



Fine-Tuning Models using Prompt-Tuning with Hugging Face’s PEFT Library
Last Updated on November 5, 2023 by Editorial Team
Author(s): Pere Martra
Originally published on Towards AI.
This article is part of a free course about Large Language Models available on GitHub.
If you’re reading this, it means you’re genuinely interested in novel techniques for Fine-Tuning Large Language Models. I’ve been entirely unable to come up with a title that’s even remotely comprehensible, let alone appealing, to someone unfamiliar with Fine-Tuning.
Let’s see if I can at least manage to explain what we’re going to explore in this article so you can decide if it’s truly what you’re looking for.
I’ll begin with a brief explanation of what Prompt Tuning is. I understand that at this point, you already fully understand what Fine-Tuning is.
Once we understand the technique and its applications, we will study the notebook containing the example.
In the notebook, we will train two different models, but starting from the same pretrained model. This will allow us to see one of the most distinctive features of this fine-tuning technique: memory savings by enabling multiple models with different purposes to reside in memory while loading only one pretrained model.
Is this what you were looking for? Well, let’s dive right into it.
What is Prompt Tuning?
It’s an Additive Fine-Tuning technique for models. This means that we WILL NOT MODIFY ANY WEIGHTS OF THE ORIGINAL MODEL. You might be wondering, how are we going to perform fine-tuning then? Well, we will train additional layers that are added to the model. That’s why it’s called an Additive technique.
Considering it’s an Additive technique and its name is Prompt-Tuning, it seems clear that the layers we’re going to add and train are related to the prompt. EXACTLY! That’s correct.
A prompt is nothing more and nothing less than the instructions we give to the model to perform an action. We write them in our language, i.e., natural language, but the model receives tokens in its language. In large language models, we often refer to them as embeddings, which are numerical representations of the text we send in the prompt.

The embeddings on the right represent the phrase ‘I am your Prompt.’ To carry out the training, what we do is add some additional spaces to the input model’s embeddings, and it’s those embeddings that will have their weights modified through training.

