


Finetuning LLMs for ReAct
Author(s): Pranav Jadhav
Originally published on Towards AI.
In this article, I will share my findings in benchmarking and finetuning open-source language models for ReAct (Reasoning + Acting). I demonstrate that finetuning can dramatically improve the accuracy of LLMs in answering multi-hop questions using ReAct. I also present a new dataset that can be used to finetune models for the ReAct format presented by the original paper (Yao et al., 2022). My findings indicate that, through finetuning, open-source LLMs show promise for making agents that can effectively reason and use tools.
Language Models Reasoning?
Since ChatGPT started the language model gold rush, we’ve been consistently surprised by the abilities of these neural networks to imitate our speech and writing. However, a key component of intelligence that distanced these models from ourselves was reasoning. The reasoning barrier first faltered when chain-of-thought (CoT) prompting was introduced by Wei et al. in 2022. They found that simply prompting the language model to “think step by step” and output intermediate reasoning steps improved accuracy on question-answering tasks. However, the reasoning ability of LLMs didn’t end there. Another development in reasoning was chain-of-thought with self-consistency (CoT-SC), where multiple reasoning traces were generated and the majority answer is returned as the final answer (Wang et al., 2022). Then in late 2022, a team of researchers from Princeton University and Google Research published a paper called ReAct: Synergizing Reasoning and Acting in Language Models. In this paper, the team introduces a method of prompting LLMs to output a sequence of thought, action, and observation steps to reach a final answer.
What is ReAct?
Simply put, ReAct is a prompting strategy to force an LLM to “reason” about what it is doing and interact with tools using actions. I will give a basic explanation here, but for a deep dive, I recommend looking at the blog post or the paper.
The best way to illustrate what ReAct does and why it is effective is with an example. Take a look at this graphic from the paper:
With CoT only, the language model can get past the first reasoning step but then hallucinates an incorrect answer because it does not have access to up-to-date information. With Act-Only, the model fails to correctly make use of the outputs from the tool (Wikipedia search). With ReAct the model gets the best of both worlds: it can access Wikipedia and reason about the outputs. Note: The question shown in the example above is from HotPotQA, a dataset containing thousands of multi-hop question-answering tasks. This is one of the datasets used in the paper to test ReAct and the one I will be using for this article.
ReAct with open LLMs
My goal with this article is to share my findings in replicating ReAct with open-source models to help developers in the community make agents. I believe that reasoning is one of the “holy grails” in our search for AGI and breaking down the barrier of LLM reasoning is crucial. With that let’s jump into some code.
I am going to walk you through the process that I went through in this section, but note that I used an A-100 GPU for finetuning. The benchmark script is not as resource intensive and may be run given enough RAM for mistral-7b.
The first thing I wanted to do was benchmark the open-source models that are widely available today for ReAct. Luckily, the ReAct code is publicly available at this repo, and with a few modifications, we can run the same benchmark script that the authors used in the paper. Run the following command to, clone the ReAct repo into your working directory.
git clone https://github.com/ysymyth/ReAct.git
The file “hotpotqa.ipynb” is what we are interested in. This script runs ReAct on a language model with 500 random samples from HotPotQA and prints the accuracy. To benchmark mistral and llama all I did was modify the script to use those models instead of openAI. I achieved this with vLLM, for detailed installation instructions see here. Below is the code I used to benchmark ReAct with Mistral:
from vllm import LLM, SamplingParams
model = LLM(
model='mistralai/Mistral-7B-v0.1',
)
def llm(prompt, stop):
sampling_params = SamplingParams(
temperature=0,
top_p=1,
max_tokens=100,
stop=stop
)
return model.generate(prompt, sampling_params)[0].outputs[0].text
import wikienv, wrappers
import requests
env = wikienv.WikiEnv()
env = wrappers.HotPotQAWrapper(env, split="dev")
env = wrappers.LoggingWrapper(env)
def step(env, action):
attempts = 0
while attempts < 10:
try:
return env.step(action)
except requests.exceptions.Timeout:
attempts += 1
import json
import sys
folder = './prompts/'
prompt_file = 'prompts_naive.json'
with open(folder + prompt_file, 'r') as f:
prompt_dict = json.load(f)
webthink_examples = prompt_dict['webthink_simple6']
instruction = """Solve a question answering task with interleaving Thought, Action, Observation steps. Thought can reason about the current situation, and Action can be three types:
(1) Search[entity], which searches the exact entity on Wikipedia and returns the first paragraph if it exists. If not, it will return some similar entities to search.
