



34 Words About Language, Every AI-Savvy Leader Must Know
Last Updated on January 7, 2023 by Editorial Team
Author(s): Yannique Hecht
Artificial Intelligence
Think you can explain these? Put your knowledge to the test!
[This is the 7th part of a series. Make sure you read about Search, Knowledge, Uncertainty, Optimization, Machine Learning, Neural Networks, and Language.]

To truly change how humans interact with computers, we need to enable computers to read, understand, and derive meaning from written and spoken language. In AI, this field is referred to as Natural Language Processing (NLP).
Potential NLP applications include:
- automatic summarization
- information extraction
- language identification
- machine translation
- named entity recognition
- speech recognition
- text classification
- word sense disambiguation
Admittedly, these terms are all fairly dry and boring… but there are many exciting possibilities hiding behind them! See for yourself:
Make a haircut appointment on Tuesday morning anytime between 10 and 12.
How does a machine translate such sounds, into something it can understand and act upon?
And, how can it account for context?
To help you answer these questions, this article briefly defines the core concepts and terms around language.
Language
Natural language processing: (or NLP) a major field of AI, dealing with the interaction between humans and computers by allowing computers to read, understand and derive meaning from language
Syntax: the arrangement of words and phrases to create well-formed sentences in a language
Semantics: the meaning of a word, phrase, or text
Formal grammar: a system of rules for generating sentences in a language
Context-free grammar: a finite set of recursive grammar rules, for example:
N → he | Anthony | computer | ...
D → the | a | an | ...
V → took | helped | searched | ...
P → to | on | over | ...
ADJ → blue | busy | old | ...
N V D N
| | | |
he searched the computer
NP -> N | DN
NP
/
D N
| |
the computer
N-gram: a contiguous sequence of n items from a sample of text
Character n-gram: a contiguous sequence of n characters from a sample of text
Word n-gram: a contiguous sequence of n words from a sample of text
Unigram: a contiguous sequence of 1 item from a sample of text
Bigram: a contiguous sequence of 2 items from a sample of text
Trigram: a contiguous sequence of 3 items from a sample of text
The bolded words are one of the possible trigrams in this sentence.
The bolded words are one of the possible trigrams in this sentence.
The bolded words are one of the possible trigrams in this sentence.
The bolded words are one of the possible trigrams in this sentence.
The bolded words are one of the possible trigrams in this sentence.
The bolded words are one of the possible trigrams in this sentence.
The bolded words are one of the possible trigrams in this sentence.
The bolded words are one of the possible trigrams in this sentence.
The bolded words are one of the possible trigrams in this sentence.
Tokenization: the task of splitting a sequence of characters into pieces (tokens)
"This is a sample sentence, for tokenization."
["This", "is", "a", "sample", "sentence,", "for", "tokenization."]
Word tokenization: the task of splitting a sequence of characters into words
Sentence tokenization: the task of splitting a sequence of characters into sentences
Markov models: a stochastic model used to model randomly changing systems
Markov chain: a stochastic model describing a sequence of possible events in which the probability of each event depends only on the state attained in the previous event
text categorization: (or text tagging) the task of classifying text into organized groups or categories
"I love to eat ice cream. Gianlugigi makes the best ice cream!"
P(Positive | "love", "best")
"This ice cream was terrible. It was not as good as I thought!"
