



Streamline ML Workflow with MLflow — II
Last Updated on March 25, 2024 by Editorial Team
Author(s): ronilpatil
Originally published on Towards AI.
Let’s take our ML workflow to the next level with MLflow! Part — II of our blogU+1F680
If you’ve not gone through Part — 1, refer to the link below U+1F447
Streamline ML Workflow with MLflow️ — Part I
PoA — Experiment Tracking U+1F504 U+007C Model Registry U+1F3F7️ U+007C Model Serving U+1F680
pub.towardsai.net
In a previous blog we covered Experiments & Model Tracking, now we’ll cover Model Registry & Model Serving. It’ll be super interesting!
Table of Content
— Intro to Model Registry
— Intro to Model Serving
— Register & Serve the Model via MLflow UI
— Fetch Registered Model via MLflow API
— REST Endpoint using FastAPI
— Client Endpoint
— Streamlit Web App
— ClimaxU+26A1
— Register & Serve the Model via MLflow API
— GitHub Repo
— Conclusion
Model Registry
Model Registry is like a library where we keep all our trained machine-learning models organized and ready for deployment. Think of it as a central hub for managing our models throughout their lifecycle. Features of Model Registry :
- The Model Registry stores all our trained machine-learning models in one place. Each model is saved with its version number, making it easy to keep track of different versions and changes over time.
- The concept of “model stages” has been deprecated in favor of “model aliases”.
Model aliases provide a more flexible way to manage model versions. Each model version can have one or more aliases, which are user-defined labels or tags. Aliases can represent different aspects of the model version like we can create an aliaschampionthat links toversion-1of the modelproduction. To referproduction(model_name) -> version-1model, we can use the URImodels:/{model_name}@{alias_name}with API to serve that model into production.
Aliases are very handy for deploying models. For example, we can create achampionalias for the model version suited for production traffic and use this alias in production workloads. Now to upgrade the production model we don't need to make any changes in the production code, just upgrade the model in the model registry by reassigning the champion alias to a different model version. One key aspect of aliases is that we cannot reassign the same aliases, aliases will be unique to each Model Registry. - The Model Registry keeps track of different versions of your models. This lets us compare different versions, revert to previous versions if needed, and see how our models have improved over time.
For model details, refer to this super useful official doc.
Model Serving
Model Serving in MLflow is a great way for organizations to put their machine learning models into action and provide real value to their users and applications in production environments.
The whole workflow I created and deployed in my local machine, we can easily create and deploy a docker container on GCP’s Container Registry or Amazon’s ECS (Elastic Container Service).
Instead of getting lost in theoretical discussions, let’s dive straight into the practical. Look, Model Registry & Model Serving can be achieved using the MLflow UI as well as Python API.
Register & Serve the Model via MLflow UI
Let’s first register and serve the model to the production environment using the MLflow UI, and then do the same with the MLflow API.
Step 1. Select the most superior model that outperforms the others, either from the training experiments or tuned models.
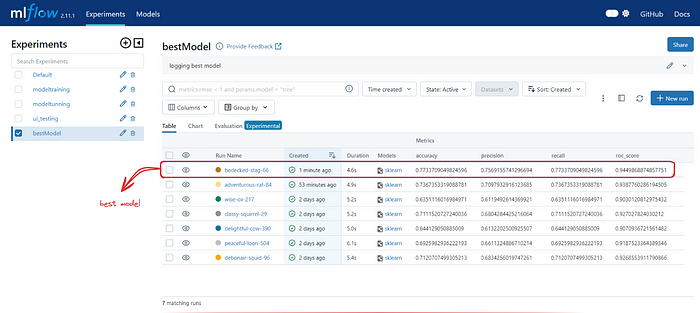
Step 2. Now, click on the outperforming model, then click on the Register model tab.

Step 3. Either create a new model or register it under the existing one.