(2) Lookup[keyword], which returns the next sentence containing keyword in the current passage.
(3) Finish[answer], which returns the answer and finishes the task.
Here are some examples.
"""
webthink_prompt = instruction + webthink_examples
def webthink(idx=None, prompt=webthink_prompt, to_print=True):
question = env.reset(idx=idx)
if to_print:
print(idx, question)
prompt += question + "\n"
n_calls, n_badcalls = 0, 0
for i in range(1, 8):
n_calls += 1
thought_action = llm(prompt + f"Thought {i}:", stop=[f"\nObservation {i}:"])
try:
thought, action = thought_action.strip().split(f"\nAction {i}: ")
except:
print('ohh...', thought_action)
n_badcalls += 1
n_calls += 1
thought = thought_action.strip().split('\n')[0]
action = llm(prompt + f"Thought {i}: {thought}\nAction {i}:", stop=[f"\n"]).strip()
obs, r, done, info = step(env, action[0].lower() + action[1:])
obs = obs.replace('\\n', '')
step_str = f"Thought {i}: {thought}\nAction {i}: {action}\nObservation {i}: {obs}\n"
prompt += step_str
if to_print:
print(step_str)
if done:
break
if not done:
obs, r, done, info = step(env, "finish[]")
if to_print:
print(info, '\n')
info.update({'n_calls': n_calls, 'n_badcalls': n_badcalls, 'traj': prompt})
return r, info
import random
import time
idxs = list(range(7405))
random.Random(233).shuffle(idxs)
rs = []
infos = []
old_time = time.time()
for i in idxs[:500]:
try:
r, info = webthink(i, to_print=True)
except:
info = {"em": False}
rs.append(info['em'])
infos.append(info)
print(sum(rs), len(rs), sum(rs) / len(rs), (time.time() - old_time) / len(rs))
print('-----------')
print()
The changes are at the top where I redefine the llm function using Mistral-7b with vLLM. The nice thing about vLLM is that it follows openAI’s API so we can just plug it in. In the final loop, I added some exception handling to the final loop to make sure it doesn’t stop for any reason. Another noteworthy point is the prompt, which explains how ReAct is working. Let’s take a closer look.
Solve a question answering task with interleaving Thought, Action, Observation steps. Thought can reason about the current situation, and Action can be three types:
(1) Search[entity], which searches the exact entity on Wikipedia and returns the first paragraph if it exists. If not, it will return some similar entities to search.
(2) Lookup[keyword], which returns the next sentence containing keyword in the current passage.
(3) Finish[answer], which returns the answer and finishes the task.
Here are some examples.
Question: What is the elevation range for the area that the eastern sector of the Colorado orogeny extends into?
Thought 1: I need to search Colorado orogeny, find the area that the eastern sector of the Colorado orogeny extends into, then find the elevation range of the area.
Action 1: Search[Colorado orogeny]
Observation 1: The Colorado orogeny was an episode of mountain building (an orogeny) in Colorado and surrounding areas.
Thought 2: It does not mention the eastern sector. So I need to look up eastern sector.
Action 2: Lookup[eastern sector]
Observation 2: (Result 1 / 1) The eastern sector extends into the High Plains and is called the Central Plains orogeny.
Thought 3: The eastern sector of Colorado orogeny extends into the High Plains. So I need to search High Plains and find its elevation range.
Action 3: Search[High Plains]
Observation 3: High Plains refers to one of two distinct land regions:
Thought 4: I need to instead search High Plains (United States).
Action 4: Search[High Plains (United States)]
Observation 4: The High Plains are a subregion of the Great Plains. From east to west, the High Plains rise in elevation from around 1,800 to 7,000 ft (550 to 2,130 m).[3]
Thought 5: High Plains rise in elevation from around 1,800 to 7,000 ft, so the answer is 1,800 to 7,000 ft.
Action 5: Finish[1,800 to 7,000 ft]
Question: Musician and satirist Allie Goertz wrote a song about the "The Simpsons" character Milhouse, who Matt Groening named after who?
