



Trends in AI — July 2022
Last Updated on July 15, 2022 by Editorial Team
Author(s): Sergi Castella i Sapé
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Trends in AI — July 2022
NLLB-200 the brand new open source breakthrough in Machine Translation from Meta AI, learning to Play Minecraft by watching videos, Yann LeCun’s path towards human-level AI, a new Neural Corpus Indexer for Document Retrieval, how Minerva solves quantitative reasoning problems, Artistic Radiance Fields, Diffusion Language Models, Retrieval Augmented Computer Vision and much, much more…
Activity in the AI world did nothing but accelerate when summer arrived. While some were busy debating the sentience of the LaMDA chatbot, or admiring the output created by DALL-E mini, this month has been remarkably packed with research blockbusters from big labs: Google, Meta, OpenAI… Yet another Autoregressive Text-to-Image generation model from Google, called Parti which is based on the Pathways architecture was published, to rival DALL-E 2 and Imagen, but it almost didn’t get noticed. CVPR brought a total of over 2600 papers in Computer Vision, including gems like automated lip reading, and new SOTA’s in the autonomous driving space. The news and code side hasn’t been slow either, and this month we’re highlighting:
- Big Science — a collaborative open-source effort to train a large multilingual Language Model spearheaded by HuggingFace — reached its training run iterations target for their 176 billion parameter model (BLOOM), after many months of preliminary research and experiments. We’re thrilled to see what research findings come out of this effort.
- aqlaboratory/openfold: An open-source implementation of Alpha Fold 2 which lets you train the model yourself or do inference with their own pretrained models
- py-why/dowhy: a full-fledged Python library for causal inference which supports explicit modeling and testing of causal assumptions.
- Google open-sourced T5X, an improved T5 codebase including the 1.6T param Switch-C and the 395B param Switch-XXL models.
🔬 Research
Every month we analyze the most recent research literature and select a varied set of 10 papers you should know of. This month we’re covering topics such as Machine Translation (ML), Reinforcement Learning (RL), Diffusion Models, Information Retrieval, Radiance Fields, and more.
1. No Language Left Behind: Scaling Human-Centered Machine Translation | Blog post | Code
By NLLB Team, Marta R. Costa-jussà, James Cross, Angela Fan, et al.
❓Why → A single Machine Translation Model with state-of-the-art quality for over 200 languages which improves the average BLEU score by 44%. That’s by itself a big deal. Add the inclusion of many low-resource languages for which MT was not available before, and the fact that all of this is now available as open-source, and you get the impact.
💡Key insights → NLLB manages to train a single sparse Mixture of Experts Transformer model with 54 Billion parameters on automatically mined bitext data from over 200 languages. A lot of the effort, described in great detail in the excellent 190-page paper, is in the methods to mine the data, clean it up and make sure the model does not produce toxic hallucinations.
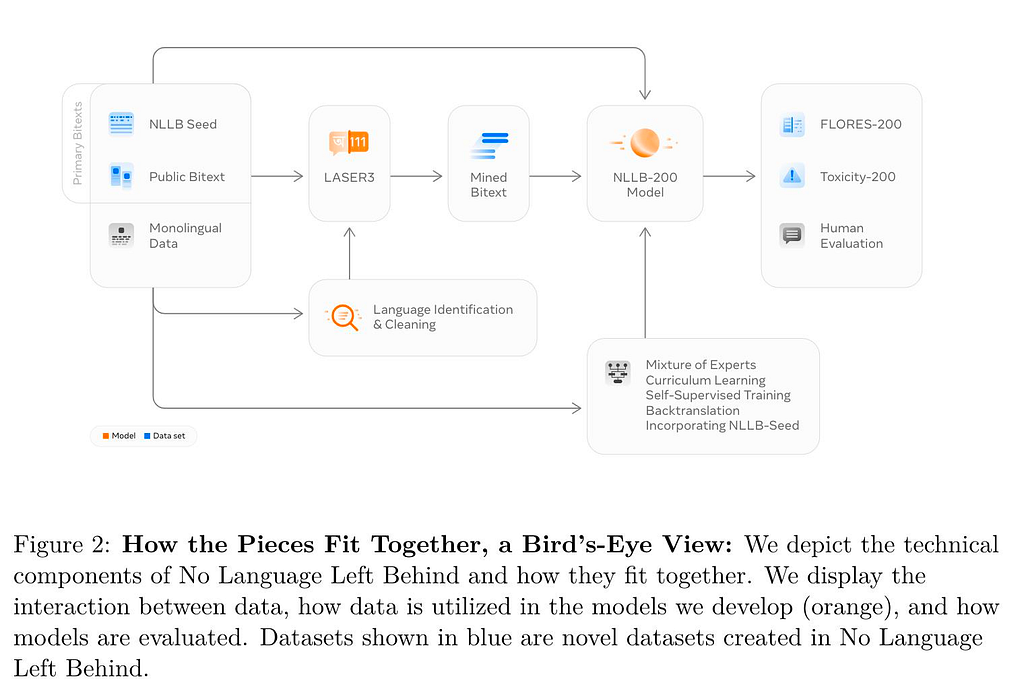
Training the model involved many neat tricks like Layer Dropout, Curriculum Learning, and Model Distillation. A new multilingual sentence embedding model called LASER3 plays a central role in all of this. For some of the finer technical details, also check out the earlier paper “Tricks for Training Sparse Translation Models” or the exclusive Zeta Alpha interview with Angela Fan, one of the key scientists on the project.