In other words, we are creating a kind of superprompt by allowing a model to supplement part of the prompt with what it has learned. However, that part of the prompt cannot be translated into natural language. It’s as if we’ve learned to express ourselves in embeddings and create incredibly efficient prompts.
All the weights of the pretrained model are locked and, therefore, cannot be modified during the training phase.
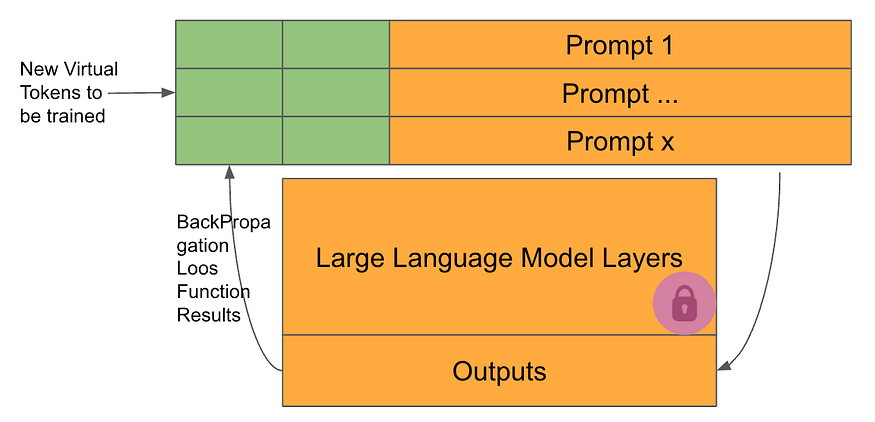
In each training cycle, the only weights that can be modified to minimize the loss function are the ones incorporated into the prompt.
The first consequence of this technique is that the number of parameters to train is really small. However, we run into a second, maybe more important consequence, which is that because we don’t alter the weights of the pretrained model, it doesn’t change its behavior or forget anything it has previously learned.
Our Notebook.
The notebook is available on Github:
Large-Language-Model-Notebooks-Course/5-Fine Tuning/Prompt_Tuning_PEFT.ipynb at main ·…
Practical course about Large Language Models. . Contribute to peremartra/Large-Language-Model-Notebooks-Course…
github.com
And it is part of the Large Language Models Course:
GitHub – peremartra/Large-Language-Model-Notebooks-Course: Practical course about Large Language…
Practical course about Large Language Models. . Contribute to peremartra/Large-Language-Model-Notebooks-Course…
github.com
As I mentioned earlier, we’re going to train two models. The first will be a model specialized in generating prompts for large language models. The second will be trained to create motivational phrases.
To achieve this, we will use two datasets and a single pretrained model.
Datasets used:
- https://huggingface.co/datasets/fka/awesome-chatgpt-prompts
- https://huggingface.co/datasets/Abirate/english_quotes
The Model: Any model from the Bloom family. In the notebook, I’ve used bigscience/bloomz-560m and bigscience/bloom-1b1.
The first thing we’re going to do is load some of the libraries to be used in the notebook. Please note that I loaded the libraries needed in Colab. If you prefer to work in your environment, you might already have some of them loaded, or you may need to install others.
!pip install peft
!pip install datasets #necesary to load the Datasets.
# !pip install transformers #If you don't have transformers library installed
from transformers import AutoModelForCausalLM, AutoTokenizer
Now we can load the model and the tokenizer.
model_name = "bigscience/bloomz-560m"
#model_name="bigscience/bloom-1b1"
NUM_VIRTUAL_TOKENS = 4
NUM_EPOCHS = 5
While I’ve conducted tests with two of the models from the Bloom family, we could have used any model that’s compatible with Prompt Tuning for Casual Modeling Language in the PEFT library. You can check the compatible models in the library’s GitHub repository: https://github.com/huggingface/peft#models-support-matrix
The variable NUM_VIRTUAL_TOKENS contains the number of tokens we want to add to the prompt, which will be trainable. You can modify the value to test how it affects the result; more tokens means more parameters to be trained.
Now, let’s load the tokenizer and model. Note that with larger models, the download time may increase. I set the trust_remote variable to True so that the model can execute code for its installation, if necessary.
tokenizer = AutoTokenizer.from_pretrained(model_name)
foundational_model = AutoModelForCausalLM.from_pretrained(
model_name,
trust_remote_code=True
)
The tokenizer is responsible for translating between natural language and tokens understood by the model, and vice versa. It translates the input prompt and the model’s outputs.
Loading the tokenizer and the model is straightforward using the classes provided by the Hugging Face Transformers library.
With this, we already have the model in memory, and we can conduct an initial test without performing any fine-tuning. This way, we can observe how the results change after the two fine-tuning processes.
An initial test with the pretrained model.
To execute the model call, I’m going to create a function that takes: the model, the model’s input, and the maximum response length.
#this function returns the outputs from the model received, and inputs.
def get_outputs(model, inputs, max_new_tokens=100):
outputs = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
max_new_tokens=max_new_tokens,
repetition_penalty=1.5, #Avoid repetition.
early_stopping=True, #The model can stop before reach the max_length
eos_token_id=tokenizer.eos_token_id
)
return outputs
Getting a response from the model will be as simple as calling this function and waiting for the model to provide us with the result. As I’ve chosen to train two different models, I’ll conduct two tests.
input_prompt = tokenizer("I want you to act as a motivational coach. ", return_tensors="pt")
