



Comparing Dense Attention vs Sparse Sliding Window Attention
Last Updated on December 30, 2023 by Editorial Team
Author(s): Building Blocks
Originally published on Towards AI.
Introduction
A little over a month ago in part 1 of this series we identified the prevalence of sink tokens. These are a small subset of tokens that accumulate a large portion of the attention scores in Transformer models. We also find that they exist across different model architectures.
If you haven’t read part 1, we’d highly recommend it to better understand the context behind this article.
The observation of sink tokens makes one question the necessity of dense self-attention, where each token attends to all tokens in the sequence. In this article, we’ll explore the implications of using sparse self-attention instead. Where each token only attends to a limited set of tokens in the sequence.
The key observations from Part 1 that we’ll leverage in this article are:
- Special tokens such as [CLS], [SEP], etc. tend to be used as sink tokens.
- We observe that besides special tokens, the leading diagonal (left-to-right) region of an attention map, i.e., the tokens within a small distance of the token that we compute attention for, also tends to be an attention-activated (non-zero attention scores) zone.
- Attention scores are more spread out across tokens in the lower layers and become more concentrated in the sink tokens as we move to higher layers.
We’ll leverage these two observations and train a BERT (encoder-only architecture) model on a customized attention mask and compare the results of a BERT model that uses the default dense self-attention vs our customized mask.
The code corresponding to these experiments is publicly available in the form of a Jupyter notebook.
Attention Masks 101
The purpose of attention masks is to specify the tokens that need to be included in the self-attention operation. An attention mask value of 1 stands for inclusion, while a value of 0 means exclusion.
The shape of the attention mask tensor is the same as that of the input_ids tensor, meaning that there’s a one-to-one correspondence between the indices of the token ids and the values of the attention mask.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
sample_text = "Every night I lie in bed."
sample_text2 = "The brightest colors fill my head. A"
tokenizer([sample_text, sample_text2], padding=True)
>>> {'input_ids': [
[101, 2296, 2305, 1045, 4682, 1999, 2793, 1012, 102, 0],
[101, 1996, 26849, 6087, 6039, 2026, 2132, 1012, 1037, 102]
],
'attention_mask': [
[1, 1, 1, 1, 1, 1, 1, 1, 1, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
]
}
The code snippet above demonstrates how an out-of-the-box tokenizer creates attention masks. sample_text has one token less than sample_text2. However, we need all tensors to be of the same length to create a valid batch that we can pass to our model.
To get around this constraint, the tokenizer automatically appends an extra [PAD] token(corresponding to token id 0) to the end of sample_text. We also observe that this [PAD] token’s corresponding attention mask value is 0. This makes sense since the pad token wasn’t originally a part of our input and therefore shouldn’t be included in the self-attention operation.
To sum things up, a tokenizer's default behavior is to ensure that all pad tokens are excluded from self-attention. In our experiments, we’ll be overriding this default behavior to create custom attention masks.
Custom Attention Masks
Our custom attention masks will be characterized by:
- The special tokens [CLS] & [SEP] (the sink tokens) will always attend to all tokens.
- All tokens will always attend to [CLS] & [SEP].
- [PAD] tokens will always be masked.
- All other tokens will attend to tokens within a distance of k to the left and right of the token we’re computing attention scores for along with the special tokens as mentioned in 2. We’ll refer to k as the neighborhood distance from hereon.
We’ll refer to this attention by the name sparse sliding window attention. When visualized with k=1 an attention heat map looks like shown below.
Let’s take the token night since we attend to tokens within a distance of 1 we attend to every and i. We also attend to the [CLS] and [SEP] tokens since they are the sink tokens.
Experiments
Our experiments revolve around measuring the performance of fine-tuning a BERT model using dense attention vs sparse sliding window attention on 3 different classification tasks. Here’s an overview of the experiments:
- Fine-tuning a model using dense attention
- Fine-tuning a model using sparse sliding window attention in all layers.
- Fine-tuning a model using dense attention in the first 4 layers and sparse sliding window attention in the rest.
- Fine-tuning a model where the special tokens are not always attended to but are treated as all other tokens. They will attend to as well as be attended by only the k tokens in their neighborhood.
- Pre-training a model on the Masked Language Modeling objective with attention masks in the style of 3 and then fine-tuning it as in 3.
