



Zero-Shot Text Classification Experience with HuggingFace
Last Updated on December 31, 2023 by Editorial Team
Author(s): Claudio Giorgio Giancaterino
Originally published on Towards AI.
After my previous article, where I embarked on the journey into the Zero-Shot Text Classification task with Scikit-LLM library, leveraging the experience gained from GPT family models, I’m now continuing the same expedition. However, this time, I’m exploring other pre-trained models obtained from the Hugging Face Hub platform.
Let’s pause for a moment and delve into the story of Hugging Face.
Hugging Face was founded in 2016 by Clément Delangue, Julien Chaumond, and Thomas Wolf in New York City as a chatbot company, but they soon realized the potential of the underlying chatbot technology to democratize access to machine learning becoming a referent point for NLP. In 2018, they released the Transformer Library, a milestone that significantly shaped the company’s future. Expanding its developer tools, Hugging Face launched a platform hub in 2019 that allowed machine learning researchers and developers to share and try out pre-trained Large Language Models and others across various domains, moving from NLP to other areas of Artificial Intelligence. The Company has raised several significant funds, and today, with the last $ 235 million funding round, it is valued at $ 4,5 billion.
The Hugging Face Hub platform, comprising models, datasets, and demo app spaces, is designed to foster collaboration among machine learning engineers and data scientists. It provides resources for community members to discover, track, and deploy models in production environments.
For this leg of the journey, I’ve chosen DistilBERTa, DeBERTa, DistilBERT, and BART from the Hugging Face repository as my companions.
A brief glimpse of the models
Before delving into the results, it’s helpful to understand the differences between the GPT models used previously and the ones we’re exploring now. All mentioned models utilize the Transformer model but with different architectures. They are pre-trained on large datasets to learn representations of language.
In essence, the Transformer is a type of deep learning model that can process text or speech data in parallel. It employs the attention mechanism and is composed of an encoder-decoder structure. The task of the encoder is to map the input sentence, producing a vector representation fed into a decoder. The decoder receives the output of the encoder, along with the decoder output from the previous time step, to generate a conditional probability distribution of a target sentence. The attention mechanism assigns weights to each word in a sentence, predicting words likely to be used in sequence.
- GPT models (Generative Pre-trained Transformer) are based on the Transformer decoder, using self-attention to generate text from left to right. They are trained on a large corpus of text using a self-supervised task called autoregressive language modelling, which predicts the next word given the previous words. GPT models are unidirectional, relying on left context.
- DistilBERT represents the smaller and faster version of BERT, it uses a similar general architecture as BERT, but with fewer encoder blocks and employs the knowledge distillation technique during pre-training, which involves training a smaller model to mimic the behaviour of a larger model. BERT is an encoder stack of transformer architecture and it is trained on a large corpus of text using two self-supervised tasks: Masked Language Modelling (MLM) and Next Sentence Prediction (NSP). The first one predicts a randomly masked word given the rest of the sentence, the second predicts whether two sentences are consecutive or not. BERT is bidirectional, meaning it can use both left and right context to encode text.
- DistilBERTa is a scaled-down version of RoBERTa (Robustly Optimized BERT Pre-training Approach), which is an optimized version of BERT. RoBERTa uses the same architecture as BERT, but it uses more data, larger batches, longer training, and a dynamic masking technique during training that helps the model learn more robust representations of words. DistilBERTa is obtained by applying knowledge distillation to RoBERTa.
- DeBERTa (Decoding-enhanced BERT with disentangled attention) is an improvement of BERT and RoBERTa models using two novel techniques: disentangled attention and an enhanced mask decoder. Disentangled attention allows the model to learn from both the content and the position of the words, while an enhanced mask decoder improves the masked language modelling task by using the bidirectional context.
- BART is a sequence-to-sequence model, which uses both the Transformer encoder and the Transformer decoder and can generate text from text. BART is trained on a large corpus of text using a self-supervised task called denoising autoencoding, which reconstructs the original text from a masked version, where some words are randomly masked, deleted, or permuted. BART can use both left and right context to encode and decode text.
Practical Experience
After this little preview of friend models employed in the journey, we can go ahead with the zero-shot classification journey following this notebook and starting with the sentiment analysis on a financial data set based on 3 polarities: positive, neutral, and negative.

# Plot the target variable
# Create a figure with two subplots (axes) side by side
fig, axes=plt.subplots(ncols=2, figsize=(12,5))
# Create a pie chart of the sentiment counts on the first subplot
pieplot = df_1.groupby('Sentiment').count()['Sentence'].plot(kind='pie',ax=axes[0]).set_title("Pie Target Variable Distribution")
# Create a bar chart of the sentiment counts on the second subplot
barplot=sns.countplot(x='Sentiment', data=df_1, ax=axes[1]).set_title("Barplot Target Variable Distribution")
# Remove the y-axis label from the first subplot
axes[0].set_ylabel('')
# Display the figure
plt.show()
As we remember in the distribution of the target variable, the neutral sentiment is predominant.