foundational_outputs_prompt = get_outputs(foundational_model, input_prompt, max_new_tokens=50)
print(tokenizer.batch_decode(foundational_outputs_prompt, skip_special_tokens=True))
[“I want you to act as a motivational coach. Don’t be afraid of being challenged.”]
input_sentences = tokenizer("There are two things that matter:", return_tensors="pt")
foundational_outputs_sentence = get_outputs(foundational_model, input_sentences, max_new_tokens=50)
print(tokenizer.batch_decode(foundational_outputs_sentence, skip_special_tokens=True))
[‘There are two things that matter: the size and shape of a flower’]
It can’t be said that any of the answers are incorrect. The model complements the sentence we’ve given, but it doesn’t know our intention or how we want it to behave. We’ll attempt to address this in the fine-tuning phase, where we will train each model with specific sentences to make it respond with a different personality after each fine-tuning.
Let’s see if we can change the behavior of the pretrained model in the two fine-tuning processes.
Preparing the Datasets.
We’ll load each dataset separately. To improve performance, I’m only going to load a small number of rows from each of them.
from datasets import load_dataset
dataset_prompt = "fka/awesome-chatgpt-prompts"
#Create the Dataset to create prompts.
data_prompt = load_dataset(dataset_prompt)
data_prompt = data_prompt.map(lambda samples: tokenizer(samples["prompt"]), batched=True)
train_sample_prompt = data_prompt["train"].select(range(50))
train_sample_prompt = train_sample_prompt.remove_columns('act')
display(train_sample_prompt)
In this example, I’m removing the ‘act’ column from the dataset. It’s a design decision; I truly believe it doesn’t contribute significantly. However, you can test how it affects the results if we keep the column. It’s as easy as commenting out the line that removes the column; the rest of the notebook continues to work.
Let’s see the first row of the Dataset:
{‘act’: [‘Linux Terminal’], ‘prompt’: [‘I want you to act as a linux terminal. I will type commands and you will reply with what the terminal should show. I want you to only reply with the terminal output inside one unique code block, and nothing else. do not write explanations. do not type commands unless I instruct you to do so. when i need to tell you something in english, i will do so by putting text inside curly brackets {like this}. my first command is pwd’]}
I believe that by keeping only the information from the ‘Prompt’ column, we can achieve better results. I’ve tested it, and I think it is the best option. But feel free to run the test yourselves.
dataset_sentences = load_dataset("Abirate/english_quotes")
data_sentences = dataset_sentences.map(lambda samples: tokenizer(samples["quote"]), batched=True)
train_sample_sentences = data_sentences["train"].select(range(25))
train_sample_sentences = train_sample_sentences.remove_columns(['author', 'tags'])
display(train_sample_sentences)
For the second dataset, I’ve followed the exact same strategy, removing columns that I consider less relevant.
Now we have the data in two datasets: train_sample_sentences and train_sample_prompt. Since we’ve already loaded the model and the tokenizer, we’re ready to begin the fine-tuning process.
Fine-tuning with PEFT.
The first step is to create an object with the training configuration. We’ll be using the PromptTuningConfig method, but it offers various options, and we need to specify which ones we want to use.
from peft import get_peft_model, PromptTuningConfig, TaskType, PromptTuningInit
generation_config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM, #This type indicates the model will generate text.
prompt_tuning_init=PromptTuningInit.RANDOM, #The added virtual tokens are initializad with random numbers
num_virtual_tokens=NUM_VIRTUAL_TOKENS, #Number of virtual tokens to be added and trained.
tokenizer_name_or_path=model_name #The pre-trained model.
)
Using PromptTuningConfig, we create a variable that holds the configuration we should use in the call to get_peft_model. Let’s examine the parameters we are passing to it:
- task_type: With the value CAUSAL_LM, we are indicating that we want to fine-tune a model for text generation.
- prompt_tuning_info: This allows us to specify an initial value for the added vectors that can be trained. In this case, I’m indicating that they should be initialized with random values. However, we could also specify that they all start with a specific value, providing a text. I haven’t detected significant differences using one method or the other. To do so, we would need to specify the values:
— prompt_tuning_info = PromptTuningInit.TEXT
