


")
Wild Wild RAG… (Part 1)
Last Updated on November 6, 2023 by Editorial Team
Author(s): Zoheb Abai
Originally published on Towards AI.
Let’s begin by understanding what exactly an RAG Application is, a term that has garnered significant attention in recent months.
RAG (Retrieval-Augmented Generation) is an AI framework that enhances the quality of Language Model-generated responses by incorporating external knowledge sources. It bridges the gap between language models and real-world information, resulting in more contextually informed and reliable text generation. To illustrate, take a look at the image below, which provides a compelling example.

We can divide the process into four major sections:
- Step 1,2,3 and 4 — Indexing
- Step 5 — Prompting
- Step 6 and 7 — Search & Retrieving
- Step 8 — Generation
Well, creating a prototype for an RAG application is straightforward, but optimizing it for high performance, durability, and scalability when dealing with a vast knowledge database presents significant challenges.
This blog will delve into the distinct features that set RAG applications apart from basic Language Model (LLM) applications, focusing on the significance of embeddings and vector store choices in this context. Basically, the Indexing and Search & Retrieving sections. We will cover remaining sections in next installment of our blog series.
Let’s begin.

To build the ‘context’ associated with your prompt and query, we must first generate embeddings from segmented data chunks. These embeddings are stored as a vector index, serving as the foundation for subsequent approximate nearest-neighbor (ANN) searches based on user queries. While the concept seems straightforward, delving into the intricacies of transitioning this process into a production environment reveals a host of challenges worth exploring.
Cost of Vector Indexing, Search and Retrieval
Now, let’s delve into one of the central considerations — the cost of indexing. It’s crucial to understand that when it comes to building a production-ready application, relying solely on free in-memory options is not advisable.
Let’s walk through a conservative estimation for building embeddings from an internal knowledge base comprising 3.5 million pages or a million PDFs with an average of 3.5 pages. For simplicity, let’s assume that each page consists of textual content only, devoid of images. Each page, therefore, roughly translates to 1000 tokens. If we break this down into chunks of 1,000 tokens each, we find ourselves with 3.5 million chunks, which subsequently convert to 3.5 million embeddings.
For cost calculations, let’s consider two leading options in this domain — Weaviate and Pinecone. We’ll keep things straightforward and assess the monthly expenses across three key sections:
- One-Time Embedding Conversion Cost: For processing 3.5 million embeddings, the approximate cost comes to $350, at a rate of $0.0001 per conversion.
- Pinecone Performance-Optimized Vector Database (Standard): For a single replica, this option would cost approximately $650. This includes both indexing and retrieving costs. It’s important to note that costs scale linearly as your requirements grow. Weviate, another viable choice, is likely to have a similar pricing structure.
- Cost for Query Embedding Conversion: Assuming 1,000 users making an average of 25 queries per day, with each query and prompt totaling 100 tokens, the cost for this section rounds up to approximately $10.

The total monthly cost for indexing, at a moderate level, stands at approximately $1,000. Please note that this figure does not encompass the expenses associated with OpenAI LLM response generation and application hosting, which can be estimated to be roughly 5 to 7 times greater than the aforementioned cost or even more. Therefore, the vector store cost constitutes a significant portion, accounting for approximately 15 to 20% of the overall expenditure.
To lower costs, you can consider hosting top embedding models, which also reduces vector store expenses by opting for an embedding size smaller than 1536.
But you still have to pay for a vector store.
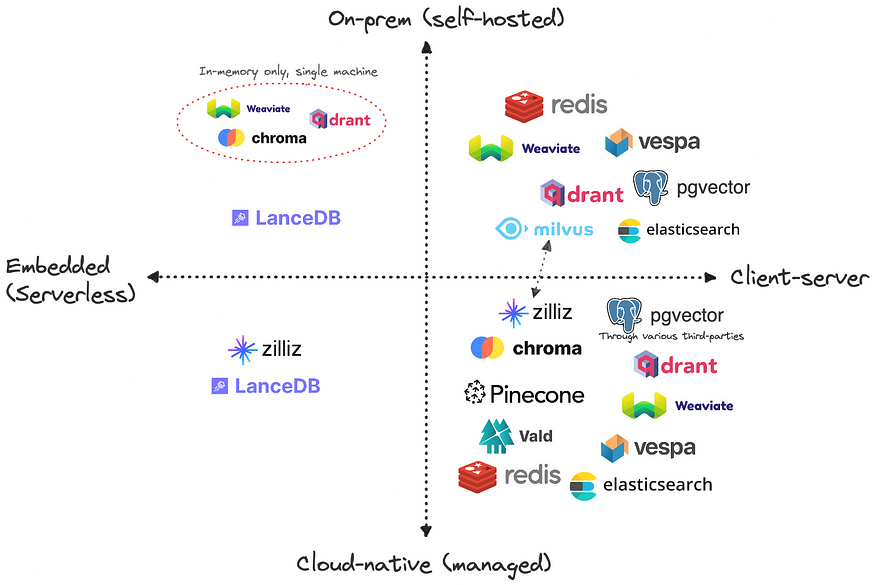
In cases where functionality like similarity search metric and index remains consistent, what other factors should be considered when selecting a vector store out of 100+ options?
Balancing Latency, Scale, and Recall
Based on the scale and cost perspective, let’s consider Client-Server Architecture for our vector stores. You can either choose to host it on the cloud or on-premise based on factors like your data volume, privacy and money.
When it comes to vector stores, there are two significant types of latency to consider: Indexing latency and Retrieval Latency. In many use cases, Retrieval latency takes precedence over Indexing latency. This preference stems from the fact that indexing operations are typically sporadic or one-time tasks, while the retrieval of chunks similar to user queries occurs much more frequently, often in real-time and at scale through user interfaces.
Recall, on the other hand, quantifies the proportion of true nearest neighbors found, averaged across all queries. Most vendors in this domain employ a hybrid vector search methodology that blends keyword and vector search techniques in various ways. Notably, different database vendors make distinct choices and compromises when it comes to optimizing either for recall or latency.
Let’s review Recall vs Queries/sec ANN Benchmarks on a standard dataset for cosine metric, a critical metric which offers insights into how well the database balances retrieval accuracy with query processing speed. A higher value signifies that the database can retrieve a greater proportion of relevant data at a faster query rate, providing an optimal blend of accuracy and performance for real-time applications.