To fit zero-shot classification requires little rows of code, given we can exploit the transformer pipeline from Hugging Face, and in the following example applied on DistilRoBERTa.
# transformer pipeline
# definition of the task and the model
classifier_1 = pipeline("zero-shot-classification",
model="cross-encoder/nli-distilroberta-base")
start= time.time()
# definition the sequence where to fit the model
sequence_to_classify = X.iloc[:]
# definition of the polarities of the output from the prediction
candidate_labels = ['negative', 'neutral', 'positive']
# build a loop to iterate the process
sent_list_distilroberta = []
for text in sequence_to_classify:
label = classifier_1(text, candidate_labels)
sent_list_distilroberta.append(label)
end=time.time()
print ({end - start})
With this data set, the best model is DeBERTa, with a good confusion matrix, meanwhile, the others are really poor in performance.

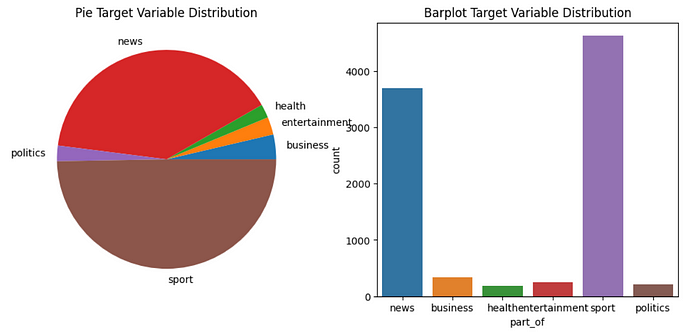
Turning into the second data set for multi-class text classification based on CNN news and 6 classes, we can see that “news” and “sport” classes are predominant. The column “part_of ” has been used as the target, and the “description” as the covariate.

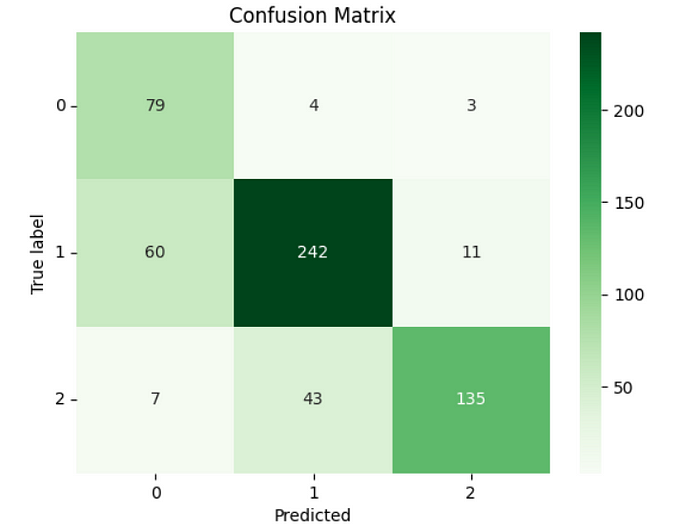
Looking at this second experience, DistilBERT is outperforming, anyway the other models competitively, except BART.
score_2 = {
'metrics':'f1_score',
'distillberta': distilroberta__f1_score,
'deberta': deberta__f1_score,
'distilbert': distilbert__f1_score,
'bart': bart__f1_score
}
score_2
score_data_2 = pd.DataFrame(score_2, index=[0])
score_data_2

The confusion matrix from DistilBERT shows a good allocation on the right diagonal by the predicted labels.
# confusion matrix
cm= confusion_matrix(df_2_p.part_of,df_2_p.predicted_labels_distilbert)
sns.heatmap(cm, annot=True, fmt='d', cmap=plt.cm.Greens, cbar=True)
plt.title("Confusion Matrix")
plt.xlabel('Predicted')
plt.ylabel('True label')
plt.yticks(rotation=0)
plt.show()

Final thoughts
Comparing GPT models with the latest ones using the same data sets
(applying zero-shot text classification to a stratified sample equal to 10% of the data set size), we observe a broader family of Large Language Models in action. Firstly, in this second experience, significant differences between models emerge based on the data set used, especially when considering the financial one. Instead, GPT models performed well in both situations. Secondly, model performance is directly linked to fine-tuning. DeBERTa shines with the financial data set due to training on 27 tasks, including the financial sector. DistilBERT excels with the CNN news dataset due to fine-tuning CNN articles. Thirdly, this experience reaffirms a general observation: smaller language models and finely tuned ones can match or outperform Large Language Models for specific tasks.
References
–Generative Pre-trained Transformer
–BERT
–BART
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")