Datasets
We use the following datasets:
- DAIR-AI/Emotion: A dataset for emotion classification. It contains 6 classes. The classes are not uniformly distributed. Average number of tokens per document in the training set is 22.
- AG_NEWS: A dataset for classifying the topic of news. It contains 4 classes uniformly distributed in the train and test sets. Since no validation set is provided we split the training set into a train and validation split. Since this dataset is quite large and we have limited compute available we’ll use a subset of 30k data points as our train+validation split. Average number of tokens per document in the training set is 53.
- TweetEval/Offensive: A dataset for classifying if a tweet is offensive or not. The classes are not uniformly distributed. Average number of tokens per document in the training set is 33.
- OpenWebText: “An open-source replication of the WebText dataset from OpenAI, that was used to train GPT-2.” We use this dataset for continued pre-training.
Metrics
For this article, we’ll only report accuracy and macro-f1 scores. We’ll use the latter because it weights the performance of each class irrespective of population equally and gives a good picture of the model’s overall ability.
Implementation Details
We’ll use the bert-base-uncased model in all of our experiments. It contains 12 layers. We needed to override some functions in the BertEncoder and BertModel classes to get them working with our custom masks.
All of our experiments set k=2 which means that our sliding window will be just 5 (2 on the right + 2 on the left + the token itself) tokens long for non-special tokens + the special tokens if they aren’t in the range of the window.
Additionally, we needed to create custom collators to ensure that padding works correctly for our new attention masking scheme. Please refer to the notebook for the exact details.
Pre-training Hyper-parameters
We pre-train for just 500 steps, to reach a similar loss on the validation set that the pre-trained model with dense attention attains. The below snippet highlights the configs for pre-training. The resulting model is publicly available here.
pretraining_args = TrainingArguments(
output_dir='./bert-hybrid-sparse-sliding-window-attention', # output directory
max_steps=500, # total number of training steps
per_device_train_batch_size=16, # batch size per device during training
per_device_eval_batch_size=64, # batch size for evaluation
warmup_ratio=0.1, # number of warmup steps for learning rate scheduler
weight_decay=0.01, # strength of weight decay
logging_dir='./logs', # directory for storing logs
fp16=True,
gradient_checkpointing=True,
evaluation_strategy="steps",
eval_steps=100,
save_steps=100,
load_best_model_at_end=True,
logging_steps=100,
gradient_accumulation_steps=8,
push_to_hub=True
)
Fine-Tuning Hyper-parameters
We fine-tune models using 5 different random seeds per dataset. This is to ensure that we’re not getting lucky with the chosen random seed. We train for a total of 5 epochs for each training run.
training_args = TrainingArguments(
output_dir='./results', # output directory
num_train_epochs=5, # total number of training steps
per_device_train_batch_size=train_batch_size, # batch size per device during training
per_device_eval_batch_size=128, # batch size for evaluation
warmup_ratio=0.1, # number of warmup steps for learning rate scheduler
weight_decay=0.01, # strength of weight decay
logging_dir='./logs', # directory for storing logs
fp16=True,
gradient_checkpointing=True,
evaluation_strategy="steps",
eval_steps=total_num_steps//10,
load_best_model_at_end=True,
logging_steps=total_num_steps//10,
save_steps=total_num_steps//10,
use_cpu=False
)
Results
To summarize our results we’ll compute the average accuracy and macro-f1 scores across our 5 runs per dataset.
