



Gradient Checkpointing
Last Updated on July 25, 2023 by Editorial Team
Author(s): Harshit Sharma
Originally published on Towards AI.
To “scale” new heights in model training
Gradient Checkpointing (aka Re-compute technique/activation checkpointing) is an approach that trades compute for memory and is helpful in scenarios where the available GPU memory is not enough to accommodate a large model. It was published originally in 2016 [Link]
In Short #7 U+007C What is Gradient Accumulation ?, we learned how to train a model with a large enough batch size in spite of low GPU memory.
But what if the model is large enough, and we can’t use even a batch size of 1?
Gradient checkpointing helps here by decreasing the memory footprint required for executing the model. So even if a large model outsizes the GPU, we still have a silver lining.
It does this dynamically by NOT storing all the intermediate activations during the forward pass, thereby saving precious memory.
Let’s take an example with a computation graph with A1 and A2 as the intermediate activations.

Instead of pre-computing both A1 and A2, it skips computing A1 during the forward pass.
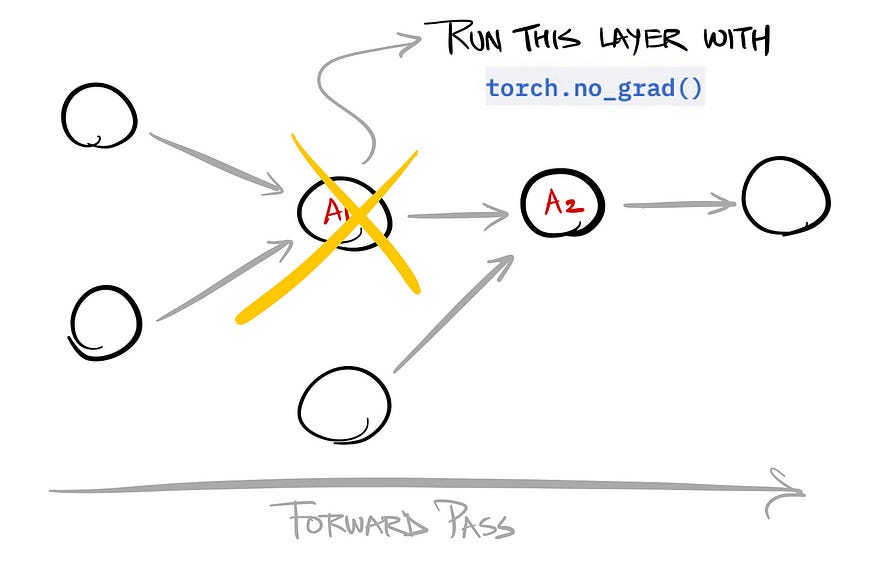
Running with torch.no_grad() ensures that intermediate activations are not stored for those parameters.
It’s only during the backward pass, that the skipped activations are calculated. And this makes the backward pass slower, but while saving some memory.
The slowdown in speed is 20%, but the memory cost, as per the paper, is transformed as:
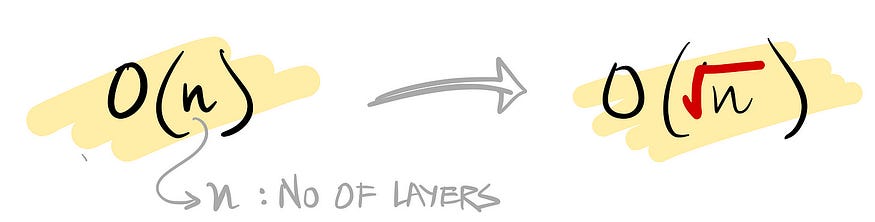
Which layers are checkpointed?
It is implemented internally in Pytorch and other deep-learning frameworks. But one of the ideas from the papers recommends:

This is so that the speed of backward passes is not hampered much, and the calculations are still computationally cheap.
How to implement it?
In PyTorch, it has got a simple checkpoint API:

Tensorflow users can checkout here
References:
Hope you enjoyed this !!
Originally Published at Intuitive Shorts:
Short #9 U+007C Gradient Checkpointing
To scale new heights in model training
intuitiveshorts.substack.com
Follow Intuitive Shorts (a Free Substack newsletter), to read quick and intuitive summaries of ML/NLP/DS concepts.

Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