The NLLB paper, or book, really, is a great read, covering everything from technical detail, linguistic analysis, ethical considerations, and impact analysis up to benchmarking. The average BLEU score improvement by 44% on the FLORES-101 data set is impressive…
But of course, everyone is curious about how this model compares to Google Translate. And that was evaluated as well. On average, the quality of the NLLB-200 model is similar with a clear edge for lower resource languages. It adds 70 or so languages for which no (good) MT models were available before. The most important difference? NLLB-200 is fully open source under the MIT License.
Among other goodies, this makes available: The Flores-200 Evaluation dataset in 204 languages. NLLB-Seed: Seed training data in 39 languages. LASER3: sentence encoders for identifying aligned bitext for 148 languages. Training data recreation: Scripts that recreate the NLLB training data. And finally, the MT Models cover 202 languages, including:
- NLLB-200: A 54.5B Sparsely Gated Mixture-of-Experts model
- 3.3B and 1.3B Dense Transformer models
- 1.3B and 600M Dense transformer models distilled from NLLB-200
- Training and generation scripts to reproduce our models
Applause to Meta for sharing this with the world. It will for sure greatly advance further MT research, global access to knowledge, and cross-language communication. We hope it also helps with better content moderation in conflict zones, a known issue for Facebook, and that the open-source nature of the model will not contribute to an increase in mass surveillance and censorship in those same language areas. After all, the road to hell is paved with good intentions.
2. Evolution through Large Models
By Joel Lehman, Jonathan Gordon, Shawn Jain, Kamal Ndousse, Cathy Yeh, Kenneth O. Stanley.
❓ Why → While large Language Models (LMs) themselves are fertile ground for research, a trend is emerging where LMs are used as a building block of algorithms to solve other tasks. For instance, augmenting a dataset [1]. Now they’re used in the context of evolutionary computing: as a mutation operator.
💡 Key insights → Evolutionary algorithms are algorithms that follow evolutionary principles to solve a task: having a population of candidate solutions that can be recombined, mutate and interact with their environment to gradually adapt to changing conditions or optimize some fitness objective. Just like how other lifeforms on Earth came to exist.
Genetic programming is the task of generating computer programs (program synthesis) with evolutionary algorithms. One of the biggest challenges of using evolutionary computing for program synthesis is that if you mutate a candidate program to obtain a new candidate purely randomly, you’ll search through the space of possible programs very inefficiently.
Is there a public source of code diffs along with annotations on the changes a mutator operator could learn from? Bingo. GitHub’s code diffs and commits messages! This work constructs a dataset with these and trains a large LM to learn human-esque ways to improve code, discovering mutations that are more sophisticated than those following handcrafted rules. Moreover, this large LM can be continuously finetuned in a Reinforcement Learning setting where positive reward mutations are fed again for training the LM.
Making this all work is quite complex, involving a lot of careful curation of training data and balancing all moving parts. The authors showcase how this algorithm works with a game called Sodarace, whose objective is to invent 2D creatures made of point masses and springs that move in space. The model has to generate raw Python programs that invent these creatures, starting from a basic seed which is a program generating a basic sodaracer.