Thought 1: The question simplifies to "The Simpsons" character Milhouse is named after who. I only need to search Milhouse and find who it is named after.
Action 1: Search[Milhouse]
Observation 1: Milhouse Mussolini Van Houten is a recurring character in the Fox animated television series The Simpsons voiced by Pamela Hayden and created by Matt Groening.
Thought 2: The paragraph does not tell who Milhouse is named after, maybe I can look up "named after".
Action 2: Lookup[named after]
Observation 2: (Result 1 / 1) Milhouse was named after U.S. president Richard Nixon, whose middle name was Milhous.
Thought 3: Milhouse was named after U.S. president Richard Nixon, so the answer is Richard Nixon.
Action 3: Finish[Richard Nixon]
Question: Which documentary is about Finnish rock groups, Adam Clayton Powell or The Saimaa Gesture?
Thought 1: I need to search Adam Clayton Powell and The Saimaa Gesture, and find which documentary is about Finnish rock groups.
Action 1: Search[Adam Clayton Powell]
Observation 1: Could not find [Adam Clayton Powell]. Similar: ['Adam Clayton Powell III', 'Seventh Avenue (Manhattan)', 'Adam Clayton Powell Jr. State Office Building', 'Isabel Washington Powell', 'Adam Powell', 'Adam Clayton Powell (film)', 'Giancarlo Esposito'].
Thought 2: To find the documentary, I can search Adam Clayton Powell (film).
Action 2: Search[Adam Clayton Powell (film)]
Observation 2: Adam Clayton Powell is a 1989 American documentary film directed by Richard Kilberg.
The film is about the rise and fall of influential African-American politician Adam Clayton Powell Jr.[3][4] It was later aired as part of the PBS series The American Experience.
Thought 3: Adam Clayton Powell (film) is a documentary about an African-American politician, not Finnish rock groups. So the documentary about Finnish rock groups must instead be The Saimaa Gesture.
Action 3: Finish[The Saimaa Gesture]
Question: What profession does Nicholas Ray and Elia Kazan have in common?
Thought 1: I need to search Nicholas Ray and Elia Kazan, find their professions, then find the profession they have in common.
Action 1: Search[Nicholas Ray]
Observation 1: Nicholas Ray (born Raymond Nicholas Kienzle Jr., August 7, 1911 - June 16, 1979) was an American film director, screenwriter, and actor best known for the 1955 film Rebel Without a Cause.
Thought 2: Professions of Nicholas Ray are director, screenwriter, and actor. I need to search Elia Kazan next and find his professions.
Action 2: Search[Elia Kazan]
Observation 2: Elia Kazan was an American film and theatre director, producer, screenwriter and actor.
Thought 3: Professions of Elia Kazan are director, producer, screenwriter, and actor. So profession Nicholas Ray and Elia Kazan have in common is director, screenwriter, and actor.
Action 3: Finish[director, screenwriter, actor]
Question: Which magazine was started first Arthur's Magazine or First for Women?
Thought 1: I need to search Arthur's Magazine and First for Women, and find which was started first.
Action 1: Search[Arthur's Magazine]
Observation 1: Arthur's Magazine (1844-1846) was an American literary periodical published in Philadelphia in the 19th century.
Thought 2: Arthur's Magazine was started in 1844. I need to search First for Women next.
Action 2: Search[First for Women]
Observation 2: First for Women is a woman's magazine published by Bauer Media Group in the USA.[1] The magazine was started in 1989.
Thought 3: First for Women was started in 1989. 1844 (Arthur's Magazine) < 1989 (First for Women), so Arthur's Magazine was started first.
Action 3: Finish[Arthur's Magazine]
Question: Were Pavel Urysohn and Leonid Levin known for the same type of work?
Thought 1: I need to search Pavel Urysohn and Leonid Levin, find their types of work, then find if they are the same.
Action 1: Search[Pavel Urysohn]
Observation 1: Pavel Samuilovich Urysohn (February 3, 1898 - August 17, 1924) was a Soviet mathematician who is best known for his contributions in dimension theory.
Thought 2: Pavel Urysohn is a mathematician. I need to search Leonid Levin next and find its type of work.
Action 2: Search[Leonid Levin]
Observation 2: Leonid Anatolievich Levin is a Soviet-American mathematician and computer scientist.