Scann, Vamana (DiskANN) and HNSW emerge as some of the best options on faster and accurate indices for search and retrieval. Now let’s review the Recall vs Index size (kB)/Queries per second for the same, which is a valuable metric for assessing the efficiency and resource consumption of a vector database. A lower value indicates greater memory efficiency, optimizing performance and scalability of the vector database.

In this context, Qdrant, Weviate and Redisearch emerge as some of the best options for memory-efficient databases.
However, you can refer to the following image to learn about the underlying vector index used by each database.

It’s evident that a significant number of database vendors have chosen to develop their proprietary implementations of graph-based HNSW. These custom implementations often incorporate optimizations aimed at reducing memory consumption, such as combining Product Quantization (PQ) with HNSW. However, it’s noteworthy that a select few have embraced DiskANN, which appears to deliver comparable performance to HNSW while offering the unique advantage of scaling to larger-than-memory indexes stored purely on disk.
In our assessment, we refrain from relying on benchmarks provided by vendors, as they may introduce bias into the evaluation process.
Inflexibility and No Continual Learning
In a future scenario, where you might need to update your Large Language Model (LLM) or embedding model through fine-tuning, subscribe to an upgraded model, expand your embedding dimensions, or accommodate changes in your data, the need to re-index and the associated costs can be nothing short of a nightmare. This rigidity can significantly impede the agility and cost-effectiveness of your system’s evolution.
In addition to these challenges, let’s delve into some inherent complexities within the Vector Search and Retrieval process using ANN algorithm.
Index Error Handling and Curse of Dimensionality
When encountering a situation where a text query fails to retrieve the pertinent context and instead delivers unrelated or nonsensical information, the root causes of this failure can typically be attributed to one of three factors:
a) Lack of Relevant Text: In some cases, the relevant text chunk simply does not exist within the database. This outcome is acceptable as it suggests that the query may be unrelated to the dataset’s contents.
b) Poor Quality Embeddings: Another possible cause is the subpar quality of the embeddings themselves. In such instances, the embeddings are unable to effectively match two relevant texts using cosine similarity.
c) Distribution of Embeddings: Alternatively, the embeddings themselves may be of good quality, but due to the distribution of these embeddings within the index, the ANN algorithm struggles to retrieve the correct embedding.
While it is generally acceptable to dismiss reason (a) as the query’s irrelevance to the dataset, distinguishing between reasons (b) and (c) can be a complex and time-consuming debugging process. This behavior becomes increasingly pronounced in the case of ANN algorithms dealing with a large number of high-dimensional vectors — a phenomenon often referred to as the “Curse of Dimensionality.”
Reevaluating Vector Search and Retrieval Methods
If the primary goal of the vector search ecosystem is to fetch “relevant text” in response to a query, why maintain two separate processes? Instead, why not establish a unified, learned system that, when presented with a question text, provides the “most relevant” text as a direct output?
The fundamental assumption that underpins the entire ecosystem is the reliance on similarity measures between vector embeddings to retrieve relevant text. However, it’s important to recognize that there are potentially superior alternatives to this approach. Large Language Models (LLMs) are not inherently fine-tuned for similarity retrieval, and it’s entirely plausible that other retrieval methods could yield more effective results.
The deep learning revolution has imparted a valuable lesson: a retrieval system that is jointly optimized tends to outperform a disconnected process where embedding and Approximate Nearest Neighbors (ANN) operations are independent of each other. In an optimized retrieval system, the embedding process and the ANN component are intimately connected and aware of each other’s intricacies, leading to more coherent and efficient information retrieval. This underscores the importance of holistic and integrated approaches when designing systems for information retrieval and context matching.
Closing Remarks
In the realm of Production-Ready Retrieval-Augmented Generation (RAG) applications and vector search, we’ve uncovered the challenges and opportunities in bridging language models with real-world knowledge. From the cost considerations of indexing to the delicate balance of latency, scale, and recall, it’s evident that optimizing these systems for production requires thoughtful planning. The inflexibility of models highlights the importance of adaptability in the face of change. As we reevaluate vector search and retrieval for production environments, we find that a unified, jointly optimized system offers promise. In this ever-evolving landscape, we’re on the cusp of creating more context-aware AI systems that redefine the boundaries of text generation and information retrieval.
The journey continues…
Thanks for reading. Connect with me on LinkedIn.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