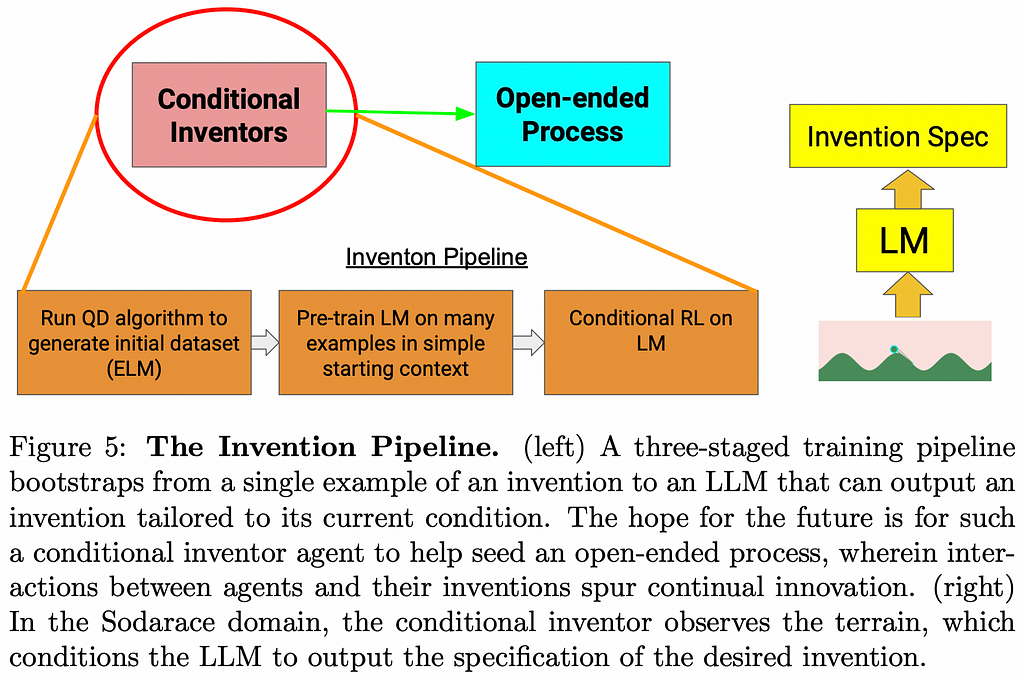
The authors believe that the evolutionary approach directed by an expressive LM leads to superior open-endedness, the main overarching theme across the paper. This could revive the interest in evolutionary algorithms, which had arguably stalled in the past years under the shadow of Deep Learning.
3. Diffusion-LM Improves Controllable Text Generation
By Xiang Lisa Li, John Thickstun, Ishaan Gulrajani, Percy Liang, Tatsunori B. Hashimoto.
❓ Why → Diffusion models keep conquering domains.
💡 Key insights → It’s tricky to control the generation of text from a Language Model to satisfy certain constraints such as sentiment and structure (e.g. generate a sentence that’s positive and is subject-verb adjective object).
Previous works on diffusion applied to text treated language as discrete, applying the diffusion process by iteratively corrupting tokens discretely, which the model had to learn to reconstruct (a little bit like iterative masked language modeling). In this work, however, they apply the diffusion process directly on the continuous embeddings, which is closer to the diffusion process we’re used to in images. Embeddings iteratively drift in the high dimensional space and are only discretized into tokens at the very end of the process.
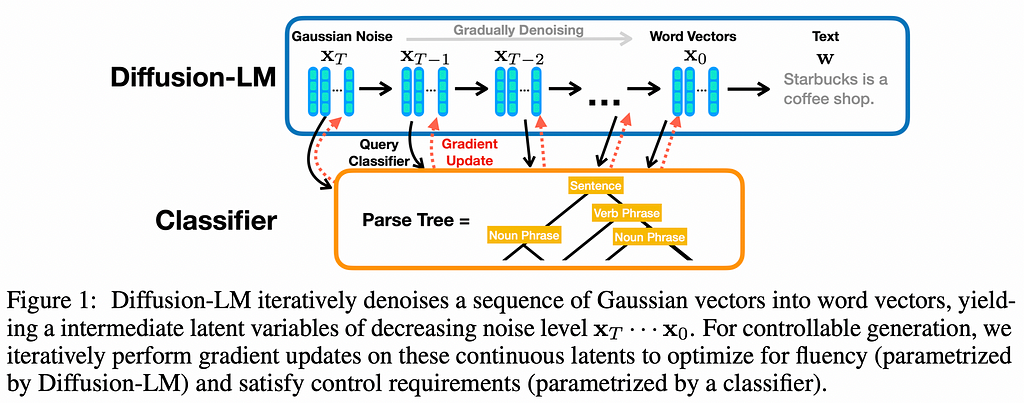
One of the main benefits of using a diffusion model as a language model is that it lends itself very easily to steering the generation throughout the diffusion process by evaluating how well a constraint is being satisfied at each diffusion step and using the gradient of that objective to update the diffusion intermediate states (see figure above).
The authors show how this setup works in several controlled language modeling tasks, controlling for aspects such as semantic content, parts-of-speech, syntax trees, and syntax spans. The empirical results show how this method strongly outperforms previous works doing controlled text generation.
4. Memory-Based Model Editing at Scale
By Eric Mitchell, Charles Lin, Antoine Bosselut, Christopher D. Manning, Chelsea Finn.
❓ Why → One of the main limitations of current GPT-like LMs is that their knowledge about the world is frozen once training is finished. How can we overcome this limitation?
💡 Key insights → Previous works tackled the problem of updating knowledge in LMs by letting them interact with some sort of explicit knowledge base that can change. For instance, web-GPT [5] can search documents from the web and append the top-k results to the prompt such that it can attend to that context to answer questions like “Is Messi at Barça”? which improves the factual accuracy of the model when compared to regular LMs.
The method proposed by this paper is conceptually very simple: allowing users to add entries to an edit memory consisting of question-answer pairs. During inference, a scope classifier determines whether the prompt is within the scope of any of the memory edits and redirects the input accordingly to one of two models: the original frozen LM or a counterfactual model which takes the relevant edit memory as a context for the prompt (see figure below).