— prompt_tuning_init_text = “Initial text here” - num_virtual_tokens: The number of tokens added to each prompt that can be trained. It should maintain a relationship with the length of the prompts we are going to send. The shorter the prompt, the fewer virtual tokens should be configured for training. Increasing them doesn’t always lead to better model performance.
- tokenizer_name_or_path: The name of the model.
To create the model to fine-tune, all we need to do is call get_peft_model and provide it with the pretrained model we have selected and the configuration we just created.
We will create two models using the same configuration and pretrained model.
peft_model_prompt = get_peft_model(foundational_model, generation_config)
print(peft_model_prompt.print_trainable_parameters())
trainable params: 4,096 U+007CU+007C all params: 559,218,688 U+007CU+007C trainable%: 0.0007324504863471229 None
peft_model_sentences = get_peft_model(foundational_model, generation_config)
print(peft_model_sentences.print_trainable_parameters())
trainable params: 4,096 U+007CU+007C all params: 559,218,688 U+007CU+007C trainable%: 0.0007324504863471229 None
What do you think? We’re going to train a model by modifying only 0.0007% of its weights. This is spectacular! It’s even more remarkable when you consider that in the paper “The Power of Scale for Parameter-Efficient Prompt Tuning” you can achieve results equivalent to full fine-tuning.
Once we have the model, we need to create the training configuration. We achieve this with the TrainingArguments class, which I’m going to place within a function to be able to use different arguments for each of the models.
from transformers import TrainingArguments
def create_training_arguments(path, learning_rate=0.0035, epochs=6):
training_args = TrainingArguments(
output_dir=path, # Where the model predictions and checkpoints will be written
use_cpu=True, # This is necessary for CPU clusters.
auto_find_batch_size=True, # Find a suitable batch size that will fit into memory automatically
learning_rate= learning_rate, # Higher learning rate than full fine-tuning
num_train_epochs=epochs
)
return training_args
In the first parameter, we see that we’re specifying a directory. This directory will contain the fine-tuned model, and it’s mandatory to pass it. The other parameters are already familiar. The learning_rate, which indicates the maximum weight change allowed in each step, and num_train_epochs, which specifies the number of epochs we want for the training.
The following code only creates the directories that will hold the models in case they don’t exist.
working_dir = "./"
#Is best to store the models in separate folders.
#Create the name of the directories where to store the models.
output_directory_prompt = os.path.join(working_dir, "peft_outputs_prompt")
output_directory_sentences = os.path.join(working_dir, "peft_outputs_sentences")
#Just creating the directoris if not exist.
if not os.path.exists(working_dir):
os.mkdir(working_dir)
if not os.path.exists(output_directory_prompt):
os.mkdir(output_directory_prompt)
if not os.path.exists(output_directory_sentences):
os.mkdir(output_directory_sentences)
Now we can create the training arguments for each model.
training_args_prompt = create_training_arguments(output_directory_prompt, 0.003, NUM_EPOCHS)
training_args_sentences = create_training_arguments(output_directory_sentences, 0.0035, NUM_EPOCHS)
Let’s continue the fine-tuning process. I’m going to create a function that we will call for each model we want to fine-tune.
from transformers import Trainer, DataCollatorForLanguageModeling
def create_trainer(model, training_args, train_dataset):
trainer = Trainer(
model=model, # We pass in the PEFT version of the foundation model, bloomz-560M
args=training_args, #The args for the training.
train_dataset=train_dataset, #The dataset used to tyrain the model.
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False) # mlm=False indicates not to use masked language modeling
)
return trainer
We create the Trainer object, and to do so, we pass:
- The PEFT model is obtained from the call to get_peft_model.
- The arguments we created with TrainingArguments.
- The dataset we prepared at the beginning of the notebook.
- The result of calling DataCollatorForLanguageModeling, which prepares the dataset to be processed in blocks by the model.
Now we have everything ready to perform the fine-tuning of the models:
trainer_prompt = create_trainer(peft_model_prompt, training_args_prompt, train_sample_prompt)
trainer_prompt.train()
trainer_sentences = create_trainer(peft_model_sentences, training_args_sentences, train_sample_sentences)
trainer_sentences.train()
The model training process in Colab can take about 10 to 15 minutes. On my machine, a MacBook Pro with an M1 Pro chip, it takes around 3 minutes per model. As you can understand, the training conducted hasn’t been very exhaustive. Only a small amount of data and a few epochs were used. Feel free, I would even say it’s almost necessary, to adjust the parameters to perform fine-tuning with more data and epochs to see how the response of our models varies.
