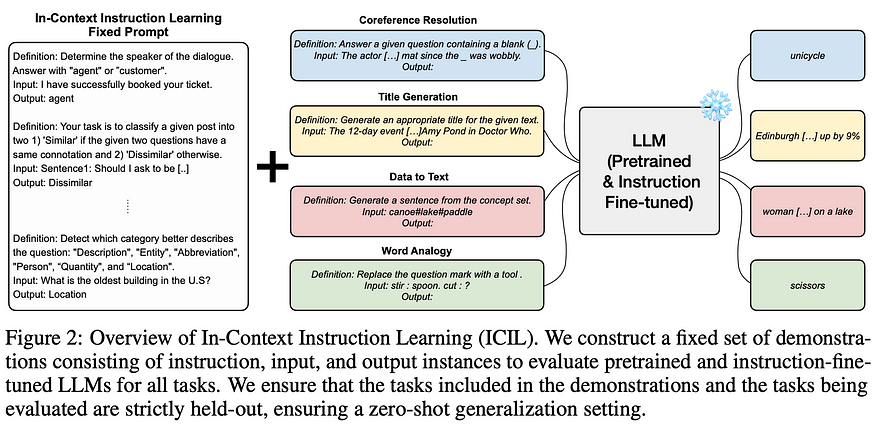
4. In-context Instruction Learning
By Seonghyeon Ye, Hyeonbin Hwang, Sohee Yang, Hyeongu Yun, Yireun Kim, Minjoon Seo.
U+2753 Why → Instruction tuning can also be done in the prompt!
U+1F4A1 Key insights → Instruction tuning is the technique of including labeled datasets in the training corpus in a natural language instruction format, which has been shown to generalize beyond the training tasks and into new tasks and make LMs more usable when humans give instructions.
This paper investigates what happens when you do this in the prompt; instead of adding examples of the task at hand (i.e., few-shot learning), you give it examples of a variety of other language tasks, then prompt it to perform a novel task.
TL;DR, this actually works! The necessary disclaimer is that you need to be careful about how you do it, and it’s not as simple as the “let’s think step by step” trick… But still, this is once again evidence that very complex information can be introduced with in-context learning, and the space of prepended fixed prompts has only just begun. These are prompts that are hidden to users have become an essential tool for building products with LMs as ChatGPT and Sydney from Microsoft have shown us.
5. How Good Are GPT Models at Machine Translation? A Comprehensive Evaluation U+007C Code
By Amr Hendy, Mohamed Abdelrehim, Amr Sharaf, Vikas Raunak, Mohamed Gabr, Hitokazu Matsushita, Young Jin Kim, Mohamed Afify, and Hany Hassan Awadalla.
U+2753 Why → One of the most underappreciated skills of ChatGPT was translation. Now this is put under rigorous evaluation.
U+1F4A1 Key insights → The overall gist of it is that GPT models perform close to SOTA and traditional machine translation models (of course with many caveats, but you’ll have to read the paper for that). However, one of my favorite takeaways from this work is that existing Neural Machine Translation and GPT based translation show complementary strengths.
Given that it wasn’t trained on parallel corpora, it avoids its common pitfalls such as problems with data memorization of noisy or low-quality samples, or long-tailed errors such as translation of physical units or currencies which might appear very sparsely in the parallel corpora.
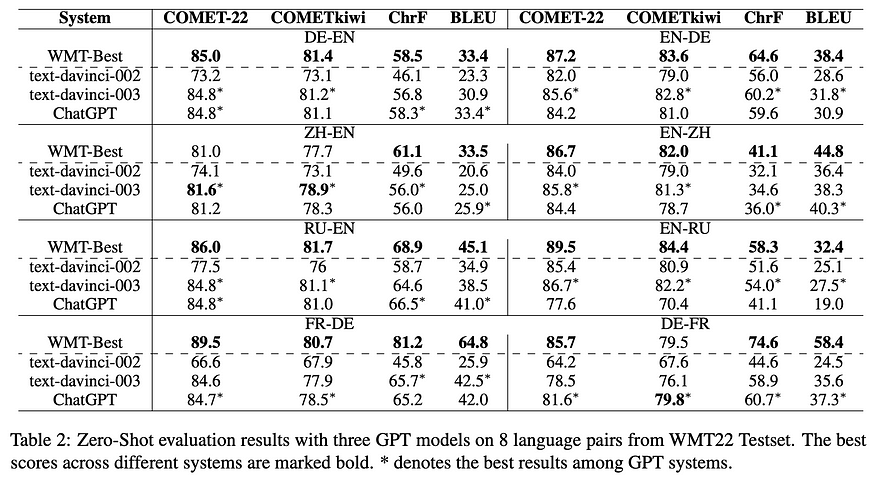
Overall, it’s still impressive and mindblowing that such translation performance can emerge largely from unsupervised pertaining, instruction tuning, and RLHF which wasn’t particularly targeted for translation.
