



MLOps Notes 3.1: An Overview of Modeling for machine learning projects
Last Updated on January 7, 2023 by Editorial Team
Author(s): Akhil Theerthala
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
MLOps Notes 3.1: An Overview of Modeling for machine learning projects.
Welcome back, everyone! This is Akhil Theerthala. In the last article we have explored the standard practices and challenges faced during the deployment phase of the Machine Learning lifecycle. Now we take one more step back and visit the Modelling stage.
This part focuses on the critical challenges faced in developing machine learning models, like dealing with skewed datasets or the interesting case where the model performs worse after deployment even though it has very good test scores and many other problems.
Note: Since this part is a bit long, I have decided to split it into 3 different articles. One describes the details of developing the model, the other describes the standard procedures used for error analysis, and in the last one, we will look into more details about the data-driven approach for modeling.
Model-centric Approach vs. Data-Centric Approach
Until recently, there has been a lot of emphasis on choosing a suitable model for the project on a fixed benchmarked dataset, as most of the machine learning community was focused solely on research. This perspective is called Model-centric AI development. However, in recent days, we see a shift to another approach called Data-centric AI development, where we focus on improving the model architecture and making sure that we give it high-quality data.
The data-centric approach generally focuses on understanding and optimizing the quality, relevance, and representation of the data used to train the model. In contrast, the model-centric approach focuses more on the model’s design and optimization than the training data.
Ultimately, any machine learning project aims to build a model that can generalize well to new, unseen data. Achieving this requires careful consideration of the data, the model being used, and a range of other factors, such as the choice of algorithms, hyperparameter optimization, and model evaluation and validation.
One thing we need to keep in mind is that an AI system is a combination of the model (code) and the data used. One quick trip to GitHub gives us access to many machine-learning models that are trained extensively and work well with a bit of tweaking. This changes our priorities from working on the model to optimizing the data we give as input to the model as the latter approach is both easy and economical in most cases.
What do we mean by model development?
We have to remember that the model development is an iterative problem, where we tweak the hyperparameters like the learning rate, regularization constant, etc. Generally, wthe space of hyperparameters is relatively limited; hence in this part, our focus will be more on the code and the data.
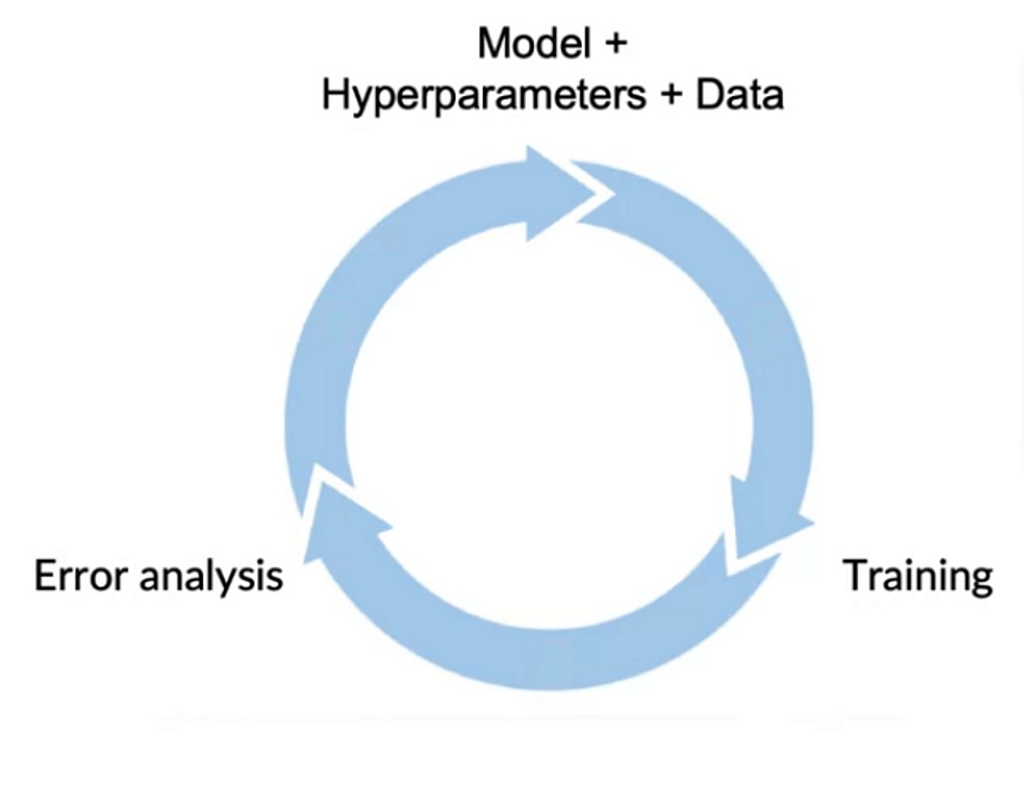
The above figure describes the iterative nature of model development, where we change the hyper-parameters and the way the data is defined depending upon the performance of the model on the previous set of parameters and data. In each loop through the cycle, we have to make sure that the decisions we make are good enough to improve the model’s performance. After this loop, we have to make one final audit analysis before sending it to the next part.