Thought 3: Leonid Levin is a mathematician and computer scientist. So Pavel Urysohn and Leonid Levin have the same type of work.
Action 3: Finish[yes]
Under the hood, it’s pretty simple. The prompt asks the model to follow a certain format and describes how that format works. The prompt also provides five examples of ReAct traces. Then to solve a new question, we can simply append it at the end of this prompt and the model will continue generating in the same format. This brings me to another interesting finding —I found that the base models tend to do much better than chat models at ReAct. I think this is because chat models are tuned for back-and-forth conversation, but here the name of the game is sticking to the ReAct format which base models tend to do better at. Otherwise, the parsing code will not be able to figure out what the model wants to do which is important to perform the right action or pass the right string to the Wikipedia search API. Note: The Wikipedia API functionality is handled by other files in this ReAct repository which is why it’s important to run all this code inside the ReAct repo.
Here are the results I got from benchmarking Mistral-7b and llama-2:

I’ve also included the results for Palm-540B and GPT-3 from the ReAct paper. We can see that open-source LLMs are catching up with impressive performances from Mistral-7b and Llama2–70b, but there is still a small margin for the closed models. Note: to benchmark llama2–70b I used the same code shown above but instead of serving the language model with vLLM I used llama-cpp-python with LangChain to run a Q5 quantization of llama-70b. That is beyond the scope of this article but I wanted to show the result in this table for comparison.
Now that I had a benchmark, I wanted to finetune these models for ReAct and see how much better they can do.
Finetuning
In addition to testing ReAct with in-context learning, the authors of the ReAct paper also showed results with models finetuned for the ReAct format. They found the finetuned models to be superior to the models prompted with examples in context.
Dataset Generation
While the paper was not extremely detailed in how they generated their finetuning dataset, they revealed the following about their strategy:
“Due to the challenge of manually annotating reasoning traces and actions at scale, we consider a bootstraping approach similar to Zelikman et al. (2022), using 3,000 trajectories with correct answers generated by ReAct (also for other baselines) to finetune smaller language models” — (Yao et. al., 2023).
Essentially, they used a larger model to generate 3,000 ReAct trajectories with correct answers and used that to finetune smaller language models. I decided to replicate this with open-source LLMs by using llama2–70b to generate reasoning traces. I generated the samples by modifying the benchmark code to run over the training set of HotPotQA and save correct reasoning trajectories to a JSON file. The dataset I created is available on Huggingface.
Finetuning Mistral
Let’s get into the finetuning code. I’d like to credit this great blog post from Maximme Labonne which this code is adapted from. First, let's run all the necessary imports.
import os
import gc
import torch
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
TrainingArguments,
pipeline,
logging,
)
from peft import LoraConfig, PeftModel
from trl import SFTTrainer
from huggingface_hub import login
import wandb
hf_token = "YOUR_HF_TOKEN"
wb_token = "YOUR_WB_TOKEN"
wandb.login(key=wb_token)
login(token=hf_token)
To visualize training status I used wanb, but it is not required. Next, let’s load the dataset and format it for finetuning.
prompt = """Solve a question answering task with interleaving Thought, Action, Observation steps. Thought can reason about the current situation, and Action can be three types:
(1) Search[entity], which searches the exact entity on Wikipedia and returns the first paragraph if it exists. If not, it will return some similar entities to search.
(2) Lookup[keyword], which returns the next sentence containing keyword in the current passage.
(3) Finish[answer], which returns the answer and finishes the task."""
def prompt_format(example):
example['text'] = f"{prompt}\nQuestion: {example['question'].strip()}\n{example['trajectory']}"
return example
# Load dataset and process it to have text field with combined prompt and trajectory
dataset = load_dataset("xz56/react-llama")['train']
dataset = dataset.remove_columns(['correct_answer', 'id'])
dataset = dataset.map(prompt_format)
This combines the prompt, question, and trajectory into one block of text we can use to finetune the LLM. Next, we need to load the base model quantized for QLoRa training.
# Set QLoRa configuration
compute_dtype = getattr(torch, "float16")
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype="float16",
bnb_4bit_use_double_quant=False,
)
# Load the base model
model = AutoModelForCausalLM.from_pretrained(
"mistralai/Mistral-7B-v0.1",
quantization_config=bnb_config,
device_map={"": 0}
)
model.config.use_cache = False
model.config.pretraining_tp = 1
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
Now we can set the LoRa configuration and initialize the trainer.