6. Composer: Creative and Controllable Image Synthesis with Composable Conditions U+007C Project Page U+007C Code
By Lianghua Huang, Di Chen, Yu Liu, Yujun Shen, Deli Zhao, Jingren Zhou.
U+2753 Why → One of the foundational strengths of Diffusion Models is their convenience when it comes to training with conditioning data, which is why they are so successful in a text-guided generation. This work takes controllability to the next level.
U+1F4A1 Key insights → The authors develop a method that allows for a wide range of image attributes to be controlled during image generation: spatial layout, color palette, style, intensity, etc.
Compositionality is the core idea behind this model, which decomposes images into representative factors, and then uses a diffusion model to recompose the input when conditioned with these factors. The elements into which images are decomposed are caption (text), Semantics and style (via CLIP embedding), Color (via histogram statistics), sketch (via an edge detection model), instances (i.e., object segmentation), depthmap (via a pretrained monocular model), intensity (via grayscale image), and masking. Thus, image generation can be conditioned to all these attributes and can be iteratively refined with the previous output as a new conditioning input.

This work demonstrates how image generation technology can be designed to give more control to human creativity, and elevate the creative process instead of replacing it.
7. Prismer: A Vision-Language Model with Multi-Modal Experts
By Shikun Liu, Linxi Fan, Edward Johns, Zhiding Yu, Chaowei Xiao, Anima Anandkumar
U+2753 Why → The return of expert systems..? I like this paper cause it’s a departure from the end-to-end raw computing revolution. That’s not to say I’m bearish on the bitter lesson, but it’s still refreshing.
U+1F4A1 Key insights → Not quite, but this paper takes a quite structured approach to multimodal language modeling and comes out with some convincing benefits:
- The paper takes a structured approach to multimodal language modeling and achieves comparable performance with one or two orders of magnitude fewer data compared to other models.
- “Experts” refer to frozen computer vision models that output information such as depth maps or object segmentations when processing an image. Only adaptors are trained, allowing the design to plug and play with other black-box vision models.
- The largest Prismer model has 1.6B parameters with only 360M trainable ones, resulting in less performance but greater efficiency than massive models.
- Prismer shows strong robustness to noisy experts and improves with more/higher-quality experts, suggesting its practicality for multi-modal learning at scale.

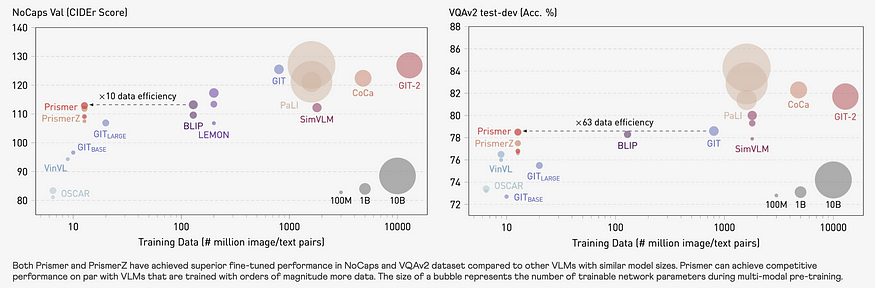
Overall, the paper presents an effective technique for safely including many modality experts without degrading performance, enabling a practical approach to scaling down multi-modal learning. For another work on multimodal language models, see “Language Is Not All You Need: Aligning Perception with Language Models” from Microsoft, which tunes a vision-language model with instruction learning.
