



The Elements of Data-Centric AI
Last Updated on February 17, 2022 by Editorial Team
Author(s): Nilesh Raghuvanshi
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Pursuit of data excellence
In my last post, I provided an overview of Data-Centric AI. In this post, we will discuss individual elements of Data-Centric AI. Data-Centric AI is a systematic and principled approach towards data excellence by improving data quality throughout the lifecycle of a machine learning project. Data quality is a broad topic with solid roots in Data Engineering. Therefore, the elements of data-centric AI majorly contribute to measuring, engineering, and improving data quality.

First and foremost is data fitness. In a particular context, the fitness is determined by the suitableness of the data to answer a specific question. In other words, the degree to which the data at hand represents the phenomenon you are analyzing. Validity, reliability, and representativeness characterize the fitness of the data in question.
The validity of data is the extent to which it measures what it is supposed to. Within a dataset, the reliability of a given measure describes its accuracy and stability. Will the exact measurement taken multiple times under the same circumstances give us similar results every single time? Finally, representativeness is a means to measure if the sample you are working with is a true representative of the broader population to which you plan to apply your findings.
When the data does not fit the purpose, what happens is called Context Collapse, summarized well by this tweet.
Dear Amazon, I bought a toilet seat because I needed one. Necessity, not desire. I do not collect them. I am not a toilet seat addict. No matter how temptingly you email me, I'm not going to think, oh go on then, just one more toilet seat, I'll treat myself.
— Jacqueline (Jac) Rayner (@GirlFromBlupo) April 6, 2018

High-quality data is both fit for the purpose and is of high integrity. A high integrity data
- is always up-to-date
- is of known lineage, i.e., you have information on who compiled the data, what methods are used, and what was the original purpose for which the data was collected
- is supported by rich metadata to help interpret the information with details of technical characteristics and business context, e.g., for a visual inspection dataset, metadata for each image such as time, factory id, line id, camera settings, etc.

Another important element is Data Consistency. What does it mean when we say that your data needs to be consistent; e.g. if you’re dealing with time-series data, the frequency of records should be consistent. Say you’re collecting data every 1 sec or 5 sec, then your dataset should reflect that and, if not, deserves to be investigated for bugs with the data collection process itself.
Similarly, for text data, multiple spellings or abbreviations pointing to the same term should be normalized before being used. Consistency issues could also crop up due to inconsistent units of measure while aggregating the data from multiple sources or decoding the worth of something over a period, e.g., analyzing top-grossing movies over a decade.
Another important aspect here is data labeling consistency. As you know, ML algorithms basically learn the mapping between inputs and outputs. So, generally, it will be easier for your algorithm to learn the function if there is a deterministic mapping between your features and labels and your data is consistently labeled to reflect that mapping.
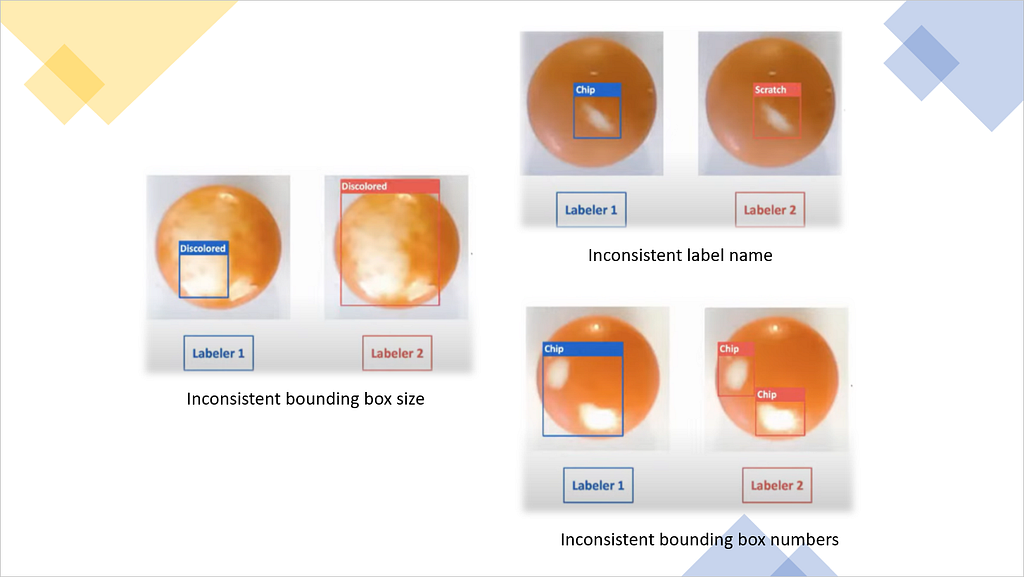

Data coverage is about coverage of important cases and especially the edge cases. Your dataset should have different variations of a given case. We want our data to be diverse and random, including variations on the problem we’re trying to solve.