Step 4. Once the model has been registered, go to the model’s tab to get a list of all registered models.
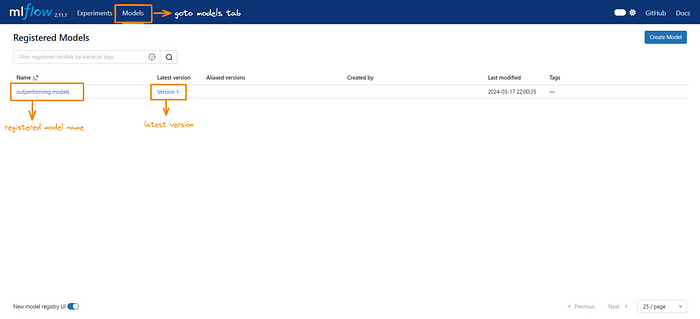
Step 5. Click on the registered model, here we have the option to add descriptions and tags.
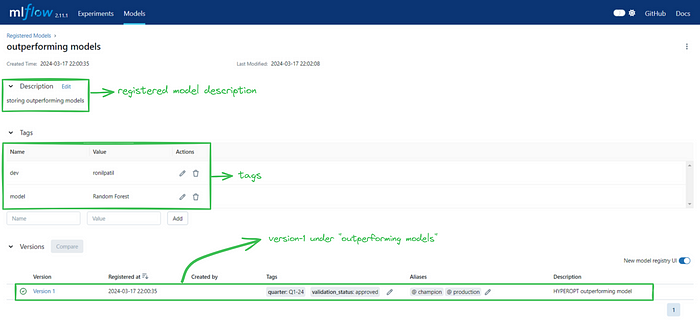
Step 6. Click on version 1, in versions we have options to set the description, tags, and the most important aliases. That’s all!
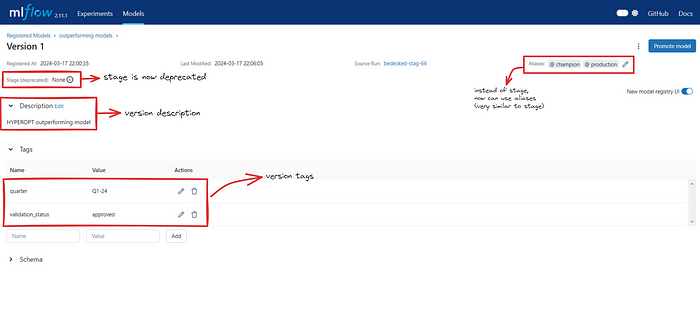
The UI part ends here, now API will be the next game changer.
Fetch Registered Model via MLflow API
We can retrieve the registered model by version no. or model alias. Below is a code snippet that will fetch the model from the backend store URI (SQLite) based on the given version no. or model alias.
REST Endpoint using FastAPI
Created an endpoint that will fetch the model with the alias production and make predictions using it.
Client Endpoint
Built a simple client-side endpoint for interacting with the API, sending requests, and receiving responses.
Below attached a snapshot of the API response for reference.

Streamlit Web App
Built a simple streamlit app for prediction. Below added code & snapshot for reference.
Client-side App:

ClimaxU+26A1
The API and Streamlit app retrieve the model from the model URI and make the prediction. Now you want to upgrade the model, just follow the below steps.
Step 1. First, train/tune the mode or choose an efficient model from the experiments.
Step 2. Next, create a new model under the model registry or add the model as a new version under the existing model(model registry).
Step 3. If you created a new model, don’t forget to add a description and tags to the newly registered model.
Step 4. Goto a newly created version, add the necessary description, tags, and provide a unique alias. We may use the production alias as a tag so that if we find a model that beats our current production model, we can tag the production alias to that model. As we know we cannot assign the same alias to multiple versions of the same model, the production alias will be immediately removed from the old version and allocated to the new version, which is our outperforming model. That’s it! Now we don’t need to make any modifications to the API or the app, if they are already in production just refresh them and the model upgrade will be reflected in all services. This is the beauty of MLflow U+1F5A4
I registered one more model under outperforming models and tagged production alias to it. Below added few snapshots for reference.
Assigning Production alias to best-performing model.

The new version created under outperforming models — model registry.

Just refresh the App or reload the API service, model upgradation will automatically reflect in the API & Web App.

Register & Serve the Model via MLflow API
Whatever actions we can perform manually through the MLflow UI, same things we can achieve programmatically using the MLflow API. I’ve added comments for your ease. For model details, you can refer to the MLflow doc.
-- Plan of Action --
1. Search an efficient model from experiments which is having best metrics
in its territory and get the details of it
2. Take reg. model name from user
3. check given register model already exist or not...
if already exist :
- get the production model details from given reg. model
- compare the performance metrics of old model(prod model) & new model
- if new model outperforming
- register that model & put it into production env
else:
- don't do anything, as high performing model already in
production
else :
- Register that model(version-1)
- Add description and assign some tags to registered model
- Add description to the latest version along with tags and aliases
GitHub Repo
The codebase is available here, just Fork it and start experimenting with it.
GitHub — Streamline ML Workflow with MLFlow Part— II
Built an E2E MLFlow Pipeline. Contributed by ronylpatil
github.com
Conclusion
That’s all guys, hope you enjoyed the blog. If this blog sparked your curiosity or ignited new ideas, follow me on Medium, GitHub & connect on LinkedIn, and let’s keep the curiosity alive.
Your questions, feedback, and perspectives are not just welcomed but celebrated. Feel free to reach out with any queries or share your thoughts.
Thank youU+1F64C &,
Keep pushing boundariesU+1F680
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