trainer_prompt.model.save_pretrained(output_directory_prompt)
trainer_sentences.model.save_pretrained(output_directory_sentences)
I save the models because one of the most important features of this type of training is the minimal disk and memory space they occupy. It’s true that they need to work in conjunction with the pretrained model, which needs to be loaded into memory. However, we could have n fine-tuned models that use the same pretrained model loaded into memory. With other fine-tuning techniques, we would need n copies of the pretrained model, since their weights would have been modified.
On my hard drive, each of the models I just saved occupies 300KB. Please check how much they occupy on yours, but it should be something similar.
Let’s load each of the models and make the same call as to the pretrained model to see if their response is the same or has been modified.
loaded_model_prompt_outputs = get_outputs(loaded_model_prompt, input_prompt)
print(tokenizer.batch_decode(loaded_model_prompt_outputs, skip_special_tokens=True))
I want you to act as a motivational coach. You can use this method if you’re not sure what your goals are.
Let’s compare the results:
- Pretrained Model: I want you to act as a motivational coach. Don’t be afraid of being challenged.
- Fine Tuned Model: I want you to act as a motivational coach. You can use this method if you’re not sure what your goals are.
It’s clear that the response is different, and therefore, we have influenced the model’s response with our fine-tuning process. While it may not resemble the prompts we’ve provided, it does resemble instructions more than the phrase from the pretrained model.
Let’s take a look at the second model:
loaded_model_sentences_outputs = get_outputs(loaded_model_sentences, input_sentences)
print(tokenizer.batch_decode(loaded_model_sentences_outputs, skip_special_tokens=True))
- Pretrained Model: There are two things that matter: the size and shape of a flower
- Fine Tuned Model: There are two things that matter: one is the weather and another, what you do.
So, more or less the same as with the first model. The important thing is that we have in memory two models that behave differently due to their fine-tuning, and we only have one copy of the pretrained model in memory.
Conclusion and continue.
The Prompt-Tuning technique is truly impressive. The results it yields are very promising, and the savings in both training and inference are remarkable.
Please use the notebook to do your own experiments. You can change the Model, the Epochs, the learning_rate, the Datasets. Investigate by yourself, it is the best way to learn.
Resources.
The full course about Large Language Models is available at Github. To stay updated on new articles, please consider following the repository or starring it. This way, you’ll receive notifications whenever new content is added.
GitHub – peremartra/Large-Language-Model-Notebooks-Course: Practical course about Large Language…
Practical course about Large Language Models. . Contribute to peremartra/Large-Language-Model-Notebooks-Course…
github.com
If you’re interested in delving deeper into the workings of Prompt-Tuning, take a look at this paper.
The Power of Scale for Parameter-Efficient Prompt Tuning
In this work, we explore "prompt tuning", a simple yet effective mechanism for learning "soft prompts" to condition…
arxiv.org
It’s quite easy to understand and provides you with an idea of when using prompt-tuning can be a good choice.
This article is part of a series where we explore the practical applications of Large Language Models. You can find the rest of the articles in the following list:

Large Language Models Practical Course
View list10 stories


I write about Deep Learning and AI regularly. Consider following me on Medium to get updates about new articles. And, of course, You are welcome to connect with me on LinkedIn, and twitter.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Take our 90+ lesson From Beginner to Advanced LLM Developer Certification: From choosing a project to deploying a working product this is the most comprehensive and practical LLM course out there!
Towards AI has published Building LLMs for Production—our 470+ page guide to mastering LLMs with practical projects and expert insights!

Discover Your Dream AI Career at Towards AI Jobs
Towards AI has built a jobs board tailored specifically to Machine Learning and Data Science Jobs and Skills. Our software searches for live AI jobs each hour, labels and categorises them and makes them easily searchable. Explore over 40,000 live jobs today with Towards AI Jobs!
Note: Content contains the views of the contributing authors and not Towards AI.
Related posts




Popular posts

 for 2021")



Updates

Recent Posts


