


 LLMs + Knowledge Graph: Handling Large Documents and Data or any Industry — Advanced")
(New Approach🔥) LLMs + Knowledge Graph: Handling Large Documents and Data or any Industry — Advanced
Last Updated on January 10, 2024 by Editorial Team
Author(s): Vaibhawkhemka
Originally published on Towards AI.
(New ApproachU+1F525) LLMs + Knowledge Graph: Handling Large Documents and Data or any Industry — Advanced
Most of the real-world data replicates the Knowledge graph. In this messy world, one will hardly find linear data information. AI system needs to understand non-linear data structure like graphs, which depicts any human brain.
There are multiple cases where these knowledge graphs could be groundbreaking:
- Any Business Function — Most businesses have a hierarchical form of system and process in their functioning. One could leverage this to create a Knowledge Graph for each sub-group
- Data modeling — Data is normalized and stored in multiple dimensions and fact tables in a warehouse, which is nothing but a knowledge graph.

- All Social networking sites like Facebook, Instagram, etc. follow a Graph data structure to show connections and nearby contacts.
Why KGs are effective?
- Captures Non-Linearity
- There is a lot of context with relationships and dependencies
- Segmentation of data for granular and detailed level information.
But to use these LLMs, one needs to create a Knowledge Graph from your data and combine it with LLMs to extract output.
Knowledge Graph Creation:
Creating a Knowledge graph from your data varies with the domain. Many of these data are Texts, Folder with multiple files, Code Repository, etc.
I will show how to create a knowledge graph from a code repository which includes codebase modelling.
Codebase modeling is where you extract all the relationships between different files using functions imported from other files.
I have used ast library to extract imports from a file mentioned in the code below. Currently, it is limited to only Python files but can be extended to other languages, too.
with open(file_path, 'r', encoding='utf-8') as file:
tree = ast.parse(file.read(), filename=file_path)
imports = {}
for node in ast.walk(tree):
if isinstance(node, ast.Import):
for alias in node.names:
alias.name= add_prefix + alias.name + '.py'
if alias.name in filtered_files:
imports[alias.name] = None
elif isinstance(node, ast.ImportFrom):
if node.module is not None:
node.module= add_prefix + node.module + '.py'
imports[node.module] = [name.name for name in node.names]
return imports
There are multiple GraphDatabases and libraries to create a graph like Neo4js, Nebulagraph, and Networkx.
I have used Networkx to build and plot the graph using the code below.
for root, dirs, files in os.walk(folder_path):
for file in files:
head = file
for tail,functions in imports.items():
if functions is not None:
for relation in functions:
dfs.append(pd.DataFrame({'head': [head], 'relation': [relation], 'tail': [tail]}))
df = pd.concat(dfs, ignore_index=True)
for _, row in df.iterrows():
graph.add_edge(row['head'], row['tail'], label=row['relation'])
return graph
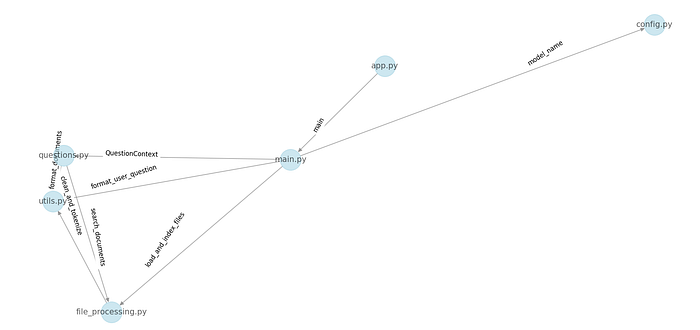
The above is the Knowledge Graph of the codebase where nodes are files and edge shows the functions which are imports done by other files showing inter-dependency and relationships between files.
Combining Knowledge Graphs with LLM:
Once the Knowledge graph is created, it’s time to combine it with LLMs to get results.
There are a few ways to do so:
- Langchain Graph Index and Graph Retrieval Method
You can use Langchain in-built Graph Index and Retrieval classes but they are not so good in capturing context either with texts as input or Repository. Retrieval is also bad which requires exact phrases in the prompt to find the relevant sub-graph and there is no room for tolerance for spelling or grammatical mistakes.
2. Flexible Knowledge Graph RAG (My own)

The above Knowledge Graph RAG pipeline is created by me, which is giving tremendous results capturing all context and scope of the query.
Knowledge Graph Retrieval
The knowledge graph created from the code repository is fed into LLM along with a prompt to produce a relevant sub-graph according to the prompt asked. This is a magical step since we are only capturing the file (“file_processing.py”) and its relations with other files, helping us to intelligently provide only sufficient information according to prompt.

What’s New?
- Most of the implemented methods search the whole graph by extracting the relevant words from the prompt and comparing them against the nodes to find a relevant sub-graph. But it has a lot of issues as it doesn’t cover up the tolerances in writing any prompts, which can include spelling mistakes, etc, and give bad results. This is the reason why we need a LLM layer to avoid these issues.
- Secondly, It extracts the full scope of the file, which helps us to find knowledge depth and the level we want our answers at. It can easily scope in and scope out to navigate across different sub-graphs
- Here comes the Mind-blowing revelation. We haven’t even given the content of code but only its dependencies and relations with one another, which will take very few token sizes even for huge code repositories while still giving major context to LLMs.
Final Blow
Now, With the relevant Sub-graph, we will access the code content only from relevant files present in the connections [utils.py, main.py, questions.py] and fed into LLM to produce output
Below is the output for the prompt:” What does file_processing.py do?”

The output is outstanding in many ways:
- It not only gives you what file_processing.py does but also provides information on its connections and relations with other files.
- It gives all the important functions in the scope of file_processing.py
- and the list goes on.
The above Knowledge graph RAG pipeline has two major USPs:
- Handling Large Scale Documents and Data
Problem:
LLMs have a major restriction on token size. The more the token size, the higher the cost. Thus, we resort to chunking and other similar methods, which have a major drawback of information loss due to the context of how each chunk is related to another.
So, only the top chunk is chosen according to similarity search, which might not contain the information you are looking for as it just matches the phrases present in prompts with chunks.
Idea:
But if we somehow create a Knowledge graph that captures the relationships between chunks, avoiding any information loss, we can easily deal with any large-scale documents and data.
- Capturing Scope of Query [System 2 thinking like agents]
It captures the scope and level of the query, making LLMs understand where to dig in and find answers. It depicts the system 2 thinking, which is how we humans think.
Future Extensions:
- Combining it with Normal RAG methods for improving the performance
- Use Map_Reduce approaches to summarize the documents combined with Knowledge Graph
- Build Agents on top of it to make it more autonomous.
- Generalize it to any Industry Scale documents or data.
Thank you for reading the blog.
If you want the full code of the above approach, find it here. I am happy to collaborate.
I implement and share many such Proof of Concepts and detailed analysis on my GenAI Weekly Blogs.
I will be working on these ideas in the future.
Stay Tuned!!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")