



Discovering LangChain: Chat with your Documents, Chatbot Translator, Chat with Wikipedia, Synthetic Data Generator
Last Updated on December 11, 2023 by Editorial Team
Author(s): Claudio Giorgio Giancaterino
Originally published on Towards AI.
The growth of the Generative AI world is also possible thanks to an important Python library: LangChain, and the interest has been growing in the last months, as shown by the following chart.
What is LangChain?
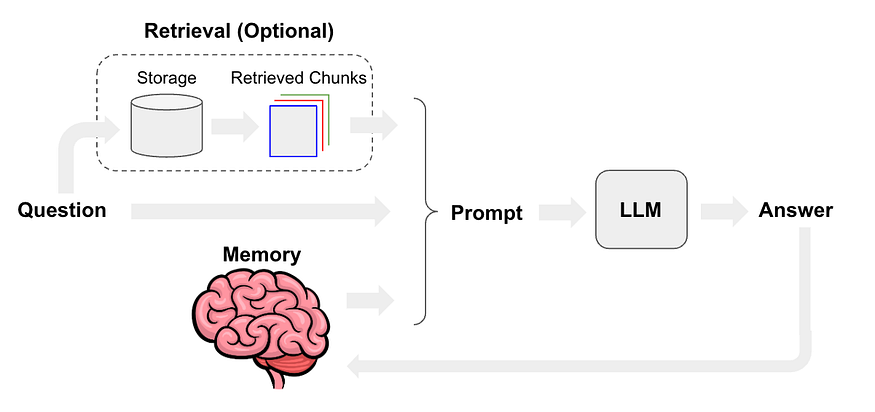
LangChain broadly speaking is a wrapper, more specifically it is a open-source framework designed for developing applications around Large Language Models.
The idea behind the framework is to “chain” together different components to build more advanced use cases exploiting LLMs.
LangChain is built under several components.
- Schema refers to the underlying structure of data that is used to build AI models, and it comes in different forms, including text, chat messages, and documents.
- Models: there are several models covered by the framework. Large Language Models which take a text string as input, and return a text string as output. Chat Models take a list of Chat Messages as input, and return a Chat Message. Text Embedding Models take text as input and return a vector, a list of floats.
- Prompts: they represent the new programming way of models. Bad prompts produce bad outputs, and good prompts are powerful. A good prompt can be structured using several objects, such as a template, with specific examples and output parsing.
- Indexes: they allow LLMs to interact with documents. They take a user’s query and return the most relevant information. There are several types of indexes, document loaders, text splitters, vector stores, and retrievers. Document loaders are used for loading documents from various sources, text splitters are used for breaking down the user’s query into smaller chunks, vector stores can store large amounts of embeddings and retrievers are used for retrieving relevant information from the loaded data.
- Memory: it allows the AI systems to remember previous conversations with users and understand the user’s context better. Memory is stored in the form of chat history.
- Chains: they are a sequence of responses produced by the AI system in response to a user’s input. There are simple chains based on a sequence of responses to a user’s question. Meanwhile, summarized chains, use natural language processing (NLP) algorithms to generate a summary of the user’s input to simulate human-like conversations.
- Agents: they are the software components that enable the AI system to interact with users. There are two types of agents: toolkits and agents. Toolkits are frameworks with the resources necessary to build AI applications. Agents are pre-built AI applications that can be used out-of-the-box to interact with customers.
Typical use cases of LangChain are document analysis, chatbots, summarization, code analysis and more….
In this article, I explored four use cases that you can follow in this notebook exploiting GPT 3.5 turbo from OpenAI.
Chat with your documents
In the first use case, I walked around the knowledge base Q&A. Easily, in this type of application, documents are loaded and split to create embeddings stored into a vector store, a data structure that facilitates the vector search process. With the user’s query, also converted in embedding, a semantic search works to retrieve the right information to produce the output answer.

For this task, I uploaded a paper about the review on sentiment analysis and emotion detection, then the result from one of my queries:
llm = ChatOpenAI(temperature=0, model_name='gpt-3.5-turbo')
chain = load_qa_chain(llm, chain_type="map_reduce")
query1 = "Could you explain the challenges in sentiment analysis
and emotion analysis showed in the document?"
docs = docsearch.similarity_search(query1)
chain.run(input_documents=docs, question=query1)
According to the provided information, the challenges in sentiment analysis
and emotion analysis mentioned in the document include:
Lack of resources: The document mentions that one of the challenges is the
lack of resources, specifically the difficulty in gathering a large annotated
dataset for statistical algorithms. Manual labeling of a large dataset
is time-consuming and less reliable.
Use of emotions: The document suggests that the use of emotions in sentiment
analysis and emotion analysis poses a challenge. It does not provide further
details on how this challenge manifests.
Spreading Web slang: The document mentions that spreading web slang is a
challenge in sentiment and emotion analysis. It does not provide further
details on how this challenge affects the analysis.
Lexical and syntactical ambiguity: The document states that lexical and
syntactical ambiguity is a challenge in sentiment and emotion analysis.
It does not provide further details on how this challenge impacts the analysis.
Lack of standard rules for communicating feelings: The document highlights
the lack of standard rules for communicating feelings across multiple platforms
as a challenge. It mentions that individuals express their emotions differently,
making it difficult for researchers to develop a technique that can work
efficiently in all domains.
Please note that the information provided is based on the given extracted parts
of the document, and there may be additional challenges mentioned in the full
document that are not included here.
Chatbot translator
In the second use case, I explored the typical conversational AI that, with the advent of ChatGPT, has been disrupted: the chatbot. For this goal, I used the schema based on the system that orchestrates Human messages and AI messages to perform a translation task.
The following is the result of one of my queries:
chat = ChatOpenAI(temperature=0, model_name='gpt-3.5-turbo')
chat([HumanMessage(content="Translate this sentence from English to German:
I'm interested in developing a start-up business")])
AIMessage(content='Ich interessiere mich für die Entwicklung
eines Start-up-Unternehmens.')
Here is the result starting from German to English by Google translator as a test….impressive!!!