8. Augmented Language Models: a Survey
By Grégoire Mialon, Roberto Dessì, Maria Lomeli, Christoforos Nalmpantis, Ram Pasunuru, Roberta Raileanu, Baptiste Rozière, Timo Schick, Jane Dwivedi-Yu, Asli Celikyilmaz, Edouard Grave, Yann LeCun, Thomas Scialom.
U+2753 Why → We have witnessed an explosion of proposed approaches for enhancing language models with memory, reasoning, and tools. This article is your one-stop shop to stay up-to-date on the latest developments in this space.
U+1F4A1 Key insights → LMs are famously limited when it comes to robust reasoning and accuracy, which is why there is an active area of research to augment them with computational devices that enhance their abilities. For instance, LMs that use calculators, compile and run generated code, or call arbitrary APIs to gather data. The space has just gotten started.
Retrieval Augmented Generation (RAG) is one of the most common cases (we use it on our platform, and both Bing and Google are actively working on it). Here, for instance 4 works that look into Retrieval Augmented LMs (RAGs) and how they compare:

One of the interesting points made by the survey is that augmenting LMs with tools and explicit structure makes them more interpretable, given that their output can be attributed explicitly to its modules, which makes them more usable by humans.
9. Symbolic discovery of optimization algorithms
By Xiangning Chen, Chen Liang, Da Huang, Esteban Real, Kaiyuan Wang, Yao Liu, Hieu Pham, Xuanyi Dong, Thang Luong, Cho-Jui Hsieh, Yifeng Lu, Quoc V. Le.
U+2753 Why → Adam has been king for way too long. Is there any way we’ll get rid of it? Probably not, but this could still be useful!
U+1F4A1 Key insights → The method is called Lion (evolved sign moment) and the handwavy gist of it is that you can apply symbolic program search to learn a trainer function that outputs updated weight values given weights, gradients, and learning rates of a network.
This work contributes to the space of learned optimizers with the twist that the learned optimizer here is not learned via gradient descent but via symbolic discovery. This method works very well in the experiments showcased in the paper, achieving around 2x training speedups when compared to commonplace vanilla optimizers such as Adam.
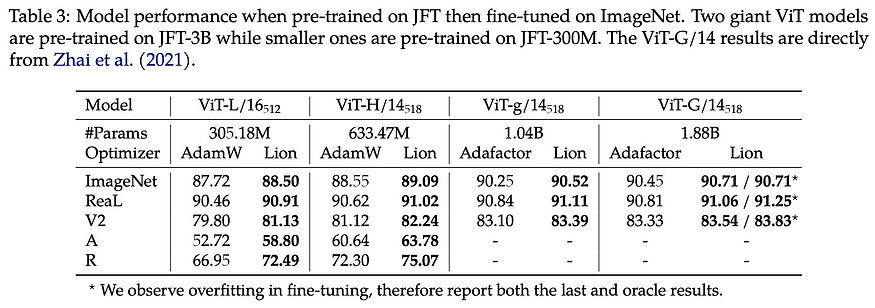
However, as usual with these papers, it’s very hard to assess the most important feature of optimizers: convenience. Adam is not the chosen optimizer because it always works best and most efficiently but because it works well enough most of the time, and relevant bottlenecks are elsewhere. That said, I would love to see learned optimizers take off and become the new defacto for challenging unstable learning scenarios such as 100 billion scale language models.
10. MarioGPT: Open-Ended Text2Level Generation through Large Language Models
By Shyam Sudhakaran, Miguel González-Duque, Claire Glanois, Matthias Freiberger, Elias Najarro, Sebastian Risi.
U+2753 Why → A fun one! Using GPT-2 to generate Mario Bros worlds.
U+1F4A1 Key insights → That’s pretty much it. The authors do Procedural Content Generation (PCG, the idea of generating content for games algorithmically) by tokenizing elements of Mario Bros into characters and training a language model that is then conditioned on text prompts.
They further increase the diversity of generated levels with evolutionary computing, embedding MarioGPT into a novelty search loop that samples existing levels, mutates them, and applies selection criteria to keep or discard them.
The resulting levels are playable 88% of the time and display high controllability via text prompting. This is only an exciting start to potentially more expressive and personalized gaming experiences!


This month’s selection is all wrapped up — if you want to stay ahead of the curve, give us a follow on Twitter @zetavector and stay tuned for next month’s picks!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")