



Building a GenAI CV screener at DataRobot and AWS Hackathon 2023
Last Updated on November 5, 2023 by Editorial Team
Author(s): Euclidean AI
Originally published on Towards AI.
This article describes a solution for a generative AI resume screener that got us 3rd place at DataRobot & AWS Hackathon 2023.
DataRobot & AWS Hackathon
Skip to content October 25, 2023 Briefing session 1pm EST DataRobot and AWS are inviting you and your team to showcase…
www.datarobot.com
Tech Stack
- DataRobot Workbench
- AWS Bedrock
- Streamlit
Solution Architecture

DataRobot and AWS Bedrock are required as part of the solution design. DataRobot provides a workbench for building data science prototypes through Jupyter Notebook. You can also set the environment variables on the notebook instance for things like AWS access key etc.
AWS Bedrock is a managed service platform for foundation models on AWS. It is an orchestration of a bunch of foundation models e.g., Anthropic Claude, Stable Diffusion etc. You can also create a custom model by fine-tuning the foundation models and creating your own model endpoint.

We used Anthropic Claude 2 in our solution. The way we call this model is fairly straightforward. AWS Bedrock provides a Python SDK named Boto3.
Boto3 reference — Boto3 1.28.75 documentation
Do you have a suggestion to improve this website or boto3? Give us feedback.
boto3.amazonaws.com
import boto3, json, os
# You should have your AWS access key id and key saved in environment variables
os.environ["AWS_ACCESS_KEY_ID"] = AWS_ACCESS_KEY_ID
os.environ["AWS_SECRET_ACCESS_KEY"] = AWS_SECRET_ACCESS_KEY
# Initiate a bedrock client/runtime
try:
bedrock_runtime = boto3.client('bedrock-runtime','us-east-1',endpoint_url='https://bedrock-runtime.us-east-1.amazonaws.com')
except Exception as e:
print({"error": f"{e.__class__.__name__}: {str(e)}"})
llm_prompt = """
Your llm prompt here
"""
# Send Rest API request to AWS Bedrock
try:
body = json.dumps({"prompt": llm_prompt, "max_tokens_to_sample": 100000,"temperature":0})
modelId = "anthropic.claude-v2"
accept = 'application/json'
contentType = 'application/json'
response = bedrock_runtime.invoke_model(body=body, modelId=modelId, accept=accept, contentType=contentType)
rv = response.get('body').read()
except Exception as e:
rv = {"error": f"{e.__class__.__name__}: {str(e)}"}
DataRobot offers some additional benefits to work like the LLMOps platform.
- Model Monitoring after Deployment
- Prediction Environment (Automatically create a docker image based on your production script)
- Model Registry

