



Back Translation in Text Augmentation by nlpaug
Last Updated on August 29, 2020 by Editorial Team
Author(s): Edward Ma
Natural Language Processing
Data augmentation for NLP — generate synthetic data by back-translation in 4 lines of code
English is one of the languages which has lots of training data for translation while some language may not has enough data to train a machine translation model. Sennrich et al. used the back-translation method to generate more training data to improve translation model performance.
Given that we want to train a model for translating English (source language) → Cantonese (target language) and there is not enough training data for Cantonese. Back-translation is translating target language to source language and mixing both original source sentences and back-translated sentences to train a model. So the number of training data from the source language to target language can be increased.
In the previous story, the back-translation method is mentioned to generate synthetic data for the NLP task. Such that, we can have more training for model training especially for low-resource NLP tasks and languages.
This story will cover how Facebook AI Research (FAIR) team trains a model for translation and how can we leverage the pre-trained model to generate more training data for your model. By leveraging subword models, large-scale back-translation, and model ensembling, Ng et al. (2019) win WMT 19 award. They worked on two language pairs and four language directions which are translating English ← → Germany (EN ← → DE) and English ← →Russian (EN ← →RU). They demonstrated how to use back-translation to boost up model performance. After that, I will show how can we write a few lines to generate synthetic data by using back-translation. Here are some details about data processing, data augmentation, and translation model.
Data Processing
Subword
In the earlier stage of NLP, word level and character level tokens are used to train a model. In the state-of-the-art NLP model, the sub-word (in between a word and character level) is the standard way in the tokenization stage. For example, it uses “trans” and “lation” to represent “translation” because of occurrence frequency. You may have a look at 3 different sub-word algorithms from here. Ng et al. pick bye pair encodings (BPE) with 32K and 24 split operations for EN←→DE and EN← →RU tokenization respectively.
Data Filtering
To make sure only sentence pairs with the correct language, Ng et al. use langid (Lui et al., 2012) to filter out invalid data. langid is a language identification tool that tells you what language does text belongs to.
If sentences contain more than 250 tokens or length ratio between source and target exceeding 1.5, it will be excluded in model training. I suspected that it may introduce too much noise information to the model.
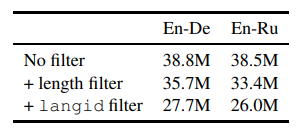
The third filtering way is targeting monolingual data. To keep high-quality monolingual data, Ng et al. adopt the Moore-Lewis method (2010) for removing noisy data from the larger corpus. In short, Moore and Lewis score text by the difference of source data language model and the larger corpus language model. After picking a high-quality corpus, it will use the back-translation model to generate a pair of training data for the translation model.
Data Augmentation
Back-Translation
After filtering low-quality data from a larger monolingual corpus, it is ready for training an intermediate target-to-source model. From experiments, ensembled models trained on back-translated data is better than a single model.
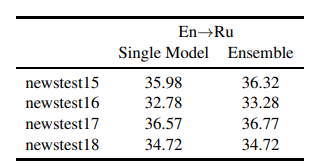
Translation Model
As usual, Transformer architecture (Vaswani et al., 2017) is adopted in FAIRSEQ. The Transformer leverages multiple attention networks to compute representation. For more information about the Transformer architecture, you may visit this article.
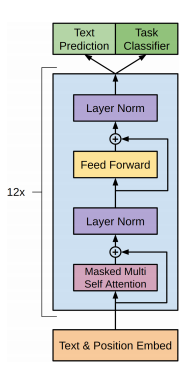
Another skill is leveraging multiple trained models to form an ensemble model for prediction.
Fine-tuning
After training on the filtering and back-translated data, Ng et al. leverage the model by using the previous year dataset such as newstest2012 and newstest2013.
Generating synthetic data by Back Translation
nlpaug provides an easy way to generate synthetic data by 4 lines of code.
Behind the scenes, nlpaug leveraged pre-trained model from fairseq (released by Facebook AI Research) to perform 2 times translation. Taking the following as an example, it translates source input (English) to German. After that, providing the translated text (German, the output from the first model) to the second model, it will output translated text (English). Here is the code:
import nlpaug.augmenter.word as naw
text = 'The quick brown fox jumped over the lazy dog'
back_translation_aug = naw.BackTranslationAug(
from_model_name='transformer.wmt19.en-de',
to_model_name='transformer.wmt19.de-en')
back_translation_aug.augment(text)
Taking the above examples, it can be changed from “The quick brown fox jumped over the lazy dog” to “The speedy brown fox jumped over the lazy dog”
Extension Reading
- Text augmentation library (nlpaug)
- Pre-trained translation library (fairseq)
- Data Augmentation in NLP
- Data Augmentation library for text
About Me
I am a Data Scientist in the Bay Area. Focusing on the state-of-the-art in Data Science, Artificial Intelligence, especially in NLP and platform related areas. You can reach me on Medium, LinkedIn, or Github.
Reference
- M. Lui and T. Baldwin. langid.py: An Off-the-shelf Language Identification Tool. 2012
- Vaswani A., Shazeer N., Parmar N., Uszkoreit J., Jones L., Gomez A. N. and Kaiser L.. ttention is all you need. 2017
- s. Edunov, M Ott, M Auli, and D. Grangierv. Understanding Back-Translation at Scale. 2018
- N. Ng, K. Yee, A. Baevski, M. Ott, M. Auli, and S Edunov. Facebook FAIR’s WMT19 News Translation Task Submission]. 2019
Back Translation in Text Augmentation by nlpaug was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts



Recent Posts






")