



Let’s explore transfer learning…
Last Updated on December 21, 2023 by Editorial Team
Author(s): Tejasri Masina
Originally published on Towards AI.
Let’s approach this using some simple questions.
- What is transfer learning?
- Why is it used, and what are its benefits?
- Example for this Transfer Learning Models?
What is Transfer Learning?
There are many definitions that describe transfer learning — it essentially involves utilizing the knowledge of pretrained models to solve new problems.
What is Pretrained model?
Pre-trained models are those that have already been trained on a large dataset.
Why it is used and its benefits?
There are numerous benefits to transfer learning. Typically, when using deep neural networks, training from scratch requires a very large dataset and significant computational power. To overcome these challenges, transfer learning proves to be immensely helpful.
Benefits of this are…
- Requiring less computational power, transfer learning techniques can be executed using existing resources and a small amount of local training data. This approach saves storage space and runtime.
- It can be trained on a small amount of data because it has already been trained on a large dataset. When utilizing such a model, only a small amount of data is required.
- It saves time and enhances the learning speed as well.
To gain a deeper understanding…
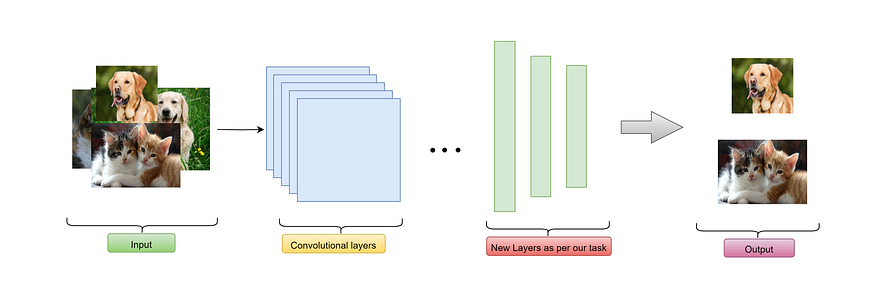
In this, we observed that we can modify the dense layers according to the requirements of our application.
Example for this Transfer Learning Models?
Many pre-trained models exist, such as…
- Xception, ResNet, VGG, MobileNet, Efficient Net, AlexNet etc…..
You can check here
Let’s delve into an example of a transfer model and explore its architecture.

The VGG models represent a type of CNN architecture developed by Karen Simonyan and Andrew Zisserman of the Visual Geometry Group (VGG) at Oxford University. They achieved remarkable results in the ImageNet Challenge. There are two main variations: VGG16 and VGG19. The experiment involved six models with varying numbers of trainable layers, and among these, the most popular are VGG16 and VGG19.
VGG was trained on the ImageNet dataset, comprising 1.2 million images for training across 1000 categories.
If we examine the architecture of VGG16…

Convolutional Layer : convolutional layer is made up of a collection of learnable filters that undergo a convolution operation on the input data. The network may learn hierarchical representations of the data because with such filters, which identify features in the input. In order to extract local patterns, like edges or textures, each filter slides over the input and applies a mathematical operation to help in feature extraction in neural networks.
In VGG16
All Convolutional Layers has
- Filter size = 3×3
- Stride = 1
- Padding = same
Max Pooling : Max-pooling reduces the quantity of the data while maintaining essential information for effective learning, avoiding small variation in the data by choosing the highest values from segments of the data.
Max Pooling Layers has
- Filter size = 2×2
- stride = 2
In the first convolutional layer, the image size is 224x224x64. After that it is reduced to 112×112

To gain a clear understanding of the architecture…

This is about Vgg16.
For a deeper understanding of how VGG16 works, I recommend referring to this resource.
VGGNet-16 Architecture: A Complete Guide
Explore and run machine learning code with Kaggle Notebooks U+007C Using data from multiple data sources
www.kaggle.com
Let’s code this to gain a better understanding.
Here, I’d like to demonstrate with code.
Here, I’ve used the Corn or Maize dataset for a classification task that involves four types of classes.
- Blight
- Common_Rust
- Gray_Leaf_Spot
- Healthy




Corn or Maize Leaf Disease Dataset
Artificial Intelligence based classification of diseases in maize/corn plants
www.kaggle.com
The dataset which I used
Now the implementation part
Step 1 : Import all necessary libraries
import numpy as np
from glob import glob
import random
import splitfolders
import os
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore", category=FutureWarning)
I divided the dataset into three parts: train, validation, and test.
os.makedirs('output1')
os.makedirs('output1/train')
os.makedirs('output1/val')
os.makedirs('output1/test')
loc = "/kaggle/input/corn-or-maize-leaf-disease-dataset/data"
splitfolders.ratio(loc,output ="output1",ratio = (0.80,.1,.1))
train_path = '/kaggle/working/output1/train'
val_path = '/kaggle/working/output1/val'
Resizing all the image sizes to 224×224.
IMAGE_SIZE = [224, 224]
Step 2 : Importing model and its libraries
import tensorflow as tf
from keras.layers import Input, Lambda, Dense, Flatten
from keras.models import Model
from keras.applications.vgg16 import VGG16
from keras.applications.vgg16 import preprocess_input
from keras.preprocessing import image
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
Step 3 : Model Training
model = VGG16(input_shape=IMAGE_SIZE + [3], weights='imagenet', include_top=False)
IMAGE_SIZE + [3]
Here, we’re including the RGB channel because our images is in color.
weights=‘imagenet’
We’re utilizing the weights from ImageNet.
include_top = False
As VGG16 typically expects images of size 224×224, we can accommodate different pixel sizes by including the top layer.
for layer in model.layers:
layer.trainable = False
This step is crucial because we don’t want to retrain the already-trained layers in the model, so we set it to false.
Afterward, we can add our dense layers.
x = Flatten()(model.output)
prediction = Dense(len(folders), activation='softmax')(x)
model = Model(inputs=model.input, outputs=prediction)
model.summary()

After this, we compile and fit the model.
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss='categorical_crossentropy',
metrics = ['accuracy'])
r = model.fit_generator(
training_set,
validation_data=val_set,
epochs=10,
steps_per_epoch=len(training_set),
validation_steps=len(val_set)
)
Output
I got a validation accuracy of 89.92%.
To gain a clear understanding of the implementation of this corn classification using the transfer model, you can check it out on my GitHub. I’ve tested the model with an image, and it predicted accurately.
GitHub – Tejasri-123/Corn-Classification
github.com
In the GitHub repository, you can find all the files that I included in this article.
Thank you for reading………
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

")