Here’s an example is taken from a study where a neural network was trying to classify cows, camels, and polar bears. Now, as you can imagine, most of the training examples of the cow were taken when the cow is grazing, so with grass in the background. But when they started to evaluate the model with the same cow but different backgrounds like desert or snow, the model predicted those as Camel and Polar Bear, respectively.
Lack of variation in your data, especially concerning the non-causal feature, e.g., brightness (day/night) in a traffic light or background (grass, sand, or snow), can be detrimental to the model. It needs to be dealt with consciously using data-centric approaches like domain randomization or data augmentation. In short, we introduce random noise or variance in the data without changing the output so that the model will learn to develop the invariance to such features in the data.

BIG data comes with problems like expensive computation and labeling. Data selection techniques aim to help move away from BIG data to GOOD data and focus on quality rather than quantity. Again, this could be extremely valuable to industrial AI, where we often face data scarcity. Data selection techniques help answer questions like
- How do we efficiently identify the most informative training examples?
- Where do we add more data so that the performance impact is maximum?
Data selection or valuation is about quantifying the contribution of each data point to an end model. Such quantification could be helpful in various settings such as:
- Knowing the value of our training examples can help us guide in a targeted data collection effort when needed.
- Model explainability or debugging
- Discarding bad examples when such a subgroup is detected. As a side note, this can sometimes lead to ideas for new features to collect to reduce the impact of bad examples.
- When compensating individuals for their data contribution, a.k.a data dividend, e.g., search engine users contributing their browsing data or patients contributing their medical data

In my role as AI evangelist, I often get a question, “how much data do I need (to train a model)?” and I usually answer, “it depends!”. It is a reasonable question as gathering data is an expensive process. Data budgeting is beneficial when it comes to answering questions like
- What is the final performance of the ML model given enough training data? i.e., Predicting final performance
- What is the minimum amount of training data to reach the final performance? i.e., Predicting the needed amount of training data
Check out this pilot study for details.

OK, this is a no-brainer. We heard it several times, garbage in garbage out. Dirty data can lead to incorrect decisions and unreliable analysis. Therefore, data cleaning is an essential part of machine learning projects. There are some great tools in the market
But new categories are emerging in this area of research.
- Constraint or ML-based Data Cleaning — General-purpose data cleaning & error identification methods without considering the model or application. These include constraint or parameter-based data cleaning methods or those that use machine learning like clustering or active learning to detect and resolve data errors.
- Model-Aware Data Cleaning — Data cleaning techniques designed to help the model which is being trained.
- Application-Aware Data Cleaning — Data cleaning based on errors observed in the downstream application due to model prediction. So the end-user will have some way of providing feedback to the system, which will be used for data cleaning purposes.

Now we talked about elements like Data Coverage and Data Budgeting. Collecting a sizable dataset that sufficiently captures variations of a real-world phenomenon in question is a daunting task. In most cases, artificial data augmentation can serve as a cheap but promising avenue. The central idea is to transform examples in the training dataset to add diversity in the data seen by the model to help generalize. The success of data augmentation has made it the default part of ML pipelines for a variety of tasks in domains such as image, audio, text.
Data augmentation has also emerged as a go-to technique to improve the robustness of the model by building invariance in the model for certain non-causal domain attributes. Now, what do I mean by “building invariance for certain non-causal domain attributes?”. Remember the cow example with green grass in the background; in that case, the background is a non-causal domain attribute, and we need to tell that to our model. How do we do that? By adding randomization to this domain attribute, i.e., adding more examples with the random background but the same label, e.g., cow with desert background or snow background. That way, our model will understand that the background does not matter as my target label is the same and will build invariance to that non-causal feature.