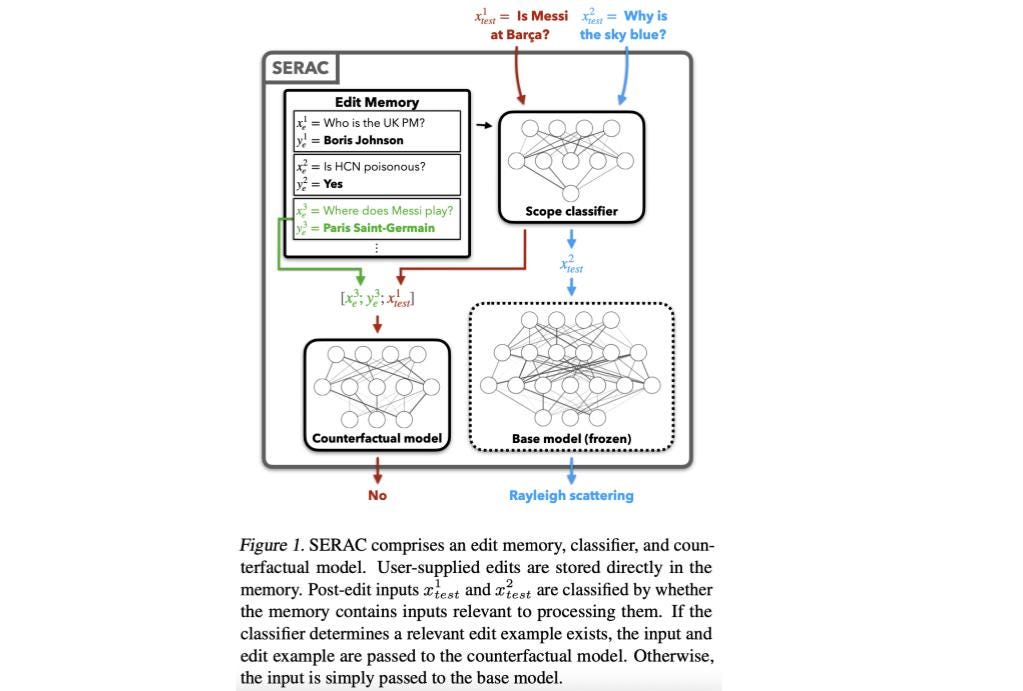
One of the main advantages of this approach is that it doesn’t require constant curation of the whole knowledge corpus unlike something like web-GPT, but simply iteratively updating user-added facts. Moreover, it can be added to existing large frozen LMs out-of-the-box without the need to retrain from scratch with some non-parametric memory system.
5. A Neural Corpus Indexer for Document Retrieval
By Yujing Wang et al.
❓ Why → We highlighted the Differentiable Search Index (DSI) back in march: fully parametrizing a whole corpus in a neural network and performing document retrieval by the autoregressive generation of document identifiers. This work takes that to the next level!
💡 Key insights → The Differentiable Search Index [6] is a wild approach to Information Retrieval (IR) that we highlighted back in March. Instead of retrieving a document by doing some lexical matching, embedding nearest neighbor search, or reranking via cross-encoding; the model simply memorizes the document corpus and generates autoregressively a list of document ids that are relevant to the given query. This is a priori mind-blowing cause document ids contain no semantically relevant information: if a new document appears and is given a new id, you can’t infer anything about its content.
This retrieval paradigm has several obvious downsides such as the fact that the document collection cannot be easily extended after training is finished, but the initial results were extremely encouraging, especially in the zero-shot setting where the model learns without human-annotated query-doc pairs, and it learns from a self-supervised objective that relies solely on the document collection.
This work basically squeezes more performance from the DSI idea by applying several design improvements: a query generation model (Doc2Query [6]) that extends the coverage of what queries, using the best performing semantic ids (proposed in DSI), and a special weight decoder.
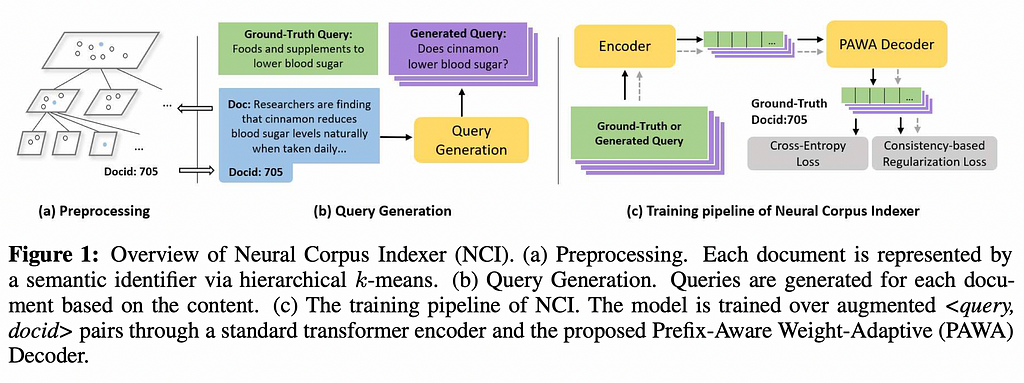
They test their model on the NQ320k retrieval task and their results are insanely good, although there’s a catch. Some of the models they compare themselves to were only trained on MS-Marco and then tested on NQ320k so it’s not really a fair comparison. Still, compared to the original DSI, they achieve an incredible performance bump (e.g. a recall@1 from 40% to 89%). Judging by their ablations, only the query generation module has a massive impact on performance, whereas the other proposed methods such as their special decoder barely make a difference, which is a very relevant finding.
6. Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos | Blog post | Code
By OpenAI et al.
❓ Why → Labelling is expensive and Reinforcement Learning tends to be very inefficient, especially in open games such as Minecraft. This paper proposes a very technique to work around this by reliably labeling gameplay videos automatically.
💡 Key insights → Learning what will be the next move of an agent in a videogame given previous images and moves (in other words autoregressive) is hard. However, if you let the model access the whole past and future frames of a videogame, guessing the action being taken at a given frame becomes easier. They leverage this simple trick to be much more efficient with how much human labeling is required.
First off, let me say the title of this paper is arguably misleading: Video PreTraining (VPT) actually does label actionsfrom videos. But instead of having people do it, they train a model to annotate raw videos with actions. Instead of doing it autoregresssively (i.e. guess what action will be taken given past action/frames) they let their model access past and future frames, which makes the task of annotating actions much easier to learn (i.e. guess what action is being taken given past and future video frames).
They call the model that learns to label raw videos an Inverse Dynamics Model (IDM), which is trained on 2k hours of data collected by having people play Minecraft while logging all their actions. The video dataset they collect consists of 270k hours of Minecraft gameplay from the internet, which are filtered and cleaned down to 70k, hours which are then automatically labeled with the IDM model.
An agent is trained on this dataset via Behavioral Cloning: predicting the action that should be taken by only seeing the previous frames and actions. One of the key results is how much it helps to look into the future for labeling videos to construct the IDM model.
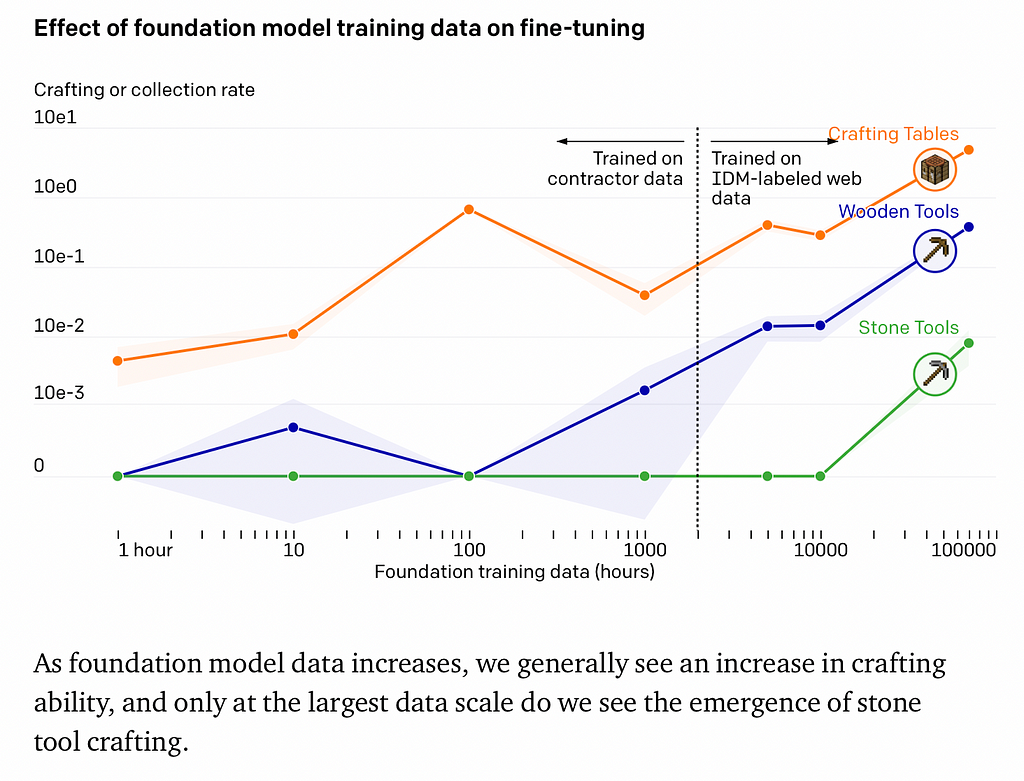
Besides Behavior Cloning, they also investigate fine-tuning with Reinforcement Learning, where the model has the opportunity to explore arbitrary trajectories and get rewards for it. While a randomly initialized RL agent fails to discover important complex action sequences in the game, RL finetuning works much better when initialized from the VPT model trained on BC, which discovers complex action sequences much more consistently and efficiently.
