



How To Create an End-2-End Text Paraphrase App
Last Updated on January 1, 2023 by Editorial Team
Author(s): Stavros Theocharis
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Create a paraphrase app with FastAPI or Streamlit and Docker
The internet is home to a myriad of innovative AI tools that are available for use today. If you do a search on Google using the key phrase “paraphrasing tools,” you will observe that a significant number of results are returned.
But how exactly does one go about developing their very own simple app to perform the function of paraphrasing? In this piece of writing, I will explain how to construct such an app in two distinct ways, each of which has its own advantages. The first approach is to make use of the FastAPI, while the second approach is to make use of Streamlit. The two approaches are completely independent and are used as two different examples. They only use the same paraphrasing pipeline. In the end, I additionally include the components required for the creation of the relevant Docker images.
I have already set up a new repository on GitHub, and all of the components that are being discussed here can be found there in their fully operational state. Because I like to give the names of my projects that seem like products, I decided to call this one “Quotera.”
Paraphrasing models
In order to proceed with paraphrasing algorithms, a dedicated AI model is mandatory. Hugging Face offers a wide variety of versions to accommodate a diverse range of scopes. The use of a model obtained through Hugging Face is made simple by the creation of an account and a token. In addition to that, in order to put the paraphrase feature into action for this project, I made use of the Parrot Paraphraser package.
Even though the pre-trained model this package uses is called “prithivida/parrot_paraphraser_on_T5”, other pre-trained or custom models can be used instead.
You may use the following code to log in to Hugging Face, which will also give you access to the model:
from huggingface_hub import HfApi
from huggingface_hub.commands.user import _login
from parrot import Parrot
token = "your_token"
_login(HfApi(), token=token)
parrot_model = Parrot()
Paraphrasing pipeline
It is needed to provide the requisite functionality to generate paraphrased text from a source text. The following parameters (also sourced from the Parrot library) are utilized as a baseline by the vast majority of paraphrase products on the market today:
adequacy threshold: How much of the meaning is preserved adequately.
fluency threshold: How much of the paraphrased text will be fluent in the specific language.
diversity ranker: Based on the different diversity rankers, how much has the paraphrase changed the original sentence (lexical, / phrasal / syntactical).
The diversity ranker may take on values like “levenhstein”, “eyclidean”, and “diff” based on the algorithm used to determine the similarity distance between texts, while the adequacy and fluency thresholds can take on values between 0 and 1.
The class Parrot has a function labeled “augment” that may be used to generate potential paraphrases of text. It requires a distinct invocation for each phrase since it operates at the sentence level. It produces a list of tuples as output. An additional set of paraphrased text is represented by each tuple as the first value. As for the second value, it’s the diversity score comparing the paraphrased text to the original.
For example, we have the following original text:
text = "An internal combustion engine (ICE or IC engine) is a heat engine."
And the output is:
[('an ice - or ic - engine is a heat engine', 41), ('an ice or ic engine is a heat engine', 40), ('an ice or ic engine is an internal combustion engine that acts as a heat engine', 36), ('an internal combustion engine ice or ic engine is a heat engine', 13)]
Since I don’t always like the provided diversity score when picking a fresh, original phrase, I’ll be making use of a new function made from the fuzz partial ratio from the fuzzywuzzy library:
from fuzzywuzzy import fuzz
def check_text_similarity(first_text: str, second_text: str) -> float:
"""
Checks similarity between 2 given texts based on the fuzz partial ratio
"""
return (
fuzz.partial_ratio(
first_text,
second_text,
)
/ 100
)
And the function that should be used for all the new sentences that are being compared to the original is:
def get_most_diverse_text(original_text: str, text_variations_list: List) -> str:
"""
Get an original text and compare it with text variations coming as a list.
kept_sentence: Str text coming as the least similar to the original text
"""
similarity_list = []
for temp_dif_sentence in text_variations_list:
temp_text_similarity = check_text_similarity(
original_text, temp_dif_sentence[0].capitalize()
)
similarity_list.append(temp_text_similarity)
min_index = similarity_list.index(min(similarity_list))
kept_sentence = text_variations_list[min_index][0].capitalize()
kept_sentence = kept_sentence + ". "
return kept_sentence
Keep in mind that the library operates on a per-sentence basis, which means that we need to break the text up into sentences and run it individually for each one.