# Load LoRA configuration
peft_config = LoraConfig(
lora_alpha=32,
r=16,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=['q_proj', 'k_proj', 'v_proj', 'o_proj', 'gate_proj', 'up_proj' , 'down_proj'],
)
# Set training parameters
training_arguments = TrainingArguments(
output_dir="mistral-7b-ReAct-checkpoints",
num_train_epochs=1,
per_device_train_batch_size=2,
gradient_accumulation_steps=1,
optim="paged_adamw_32bit",
save_steps=25,
save_total_limit=3,
logging_steps=25,
learning_rate=5e-5,
fp16=False,
bf16=True,
max_grad_norm=0.3,
max_steps=-1,
warmup_steps=100,
lr_scheduler_type="constant",
report_to="wandb"
)
# Set supervised fine-tuning parameters
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
max_seq_length=1200,
dataset_text_field='text',
tokenizer=tokenizer,
args=training_arguments,
packing=False,
)
The important parameters here are lora_alpha, r, target_modules, and learning_rate. Here’s a quick breakdown:
- r (rank): relates to the number of trainable parameters LoRa will have.
- lora_alpha: is a scaling parameter for the weights of a mode. Many sources suggest setting alpha = 2 * rank.
- target_modules: what linear layers of the mistral-7b architecture are being updated? More = higher RAM requirements.
- learning_rate: Determines the step size of each weight update. This affects the training curve a lot and the value that I settled on came after trial and error.
All that’s left to do is begin training!
trainer.train()
Here’s what my loss curve looked like:

After training is complete we need to merge the trained LoRa model with the original to benchmark it.
# Flush memory
import gc
gc.collect()
torch.cuda.empty_cache()
# Reload base model
base_model = AutoModelForCausalLM.from_pretrained(
"mistralai/Mistral-7B-v0.1",
return_dict=True,
torch_dtype=torch.float16,
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Merge base model with the adapter
# Change checkpoint_path to the path of the checkpoint you want to merge
checkpoint_path = "mistral-7b-ReAct-checkpoints/<path-of-checkpoint>"
model = PeftModel.from_pretrained(base_model, checkpoint_path)
model = model.merge_and_unload()
# Save model and tokenizer
new_model_path = "mistral-7b-ReAct"
model.save_pretrained(new_model_path)
tokenizer.save_pretrained(new_model_path)
During training, I saved the last three checkpoints, which allowed me to select the checkpoint at which the loss was lowest from the last three when merging. After saving the new model, we are ready to benchmark again!
Results
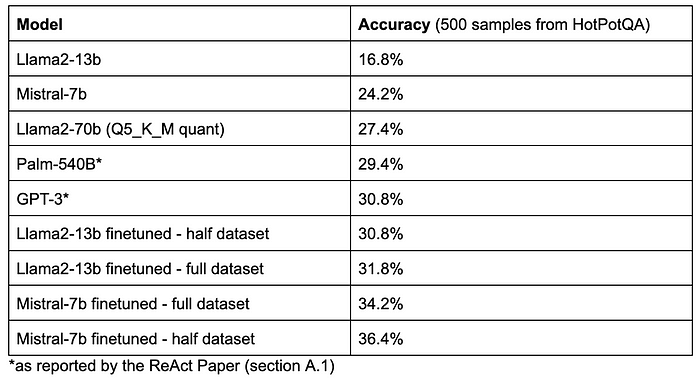
I conclude that finetuning can significantly improve the ability of language models to be effective agents and answer complex multi-hop questions. It’s impressive how mistral-7b was able to outperform much larger models. Interestingly, training with only half of the dataset did slightly better than training with the full dataset. I think this may be because the entire dataset is generated by llama2-70b so after a certain point in finetuning the model has learned all it can from the signal that the dataset provides. This is something I want to experiment with more because I expected a dramatic improvement from doubling the size of training data.
I hope that my findings inspire others to tinker with and improve open-source LLMs for reasoning tasks. I believe that performant open-source agents are viable and experiments like these from the community will continue to bring us towards that goal.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts

")