7. Solving Quantitative Reasoning Problems with Language Models | Demo page | Blog post
By Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh et al.
❓ Why → Solid reasoning ability — especially quantitative — is often pointed out as one of the weaknesses of large Language Models. Is this a fundamental limitation of large LMs or can it be circumvented simply by scaling up and being more clever about the training data?
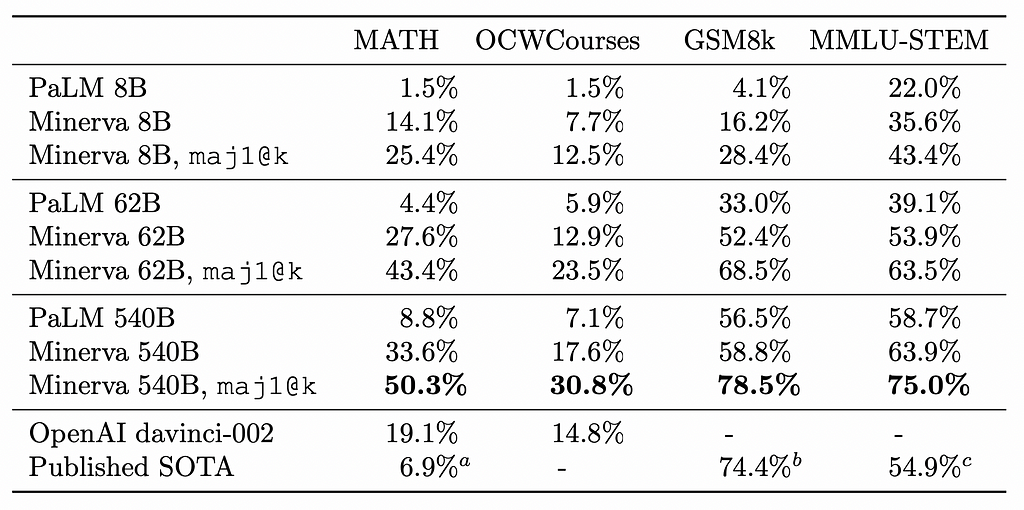
💡 Key insights → It turns out that by training on the right data and with the right tricks, LMs are skilled solvers of quantitative reasoning problems such as math or physics. This work builds upon PaLM [8] (with up to 540B parameters!) adding 118GB of data with mathy text from arXiv and math web pages. To encode the math, they simply leave the rax LaTeX expressions instead of flattening them out like previous works did. All models they train are a finetuning of the base PaLM.
They also find that using advanced prompting is essential for performance: chain of thought and scratchpad prompting; which consist of simple prompt reformatting strategies that have shown to empirically improve general reasoning abilities of pretrained LMs.
Finally, they also find that using majority voting also substantially improves the performance of the model, where a pool of candidate solutions for a problem is generated and a solution is chosen among the solutions that share the most common result.
This is undoubtedly still far from robust symbolic reasoning, it shows how far plain language modeling can get in reasoning with the right tricks and optimizations. If you’re interested in the subfield of reasoning with LMs, check out the recent Unveiling Transformers with LEGO: a synthetic reasoning task.
8. A Path Towards Autonomous Machine Intelligence (JEPA)
By Yann LeCun.
❓ Why → After Bengio’s consciousness prior [3] and Hinton’s GLOOM [4], Lecun joins his co-Turing Award Winners by presenting what he considers the path towards human-level AI.
💡 Key insights → This long position paper from Yann LeCun explains his vision on how human-level intelligence can be achieved, although he humbly makes it clear that getting there is a whole other story from just stating the hand wavy principles. Drawing from what we know of child development and brain function, he focuses on the need for “hierarchies of world models”, through which a model can continuously match its perception with how well it maps to its existing model of how the world works across a wide range of time and space scales, which he calls energy minimization.
In current Reinforcement Learning terms, he’s basically advocating for a Model-based paradigm with advanced representation learning-powered largely by self-supervised learning.
Honesty, it’s hard to tell how useful such a paper is. On one hand, it’s laudable that the chief scientist at a large private research lab would openly share his research vision. On the other hand, this paper proposes a cognitive architecture like we’ve seen hundreds of in the past with some explanatory success in the neuroscience field but not so much on the engineering side of building intelligent machines. Will this path get us closer to human-level AI, or should we be looking somewhere else cause like Plank said “science progresses one funeral at a time”?
9. ARF: Artistic Radiance Fields | Project page | Code
By Kai Zhang, Nick Kolkin, Sai Bi, Fujun Luan, Zexiang Xu, Eli Shechtman, Noah Snavely.