After then, we are free to pick which one to keep based on our approach. The most diverse sentences are kept here (other tools keep them all and let the user hover over the sentences to choose their preferred one in a corresponding UI).
The main paraphrase function is:
def create_paraphrase(
parrot_model: Parrot,
text: str,
adequacy_threshold: float = 0.75,
fluency_threshold: float = 0.90,
diversity_ranker: str = "levenshtein",
) -> Dict[str, str]:
"""
Creates the new paraphrased text
"""
logging.info("Tokenising text.........")
sentences = re.split('[,.!?;]', text)
new_text = ""
logging.info("Creating paraphrased text for each sentence.........")
for sentence in sentences:
dif_sentences = parrot_model.augment(
input_phrase=sentence,
diversity_ranker=diversity_ranker,
adequacy_threshold=adequacy_threshold,
fluency_threshold=fluency_threshold,
)
if dif_sentences != None:
kept_sentence = get_most_diverse_text(sentence, dif_sentences)
new_text = new_text + kept_sentence
return {
"text": new_text
}
Creation of the FastAPI app

First of all, why have an API for paraphrasing?
The answers vary, but one that is consistent is that once you have the paraphrase pipeline, the next question is how someone or something can make use of it. Perhaps there is another service or more than one service that needs to send text requests and get back the paraphrased text.
If you are thinking of scalability, you are right! It plays an important role in this situation, and given the amount of time required to run the entire pipeline, it is unable to support a large number of requests with the current implementation, but this code is only the basis.
What is FastAPI?
Built on top of the standard Python type hints, the contemporary web framework known as FastAPI is designed to facilitate the creation of application programming interfaces (APIs) using Python versions 3.7 and above.
Here, the fundamental components will be outlined, however further information may be discovered inside the repository.
Implementation
So, firstly, let’s define the two basic schemas, which are the input and output classes, using the most common “pydantic” library:
from pydantic import BaseModel
from typing import Optional, List, Literal
class ItemBase(BaseModel):
"""Base entity"""
pass
class TextIn(ItemBase):
text: str
adequacy_threshold: float
fluency_threshold: float
diversity_ranker: str
class TextOut(ItemBase):
text: str
In order to receive the input data and have it in the suitable format, it is further essential to utilize an encoder and to develop the transformation function:
from fastapi.encoders import jsonable_encoder
def transform_input_data(data):
encoded_data = jsonable_encoder(data)
return encoded_data
def get_transformations(
body: TextIn,
) -> Tuple[str, float, float, str]:
transformed_text = transform_input_data(body.text)
transformed_adequacy_threshold = transform_input_data(body.adequacy_threshold)
transformed_fluency_threshold = transform_input_data(body.fluency_threshold)
transformed_diversity_ranker = transform_input_data(body.diversity_ranker)
return (
transformed_text,
transformed_adequacy_threshold,
transformed_fluency_threshold,
transformed_diversity_ranker,
)
Create the API’s endpoint:
from fastapi import APIRouter
paraphrase_analytics_router = APIRouter()
@paraphrase_analytics_router.post(
"/text/paraphrase",
tags=["Text Paraphrase"],
summary="Paraphrase text based on each phrase",
response_description="Paraphrased text",
response_model=TextOut,
)
async def paraphrase_text(body: TextIn):
"""
Use this route to paraphrase text.