P(Negative | "terrible", "not as good")
Bayes’ rule: (or Bayes’ theorem) a practical mathematical formula for determining conditional probability:
P(b|a) = [ P(a|b) P(b) ] / P(a)
P(Positive) =
number of positive samples / number of total samples
P("love"| Positive) =
number of positive samples with "love" / number of positive samples
Naive Bayes: an algorithm making use of Bayes’ rule to classify objects (for example spam filters)
Additive smoothing: (or Laplace smoothing) a statistical technique to smooth categorical data by adding a value α (for example 1) to each value in a distribution (pretending you’ve seen each value 1 more time than you actually have)
Information retrieval: the task of finding relevant documents in response to a user query
Topic modeling: models for discovering the topics for a set of documents
Term frequency: the number of times a term appears in a document
Function word: a word that has little meaning on its own, but is used to grammatically connect other words, for example,
am, by, do, is, which, with, yet, …
Content word: a word that carries meaning independently, for example:
win, type, computer, …
Inverse document frequency: a measure of how common or rare a word is across documents
log(total documents / number of Documents containing word x)
Tf-idf: a ranking of what words are important in a document by multiplying term frequency (TF) by inverse document frequency (IDF)
td-idf = term frequency * (inverse document frequency)
Information extraction: the task of extracting knowledge from documents
Wordnet: a lexical database of semantic relations between words
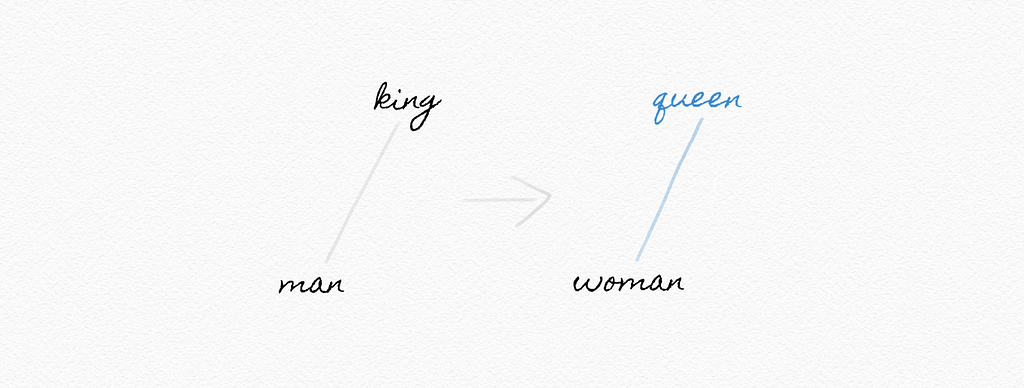
Word representation: the process of representing words as feature factors where the vector’s entries stand for hidden features of the word’s meaning
[Be sure to check out Nurzat Rakhmanberdieva’s walkthrough on word representation…]
One-hot representation: a representation of meaning as a vector with a single 1, and with other values as 0
king [1,0,0,...,0]
man [0,1,0,...,0]
woman [0,1,1,...,0]
queen ?
Distribution representation: a representation of meaning distributed across multiple values
king [-0.55, -0.65, 0.25, ..., 0.12]
man [-0.12, -0.44, 0.25, ..., 0.12]
woman [-0.12, -0.44, 0.75, ..., 0.12]
queen ?
Word2vec: a popular model for generating word vectors
Skip-gram architecture: neural network architecture for predicting context words given a target word
Whether you look at Amazon, Alibaba, Apple, Baidu, Google, Microsoft, or Xiaomi, Big Tech is lunging on opportunities for personal digital assistants, believing they will drive the future of commerce, analytics, and CRM.
No single digital assistant is or claims to be bullet-proof. Instead, they often leave us frustrated and with unfulfilled expectations. For example, Biased data sets in voice recognition are only one of many hurdles.
However, the field of language is advancing more than rapidly, suggesting it’s only a matter of time until we can communicate with machines intuitively.
Explore similar AI-related topics, including Search, Knowledge, Uncertainty, Optimization, Machine Learning, and Neural Networks.
Like What You Read? Eager to Learn More?
Follow me on Medium or LinkedIn.
About the author:
Yannique Hecht works in the fields of combining strategy, customer insights, data, and innovation. While his career has been in the aviation, travel, finance, and technology industry, he is passionate about management. Yannique specializes in developing strategies for commercializing AI & machine learning products.
34 Words About Language, Every AI-Savvy Leader Must Know was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