❓ Why → Sort of like style transfer but for 3D renders.
💡 Key insights → Neural Radiance Fields (NeRF [9]) are neural networks that can synthesize novel photorealistic views of a given scene. This work presents a NeRF that enables generating views of a scene with arbitrary styles.
To do so, they add a styling term to the loss function called Nearest Neighbor Feature Matching (NNFM) which steers the model to produce an output with similar image representations (i.e. VGG features). It’s not as simple as it sounds though, a lot of optimization tricks are required to make this work such as deferred back-propagation, which enables training on full resolution images instead of only a subset of image pixels.
The authors explain that existing 3D stylization approaches that operate on point clouds or meshes are sensitive to geometric reconstruction errors, which is not the case for the method proposed in this paper, being one of its core strengths.
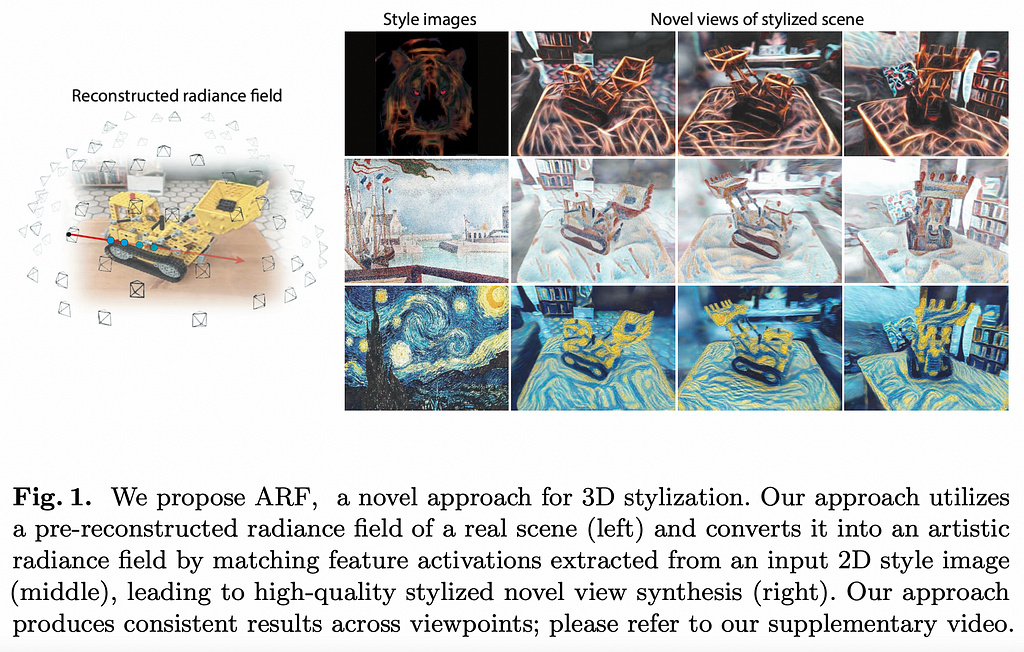
It might be a bit gimmicky but there’s definitely artistic potential behind this, especially in the context of Virtual Reality and videogames. The results are too cool to not include them here! You must their videos on their project page to get a better sense of how styled 3D scenes look like.
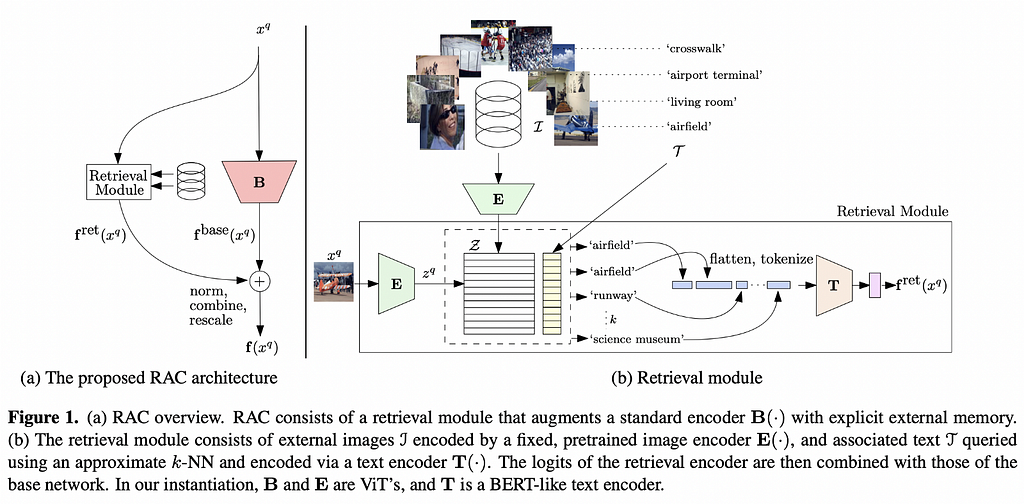
10. Retrieval Augmented Classification for Long-Tail Visual Recognition
By Alexander Long, Wei Yin, Thalaiyasingam Ajanthan, Vu Nguyen, Pulak Purkait, Ravi Garg, Alan Blair, Chunhua Shen, Anton van den Hengel.