Most of the recent success in machine learning is driven by supervised learning, where labeled data is a bottleneck. Building such a dataset is a time-consuming and costly affair.
Weak supervision or data programming tries to solve this problem by enabling users to write labeling functions harnessing organizational knowledge such as internal models, domain heuristics, rule-of-thumb, legacy rules, knowledge graph, existing database, ontologies, etc. Snorkel and FlyingSquid are frameworks that embody data programming, an essential element of data-centric AI. But, as you may have wondered, labeling functions are just noisy estimates with varying levels of accuracy, coverage, and even correlations. Still, Snorkel uses a novel and theoretically grounded techniques to learn accurate labels.
The ability to write code to label the data also helps it decouple from the data itself, improving data privacy.
Other than labeling, Snorkel also supports other elements of data-centric AI, namely data augmentation (as we learned before) and subset identification (we will understand more about this soon) using transformation functions and slicing functions.

MLOps is an important frontier in data-centric AI to make it an efficient and systematic process. MLOps amalgamates cultural practices and principled ways for lifecycle management, model monitoring, and validation. MLOps handle the entire lifecycle of a machine learning model both during development and in production. It typically consists of components to manage specific pre and post-training stages and monitoring and debugging aspects. It also enables version control of models and datasets, tracking of experiments, and efficient deployment.
It is well known that the accuracy of active models in production typically diminishes over time. The main reason for this is the distribution shift between the new real-time test data and the data used to train the model initially. The most prominent remedy to this problem still lies periodically (sometimes daily or even hourly) re-training models using fresh training data. However, this is a very costly undertaking and can be avoided by using drift detectors, another essential component of MLOps tools. Continual learning or lifelong learning is an up-and-coming area attempting to enable ML systems in production to automatically adapt to data/concept drift without the need to re-train from scratch.
MLOps tools should also support debugging at any stage in the pipeline to ensure sustainability. Bugs in ML pipelines occur at various stages like data cleaning, feature generation, or modeling. ML pipelines cannot be sustainable or easily debugged without ensuring visibility into all of the steps of the pipeline. Therefore, MLOps tools should facilitate end-to-end logging and monitoring and provide query interfaces to probe ML pipeline health.
There are a plethora of choices in the market when it comes to MLOps but no clear winners and this space is still evolving.

Evaluating a trained model is critical in developing a machine learning application. Evaluation helps assess the quality of the model and helps us anticipate if it will perform in the real world. While this is not new to the practitioners, the data-centric approach urges to make it much more granular. E.g., instead of limiting ourselves to standard metrics for average performance like F1 or Accuracy, understand how the model performs on various subsets in the data. Such granular evaluation helps model owners clearly comprehend their model capabilities and deficiencies.
As a practitioner, one should proactively learn to find different subsets or slices in the dataset. Inputs from subject matter experts (SME) could be crucial in discovering the most relevant slices in the dataset for a given problem.
Since finding such slices in datasets where the model might underperform becomes an essential step, this also encourages researchers to discover methods to help perform this discovery systematically. The idea here is to find slices that are easy to interpret and relevant to the task at hand.

One of the best practices we follow while validating ML models is checking their performance on test data set aside initially. We must also ensure that test data comes from the same distribution as training data. In reality, though, we often encounter data distribution shifts. Distribution shifts are experienced in various forms. For example, the model is likely to learn false correlations between specific features and targets if high volume subsets in training data exhibit relations that do not apply to low volume subsets.
Another example would be when featuring distributions of the examples for the identically labeled class (e.g., a cat that looks like a dog, different subclasses/breeds in a dog, e.g., Labradors, Chihuahuas, etc.) has high variation. In both these cases, the model is likely to perform poorly on underrepresented subsets. Estimating the subsets and balancing those through data augmentation (model patching) or learning group-invariant representations are the key ideas driving research in this direction.

I kept it last as if there is only one thing you could take away from this article, it should be this. Access to domain expertise is key to building robust machine learning applications. As a practitioner, access to domain experts is as crucial as access to the data. Domain experts play a key role in enabling a data-centric approach to AI as they can help us get ONE with the data.
References
[1] Data-centric AI
[2] Data-centric AI: Real-World Approaches (2021)
[3] MLOps: From Model-centric to Data-centric AI (2021)
[4] The Road to Software 2.0 or Data‑Centric AI (2021)
[5] Stanford HAI Data-Centric AI Virtual Workshop — Day 1 (2021)
[6] Stanford HAI Data-Centric AI Virtual Workshop — Day 2 (2021)
[7] Data-centric AI enablers. Best data-centric MLOps tools in 2022 (2021)
[8] Semi-Supervised Data Cleaning with Raha and Baran (2021)
[9] HoloClean: A Machine Learning System for Data Enrichment
[10] Practical Python Data Wrangling and Data Quality
The Elements Of Data-Centric AI was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