There are 3 different milestones that are generally considered before deploying a model. They are,
- Performance on the training dataset.
- Performance on the dev/test datasets.
- Performance w.r.t business metrics/project goals.
Until recently, only the first 2 milestones were commonly considered, but lately, it has come to our knowledge that low test set error is not good enough for the model to work well in production because of the different kinds of challenges faced during deployment. We have discussed a few of those in the last article.
We also know about the concept drift/ knowledge drift problem from the last article; now, let us see some other challenges that could make us retrain and rethink about our model.
Low average test error good enough. Why?
One of the most common and simple metric that is used to finalise and deploy a model is the average test error. But even though it is low, we can find cases where this metric is not enough. Some of those cases are listed below.
i) Bad performance on a set of disproportionately essential examples.
- The model with low test error could be neglecting the different kinds or classes in the training dataset. To understand this issue better, lets look at an example where we are using a search engine model.
- When using the model, if we search for Apple pie recipes. We generally forgive the search model for not giving us the “Best” apple pie recipe as we go through 2~3 different search results. These kinds of queries are called “Informational and Transactional queries.”
- Now, consider a different search like “IITKGP homepage”; we tend to be unforgiving when the search model returns the homepage of IIT Bombay or IIT Madras and quickly lose trust in this search engine. These kinds of queries are called “Navigational queries”.
- Hence, we can see that the Navigational queries are a set of disproportionate examples which are equally important. A model with low average error on the test set can give near-perfect responses, which are suitable for informational queries, but can’t be good enough for navigational queries.
ii) Performance on Key-slices of a dataset.
- To understand this, let us consider a model for loan approval. For this, we need to make sure that the model follows the laws or rules for different kinds of ethnicity, gender, location, language, etc.,
- Or, we can consider a model for product recommendations from the retailer. We must ensure that the model recommends the best suitable product rather than sidelining the lesser-known brands and only recommending the well-known brands to the retailer.
These cases don’t explicitly give the intended results even with a low test error. We need to ensure that the model provides better results irrespective of the different slices in the dataset.
iii) Skewed Dataset/ Rare Classes
- In medical diagnoses, it is expected that 99% of the patients don’t have a deadly disease like lung cancer, but rather only ~1% of the people who visit the clinic does. In this case, only predicting that the patient doesn’t have a disease gives us 99% accuracy. Hence, we need to make sure the model recognize this 1% of the cases and gives its results based on valid reasons.
Don’t just dump the training set into the model. Take a step (or few steps) back!
In the beginning phase of any machine learning practitioner’s journey, it is comkon that we dump the data to the model and expect it to miraculously generate high quality results. And in some cases like working with the MNIST dataset, they actually do. However as we move to more complicated projects, we start to see our model to struggle. Or we cannot judge the performance of the model based on it’s error or the metrics we define. That is why, it is recommended to take a few steps before you start training a model.
- The first step for training any model is establishing a baseline, which can be used to compare and improve our model over this baseline performance.
- This baseline can be anything, a simple linear regression model or something more targeted or complex like a Human-Level performance, which gives us what to compare.
- The baseline is established differently for different kinds of tasks. For example, when we work with Unstructured data like images/audio/text, we tend to compare the performance with Human-level performance. Still, with structured data, where we need to work with large databases or spreadsheets, we use other different baselines.
- Some of the standard baselines are,
– Human-level performances
– Literature search for state-of-the-art results or open-source results
– Quick-and-dirty implementations
– Performance of older systems. - After the first step, it is recommended to do a quick literature search to see what’s possible. For practical purposes, it is optional to look at the state-of-the-art approach. Just look at what is a reasonable approach.
- Also, consider the deployment constraints if they are already established. If the project is to see what is possible, then there is no need for you to focus on deployment constraints.
- Based on your approach till now, try to do sanity checks for the code, like trying to overfit over a small dataset, to make sure it is working correctly. For example, in Andrew’s implementation of a speech transcription system, he first tried to feed it only 1 audio clip and trained the model. He then obtained only a file with empty ‘ ‘s as an output.
Thanks for reading my article patiently upto now. I hope you enjoyed it. I am trying to improve the quality of my writing, but, as you can see I am still in the beginning phase. I need more data and feedback so that I can perform error analysis on my writing skills and retrain them.
Speaking of error analysis, the draft of the next part of this article (3.2) is completed and I am editing it. So expect it soon!
In the meantime, if you want to read my notes on CNN, you can read them here, or if you still haven’t read the last part of MLOps notes, you can find them here or in the links provided below. Thanks for reading!
P.S. you can subscribe using this link if you like this article and want to be notified as soon as a new article releases:
- MLOps Notes -1: The Machine Learning Lifecycle
- MLOps Notes- 2: Deployment Overview
- Join me in my journey through Machine Learning…
MLOps Notes 3.1: An Overview of Modeling for machine learning projects was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts


")