❓ Why → Learning from data in the long tail of a distribution is hard: a model needs to learn from very few instances of such data. Augmenting ML with explicit retrieval modules is a trend we’ve highlighted in the past which has already improved areas such as text generation. Now it’s also applied to image classification.
💡 Key insights → An input image is routed in parallel through two systems: a regular base image encoder and a retrieval module. The retrieval module encodes the image into an embedding and finds its nearest neighbours in a database of images that are paired with text snippets, which can be labels or longer captions. The list of text snippets from the images is then concatenated and fed into a BERT-like text encoder that produces one text embedding.
The embedding from the base image encoder and that from the text encoder are added together after normalization, providing the classification layer of the network with extra information about the image being classified, which is useful in the low data regime. Given that this process is end-to-end differentiable, it can be trained jointly end to end.
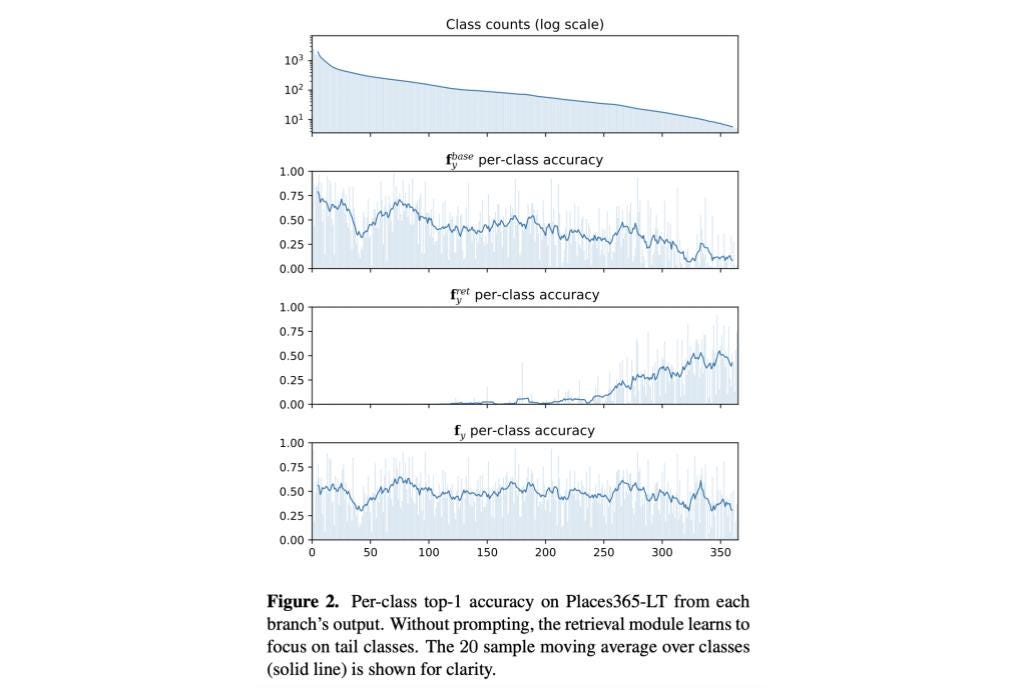
One of the most fascinating findings is that with an adequate balanced learning objective, the retrieval module learns to focus on tail classes as the base encoder doesn’t have enough labeled samples to learn from properly, as can be seen in the figure below (see how the retrieval module-only per class classification accuracy increases for classes with low sample counts).
References:
[1] “InPars: Data Augmentation for Information Retrieval using Large Language Models” by Luiz Bonifacio, Hugo Abonizio, Marzieh Fadaee, Rodrigo Nogueira; 2022.
[2] “Language Models are General-Purpose Interfaces” by Yaru Hao, Haoyu Song, Li Dong, Shaohan Huang, Zewen Chi, Wenhui Wang, Shuming Ma, Furu Wei; 2022.
[3] “The Consciousness Prior” by Joshua Bengio, 2019.
[4] “How to represent part-whole hierarchies in a neural network” by Geoffrey Hinton, 2022.
[5] “WebGPT: Browser-assisted question-answering with human feedback” by Reiichiro Nakano et al. 2021.
[6] “Transformer Memory as a Differentiable Search Index” by Yi Tay et al. 2022.
[7] “Document Expansion by Query Prediction” by Rodrigo Nogueira, Wei Yang, Jimmy Lin, Kyunghyun Cho; 2019.
[8] “PaLM: Scaling Language Modeling with Pathways” by Aakanksha Chowdhery et al. 2022.
[9] “NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis” by Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, Ren Ng. 2020.
Trends in AI — July 2022 was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