I’m not fluent in German, and I think it can be helpful when you need to write/read something in another language.
Chat with Wikipedia
For the third task, I had the idea of Wikipedia pages web scraping, but I decided to choose the easiest way to exploit the Python library that facilitates access and parse data from Wikipedia. In this way, with “WikipediaRetriever,” I’m able to ask and obtain information that I need from the encyclopedia. Then, the results of my queries.
model = ChatOpenAI(temperature=0, model_name='gpt-3.5-turbo')
qa = ConversationalRetrievalChain.from_llm(model, retriever=retriever)
questions = [
"What is storm?",
"What is Sustainability?",
"What is climate change?",
]
chat_history = []
for question in questions:
result = qa({"question": question, "chat_history": chat_history})
chat_history.append((question, result["answer"]))
print(f"-> **Question**: {question} \n")
print(f"**Answer**: {result['answer']} \n")
-> **Question**: What is storm?
**Answer**: A storm is a weather event characterized by strong winds,
precipitation (such as rain, snow, or hail), and often thunder and lightning.
Storms can vary in intensity and duration, and can occur in various forms,
such as thunderstorms, hurricanes, blizzards, or tornadoes. Storms can cause
significant damage to property and pose risks to human safety.
-> **Question**: What is Sustainability?
**Answer**: Sustainability is a concept that refers to the ability to maintain
or support something over the long term. In the context of the environment,
sustainability often focuses on countering major environmental problems,
such as climate change, loss of biodiversity, and pollution. It involves
finding a balance between economic development, environmental protection, and
social well-being. Sustainability can guide decisions at the global, national,
and individual levels, and it aims to meet the needs of the present generation
without compromising the ability of future generations to meet their own needs.
-> **Question**: What is climate change?
**Answer**: Climate change refers to the long-term alteration of Earth's
climate patterns, including changes in temperature, precipitation, wind
patterns, and other aspects of the climate system. It is primarily caused by
human activities, particularly the burning of fossil fuels, which release
greenhouse gases into the atmosphere. These greenhouse gases, such as carbon
dioxide and methane, trap heat and contribute to the warming of the planet.
Climate change has a wide range of impacts on the environment, ecosystems, and
human societies, including rising sea levels, more frequent and intense extreme
weather events, loss of biodiversity, and threats to human health and
well-being. It is considered one of the greatest challenges facing humanity
and requires global efforts to mitigate its effects and adapt to the changes.
I think it’s a helpful tool for retrieving summary information when you want to consult Wikipedia.
Synthetic Data Generator
With the last task, I’ve thought of exploiting the generative power from ChatGPT in generating synthetic data. These artificially generated data imitate the features of real data without containing any information from actual individuals or entities.
For starting is necessary to give the structure of the data you want to generate, and for instance, the variables I want to generate are referred to as medical charges data.
class MedicalCharges(BaseModel):
ID: int
Age: int
BMI: float
Height: int
Children: int
Charges: float
To give a direction to the synthetic data generator, it’s helpful to provide a few real-world-like examples.
examples = [
{
"example": """ID: 123456, Age: 34, BMI: 27.9,
Children: 0, Height: 170, Charges: 1884.90"""
},
{
"example": """ID: 253459, Age: 45, BMI: 22.7,
Children: 2, Height: 167, Charges: 1725.34"""
},
{
"example": """ID: 323758, Age: 23, BMI: 18.9,
Children: 0, Height: 178, Charges: 3866.60"""
}
]
At this step, I can drive the synthetic data generator to create a prompt template with instructions to the Large Language Model on how to produce synthetic data in the right format.
OPENAI_TEMPLATE = PromptTemplate(input_variables=["example"],
template="{example}")
prompt_template = FewShotPromptTemplate(
prefix=SYNTHETIC_FEW_SHOT_PREFIX,
examples=examples,
suffix=SYNTHETIC_FEW_SHOT_SUFFIX,
input_variables=["subject", "extra"],
example_prompt=OPENAI_TEMPLATE,
)
Now, everything is ready to build a data generator model and synthetic data.
synthetic_data_generator = create_openai_data_generator(
output_schema=MedicalCharges,
llm=ChatOpenAI(temperature=1, model_name='gpt-3.5-turbo'),
prompt=prompt_template,
)
synthetic_results = synthetic_data_generator.generate(
subject="Medical_Charges",
extra="chosen at random",
runs=10)
Here are the results for 10 samples.

Synthetic data generation is a critically important cartridge for every data scientist because it can be used for testing, research, and training machine learning models while preserving privacy and security.
Final thoughts
The LangChain GitHub repository has reached more than 66k stars. It is a powerful tool that provides access to several large language models from various providers like OpenAI, Hugging Face, and Google, among others. These models can be accessed through API calls, allowing developers to build applications oriented to better productivity and just with a bit of code.
LangChain, with its features, is suitable to be integrated into every Company to build Conversational AI and other Generative AI tools around Large Language Models and will become a must-have tool.
References:
“A review on sentiment analysis and emotion detection from text”

Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