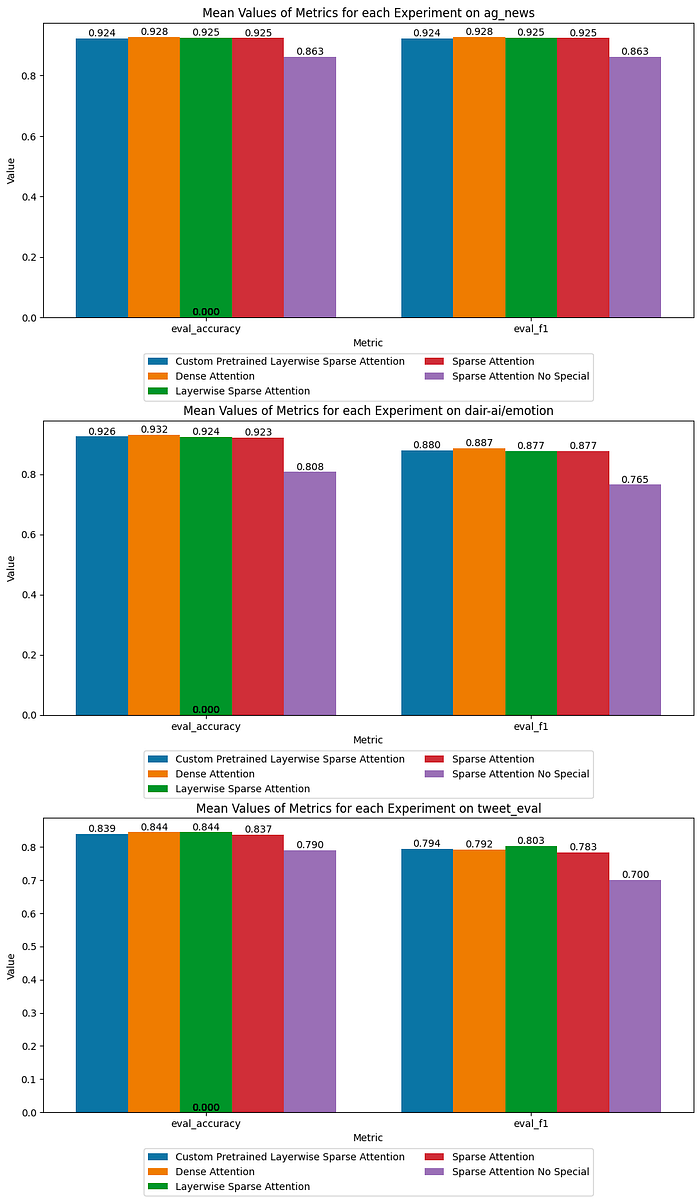
Key Takeaways
- We see that, in general, there’s very little between dense attention and sparse attention, where special tokens attend to all tokens. This leads us to the conclusion that sparse sliding window attention with a sliding window of just 5 tokens lets us perform nearly on par with dense attention.
- Allowing dense attention in the lowermost layers does slightly better (may not be significant) than all layers using sparse attention.
- Continued pre-training with our custom mask doesn’t provide any notable performance boost.
- We see a notable drop in performance across all datasets of 6,12, and 15 absolute percentage points when the special tokens are not allowed to attend to all tokens and all tokens are not allowed to attend to them. This highlights the importance of sink tokens, making it clear that they encode a lot of information.
Implications
These findings imply that we don’t need an O(N²) operation. Sparse sliding window attention reduces the time complexity to O(k*N) where k is the size of the sliding window.
In a world where we’re trying to eke out every ounce of computing to maximize the throughput and latency of LLMs, getting rid of a quadratic operation accompanied by a very negligible drop in performance, if any, shows lots of promise.
It also bodes as a good sign for new LLM/DL architectures like Mamba or StripedHyena that get rid of attention operations.
Another major implication is the need for more research into the nature of sink tokens to understand them much better and what is the determining factor for a token to become a sink token.
Appendix
As a sanity check, we plot the standard deviation of our metric values across runs to make sure that we don’t have any outliers that significantly affect the mean scores. As we see below there’s nothing crazy going on.

Future Work
Some of the next steps that can be taken to further this area of work are:
- Expand experiments to a decoder-only model perhaps an LLM like phi-2. We can compare the results of instruction tuning an LLM using dense vs sparse attention.
- More experiments, playing around with the value of k and with datasets with a larger average token count.
- Pre-training with sparse attention for more steps, in the grand scheme of LMs 500 steps is a pretty small number.
- Dig deeper into the importance of [CLS] vs [SEP] tokens as sink tokens.
- We didn’t focus much on the computational and run-time efficiency of sparse attention. This is because Pytorch isn’t very well equipped to handle sparse tensors. However, PyTorch did start some preliminary support of sparse tensors from v2.1. Once this feature is out of beta it might be worth comparing dense and sparse attention. Theoretically, sparse attention requires fewer flops and should be faster. However, other hardware dependencies with GPUs as well as current Cuda kernels could still be a hindering factor.
Thanks for reading our article, we hope that you’ve learned something new today. Until the next time, take care and be kind.
Please cite this article as:
Pramodith (2023, December 24). Comparing Dense Attention vs Sparse Sliding Window Attention Part 2: LLMs May Not Need Dense Self Attention
Medium. [https://pub.towardsai.net/comparing-dense-attention-vs-sparse-sliding-window-attention-6cd5b2e7420f]
Additional Reading
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")