"""
logging.info("Triggering paraphrase pipeline")
(
transformed_text,
transformed_adequacy_threshold,
transformed_fluency_threshold,
transformed_diversity_ranker,
) = get_transformations(body)
logging.info("Processing & paraphrasing text")
paraphrased_text = create_paraphrase(
parrot_model,
transformed_text,
transformed_adequacy_threshold,
transformed_fluency_threshold,
transformed_diversity_ranker,
)
end = time.time()
return paraphrased_text
CLI part:
@app.command()
def serve(env: "dev", host: str = "0.0.0.0"):
typer.echo(f"\nRunning Quotera API | Environment: {env} 🚀 \n")
typer.echo(cprint(figlet_format("Quotera", font="doom"), "green", attrs=["bold"]))
os.system(
f"ENV_FILE='.env.{env}' GUNICORN_CMD_ARGS='--keep-alive 0' uvicorn src.main:quotera --reload --host {host}"
)p
By running the serve command, we can have our app running at http://0.0.0.0:8000.
If you are directly using the code inside the repository, please refer to the README.md file in order to follow the instructions.
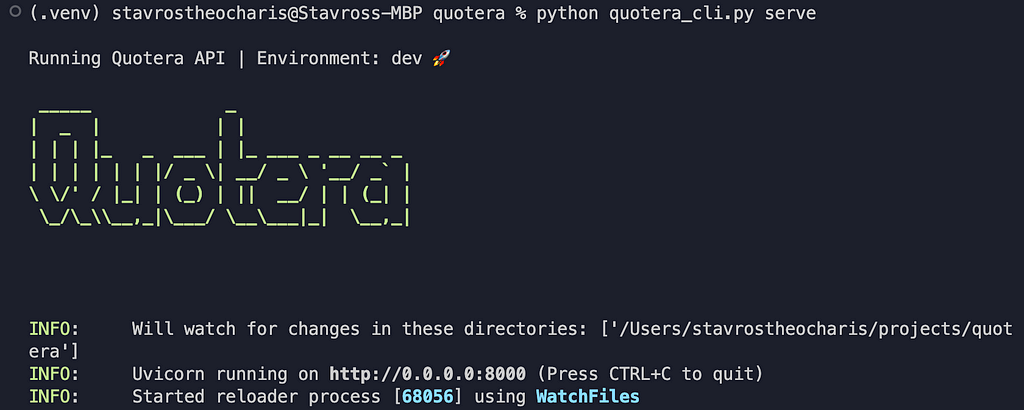
The endpoint can be found at http://0.0.0.0:8000/docs
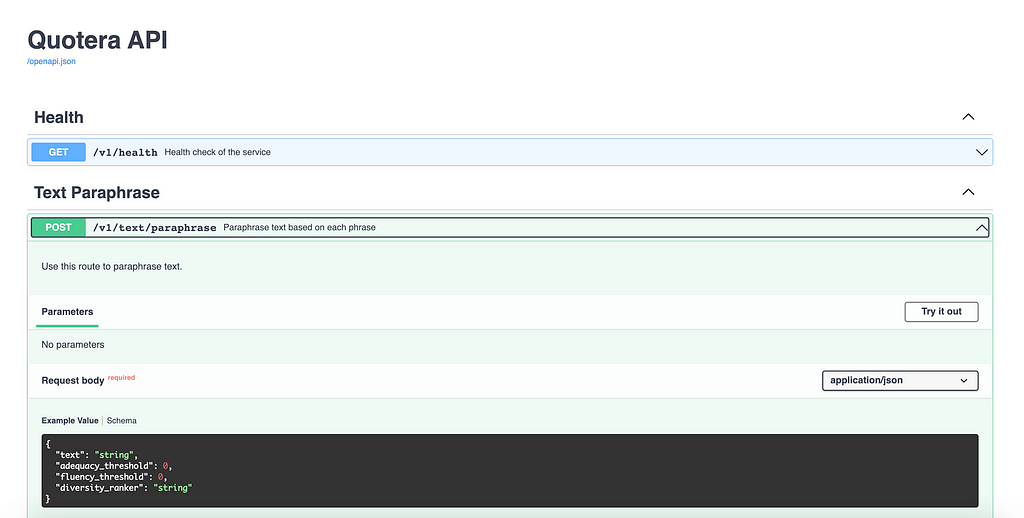
By pressing “Try it out” you can give your own text and parameters and check it out.