To be able to deploy the model, there are two functions that need to be specified on the Jupyter Notebook, load_model() and score_unstructured(). You will have to follow the exact format as specified in DataRobot’s documentation.
Deploy – drx v0.1.19
Deploy any model to ML Ops Any model built outside of DataRobot is considered a 'Custom Model'. If a model is built…
drx.datarobot.com
import os
AWS_ACCESS_KEY_ID = os.environ["AWS_ACCESS_KEY_ID"]
AWS_SECRET_ACCESS_KEY = os.environ["AWS_SECRET_ACCESS_KEY"]
def load_model():
"""Custom model hook for loading our knowledge base."""
import boto3, json, os, sys, io
os.environ["AWS_ACCESS_KEY_ID"] = AWS_ACCESS_KEY_ID
os.environ["AWS_SECRET_ACCESS_KEY"] = AWS_SECRET_ACCESS_KEY
try:
rv = boto3.client('bedrock-runtime','us-east-1',endpoint_url='https://bedrock-runtime.us-east-1.amazonaws.com')
except Exception as e:
rv = {"error": f"{e.__class__.__name__}: {str(e)}"}
return rv
def score_unstructured(model, data, query, **kwargs):
import boto3, json, os, sys, io
"""Custom model hook for screening a resume with llm.
Pass in a data dict with the following headers
job_descript: job description of the advertised role. It needs to include any role specific requirements
resume: resume parsed from pdf in plain text (string)
model: bedrock client object
Returns:
--------
rv : str
Json dictionary with keys:
- 'completion' main response from Claud2 model
- 'stop sequence' sequence that will cause the model to stop generating completion text
"""
bedrock_runtime = model
generation_prompt_template = """
\n\nHuman: You are a virtual recruiter for a company. Your task is to review the candidate's resume against the job description. You must list out all the requirements from the job description in your
response and find the relevant experience from the candidate's resume, then assign a relevancy scale (from 0 to 1). If you can't find relevant experience, just say no relevant experience, don't try to make up
an answer. You must include all requirements from the job description. The response must be in a form of a html table with Requirements, Relevant Experience and Relevancy Scale as header row.
<job-description>
{job_descript}
</job-description>
<candidate-resume>
{resume}
</candidate-resume>
\n\nAssistant:
"""
data_dict = json.loads(data)
llm_prompt = generation_prompt_template.format(
job_descript=data_dict["job_descript"],
resume=data_dict["resume"],
)
try:
body = json.dumps({"prompt": llm_prompt, "max_tokens_to_sample": 100000,"temperature":0})
modelId = "anthropic.claude-v2"
accept = 'application/json'
contentType = 'application/json'
response = bedrock_runtime.invoke_model(body=body, modelId=modelId, accept=accept, contentType=contentType)
rv = response.get('body').read()
except Exception as e:
rv = {"error": f"{e.__class__.__name__}: {str(e)}"}
return rv
Lastly, you can run the deploy function to deploy your model as an endpoint. In this case, it’s just a wrapper function that uses the AWS Bedrock client under the hood.
import datarobotx as drx
deployment = drx.deploy(
"storage/deploy/",
name="CV Screener Powered by LLM",
hooks={"score_unstructured": score_unstructured, "load_model": load_model},
extra_requirements=["boto3", "botocore", "datarobotx[llm]", "pypdf","unstructured", "awscli>=1.29.57", "datarobot-drum"],
# Re-use existing environment if you want to change the hook code,
# and not requirements
environment_id="653fbe55f1c59b93ae7b4a85",
)
# Enable storing prediction data, necessary for Data Export for monitoring purposes
deployment.dr_deployment.update_predictions_data_collection_settings(enabled=True)
We built the prototype with Streamlit.
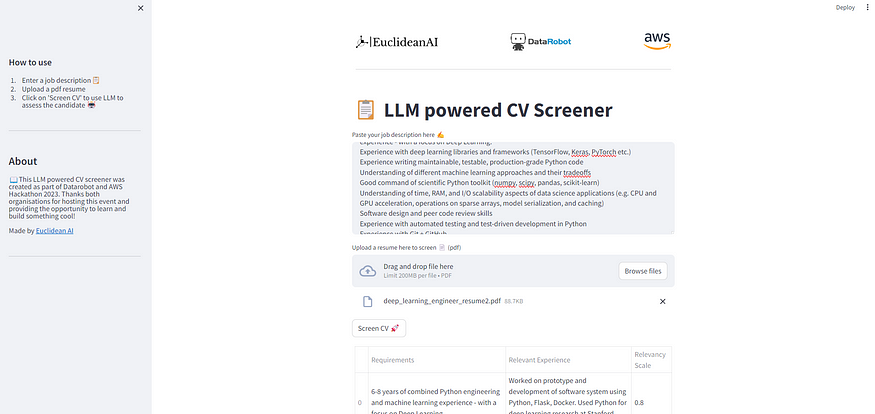
Example job description:
We are looking for talented people with excellent engineering skills and deep knowledge of machine learning who can analyze problems, design unprecedented solutions, and implement them for real-world use on top of our platform. Our engineers are also depended upon to lift up everyone around them and contribute to the excellence of every engineer in the organization.
You will assist in our journey to be the best platform for extracting value from Deep Learning & Gen AI.
Responsibilities
Write maintainable, testable, production-grade Python code
Design and build products for end-users powered by machine learning and generative AI
Integrate machine learning algorithms with other applications and servicesAutomate machine learning processes
Main Requirements
Recommended background: 6-8 years of combined Python engineering and machine learning experience - with a focus on Deep Learning.
Experience with deep learning libraries and frameworks (TensorFlow, Keras, PyTorch etc.)
Experience writing maintainable, testable, production-grade Python code
Understanding of different machine learning approaches and their tradeoffs
Good command of scientific Python toolkit (numpy, scipy, pandas, scikit-learn)
Understanding of time, RAM, and I/O scalability aspects of data science applications (e.g. CPU and GPU acceleration, operations on sparse arrays, model serialization, and caching)
Software design and peer code review skills
Experience with automated testing and test-driven development in Python
Experience with Git + GitHub
Comfortable with Linux-based operating systems
Desired Skills
Experience with large-scale machine learning (100GB+ datasets)
Competitive machine learning experience (e.g. Kaggle)
Previous experience in deploying and maintaining machine learning models in production
The talent and dedication of our employees are at the core of DataRobot’s journey to be an iconic company. We strive to attract and retain the best talent by providing competitive pay and benefits with our employees’ well-being at the core. Here’s what your benefits package may include depending on your location and local legal requirements: Medical, Dental & Vision Insurance, Flexible Time Off Program, Paid Holidays, Paid Parental Leave, Global Employee Assistance Program (EAP) and more!
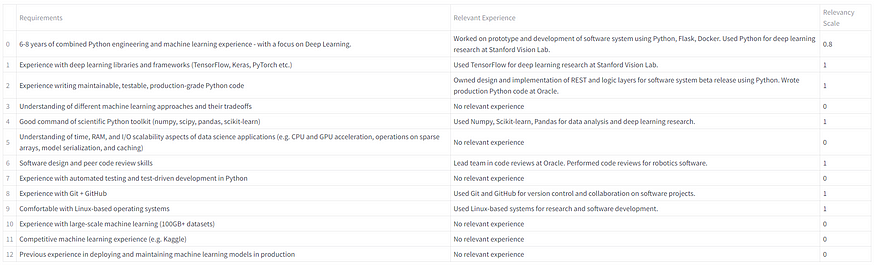
With the resume sample, here is the screening output by LLM.
Thanks for reading through our solution. Here is a 2-minute showcase video below. Hope you enjoy it. If you have any questions, feel free to reach out to us.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