Creation of the Streamlit app

What is Streamlit?
Streamlit is a free and open-source framework that enables developers to easily construct and distribute online applications for machine learning and data science. It is a library written in Python that was developed with the machine learning developers’ needs in mind.
In my opinion, Streamlit is a very good tool for rapid prototyping, and it may also be helpful when someone wants their analytics, etc. to be turned into a UI form.
Implementation
In order to visualize the results in a nice way, let’s create a basic card:
import streamlit as st
def card(paraphrased_text):
st.markdown(
f"""
<div class="card text-white bg-dark mb-3" style="max-width: 280rem;">
<div class="card-body">
<p class="card-text">{paraphrased_text}</p>
</div>
</div>
""",
unsafe_allow_html=True,
)
Let’s create the basic part of the dashboard (the config readme file and the util function can be found inside the repository):
st.set_page_config(page_title="Quotera", layout="wide")
readme = load_config("config_readme.toml")
with st.spinner(
"Loading and geting ready the AI models (this action may take some time)..."
):
parrot_model = get_model()
# Info
st.title("Paraphrase Text")
# Parameters
st.sidebar.title("Parameters")
adequacy_threshold = st.sidebar.slider(
"Select adequacy threshold",
0.0,
1.0,
step=0.01,
value=0.90,
help=readme["tooltips"]["adequacy_threshold"],
)
fluency_threshold = st.sidebar.slider(
"Select fluency threshold",
0.0,
1.0,
step=0.01,
value=0.90,
help=readme["tooltips"]["fluency_threshold"],
)
diversity_ranker = st.sidebar.selectbox(
"Select diversity ranker",
("levenshtein", "euclidean", "diff"),
help=readme["tooltips"]["diversity_ranker"],
)
# Text loading
text, button = input_text(readme)
# Paraphrase generation
with st.spinner("Generating Paraphrased text.."):
if button and text:
paraphrased_text = create_paraphrase(
parrot_model,
text,
adequacy_threshold=adequacy_threshold,
fluency_threshold=fluency_threshold,
diversity_ranker="levenshtein",
)["text"]
st.markdown(
"""
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.1.3/dist/css/bootstrap.min.css" rel="stylesheet" integrity="sha384-1BmE4kWBq78iYhFldvKuhfTAU6auU8tT94WrHftjDbrCEXSU1oBoqyl2QvZ6jIW3" crossorigin="anonymous">
""",
unsafe_allow_html=True,
)
st.write(card(paraphrased_text["text"]))
st.download_button("Download .txt", paraphrased_text["text"])
CLI part:
import os
import sys
from streamlit.web import cli
def deploy_streamlit():
sys.argv = [
"streamlit",
"run",
f"{os.path.dirname(os.path.realpath(__file__))}/dashboard.py",
"--server.port=8060",
"--server.address=0.0.0.0",
]
sys.exit(cli.main())
By running the “deploy_streamlit” command, we can have our app running at http://0.0.0.0:8060.
If you are directly using the code inside the repository, please refer to the README.md file in order to follow the instructions.

And our app in the browser is as follows:
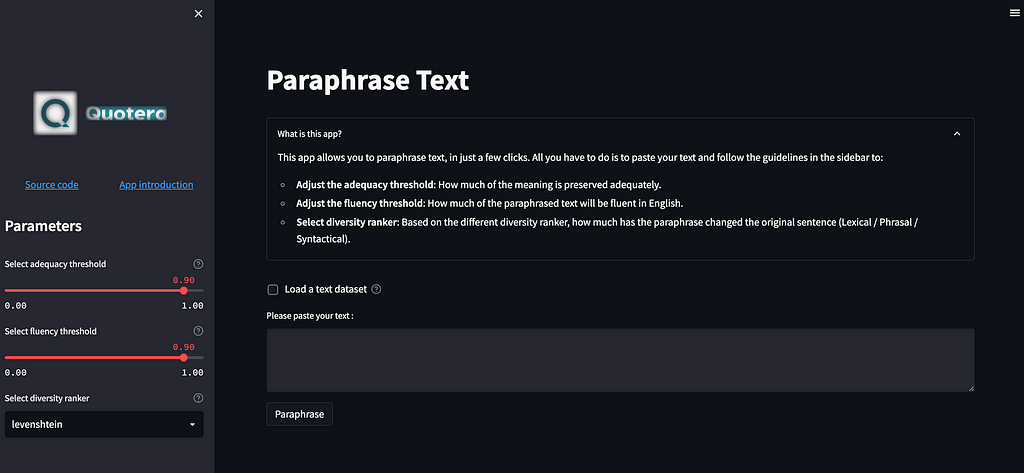
Dockerize our apps

What is Docker?
Docker is a platform that is available for free that may be used to build, deploy, and manage containerized applications. Applications are referred to be containerized when they operate in what are known as containers and are isolated runtime environments. An application and all of its dependent components, such as system libraries, binaries, and configuration files, are encased inside a container together.
Implementation
The two above apps, FastAPI and Streamlit, are completely independent services. We can have two different dockerfiles, one for each service. Python 3.9 will be used as the base images. For more information, you can read the compose specification.
The chosen structure is the following:
├── docker-compose.yml
├── Dockerfile.api
└── Dockerfile.streamlit
For FastAPI we have the Dockerfile.api:
FROM python:3.9
# install project requirements
COPY requirements.txt requirements.txt
RUN pip install -r requirements.txt
RUN pip install git+https://github.com/PrithivirajDamodaran/Parrot_Paraphraser.git
COPY . .
EXPOSE 8000
ENTRYPOINT python ./quotera_cli.py serve
For Streamlit we have the Dockerfile.streamlit:
FROM python:3.9
# install project requirements
COPY requirements.txt requirements.txt
RUN pip install -r requirements.txt
RUN pip install git+https://github.com/PrithivirajDamodaran/Parrot_Paraphraser.git
COPY . .
EXPOSE 8000
ENTRYPOINT python ./quotera_streamlit_cli.py
In order to build the images a “docker-compose.yaml” file is needed:
services:
api:
build:
context: .
dockerfile: Dockerfile.api
ports:
- 8080:8080
volumes:
- ~/.cache/huggingface:/.cache/huggingface
streamlit:
build:
context: .
dockerfile: Dockerfile.streamlit
ports:
- 5000:5000
volumes:
- ~/.cache/huggingface:/.cache/huggingface
In order to create the two above docker images, just need to run “docker-compose up”.
Conclusion
This article demonstrated how to develop a tool for paraphrasing text using either the FastAPI or the Streamlit programming interfaces, as well as how to generate the relevant Docker images. The pipeline for generating paraphrases is based on a pretrained model that was obtained from Hugging Face; however, other variants may be utilized in its place.
You can get the code you need to follow along with the instructions at this link: https://github.com/stavrostheocharis/quotera
If you have any questions, you are more than welcome to post a comment or create an issue on Github.
How To Create an End-2-End Text Paraphrase App was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Take our 90+ lesson From Beginner to Advanced LLM Developer Certification: From choosing a project to deploying a working product this is the most comprehensive and practical LLM course out there!
Towards AI has published Building LLMs for Production—our 470+ page guide to mastering LLMs with practical projects and expert insights!

Discover Your Dream AI Career at Towards AI Jobs
Towards AI has built a jobs board tailored specifically to Machine Learning and Data Science Jobs and Skills. Our software searches for live AI jobs each hour, labels and categorises them and makes them easily searchable. Explore over 40,000 live jobs today with Towards AI Jobs!
Note: Content contains the views of the contributing authors and not Towards AI.
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



