


Meet Fuyu-8B: The Very Unique Foundation Model Behind the Adept Platform
Last Updated on November 5, 2023 by Editorial Team
Author(s): Jesus Rodriguez
Originally published on Towards AI.
I recently started an AI-focused educational newsletter, that already has over 160,000 subscribers. TheSequence is a no-BS (meaning no hype, no news, etc) ML-oriented newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers, and concepts. Please give it a try by subscribing below:
TheSequence U+007C Jesus Rodriguez U+007C Substack
The best source to stay up-to-date with the developments in the machine learning, artificial intelligence, and data…
thesequence.substack.com
Adept.ai is part of the generation of newly minted AI unicorns. Initially incubated by some of the authors of the iconic transformers paper, Adept is working in the area of autonomous AI agents. To date, Adept has raised over $415 million at a valuation exceeding $1 billion. The platform is dedicated to constructing agents that comprehend high-level objectives and convert them into actions, relying primarily on computer vision and language. Very little was known about the models behind Adept until now when Adept open sourced Fuyu-8B, a smaller version of the model powering its platform.
Adept is on a mission to create a smart companion for knowledge workers, a digital copilot with a wide-ranging intellect. To achieve this goal, Adept places a strong emphasis on grasping user context and taking actions on their behalf. A crucial part of this endeavor involves adept image comprehension. In the world of knowledge work, users anticipate their copilot to seamlessly access what’s visible on their screens. Often, vital information is conveyed through images, be it charts, slides, or PDFs. Furthermore, executing actions often necessitates interacting with on-screen elements like buttons and menus. While it would be ideal if all these tasks could be accomplished via APIs, many business-oriented software lacks comprehensive APIs, making it necessary to navigate these applications through their graphical user interfaces (UIs) to keep users engaged.
In general, Fuyu-8B exhibits some characteristics that makes it unique among the new generation of multimodal models:
1. Smaller and simpler than standard architecture.
2. Designed for the agent paradigm.
3. Fast.
4. Able to match with larger models across standard benchmark while surpassing them in agent-specific tasks.
The Architecture
When comes to the latest generation of foundation models, multimodal models share a common structure. They typically feature a distinct image encoder, the output of which is integrated into an existing Large Language Model (LLM) through cross-attention mechanisms or adapters. The examples are everywhere. Models such as PALM-e, PALI-X, QWEN-VL, LLaVA 1.5, and Flamingo adhere to this paradigm. These models typically operate at fixed image resolutions. During inference, images exceeding this resolution must be downsized, while those with differing aspect ratios require padding or distortion.
On the training front, many other multimodal models undergo a multi-step training process. The image encoder is trained separately from the LLM, often using contrastive training objectives, which can be intricate to implement and manage. Decisions must be made about when to freeze the weights of various components. Some models even include an additional high-resolution image phase to ensure competent handling of high-res images.
Scaling these models presents a challenge when determining how to proportionately scale each of these components. Questions arise about how to allocate additional parameters to the encoder versus the decoder and where to allocate computational resources during training. Adept, however, presents a model that sidesteps these complexities.
Architecturally, Fuyu is a straightforward, decoder-only transformer with the same specifications as Persimmon-8B, devoid of a dedicated image encoder. Image patches are directly projected into the transformer’s first layer, bypassing the embedding lookup. This approach treats the traditional transformer decoder as an image transformer, albeit without pooling and with causal attention. For more details, refer to the accompanying diagram.
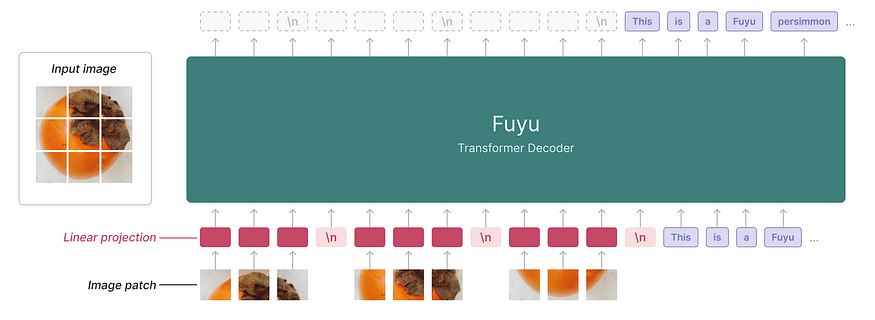
This simplification offers the flexibility to handle images of varying resolutions effortlessly. To achieve this, image tokens are treated much like their textual counterparts. Image-specific position embeddings are removed, and image tokens are fed into the model in raster-scan order, with a special image-newline character indicating line breaks. The model can leverage its existing position embeddings to adapt to different image sizes. During training, images of any size can be used, obviating the need for separate high and low-resolution training stages.
The Capabilities
In addition to the standard features expected in multimodal foundation models, Fuyu-8B exhibits an interesting set of unique capabilities:
QA in Images
Fuyu exhibits the ability to tackle intricate questions within images, as demonstrated below:

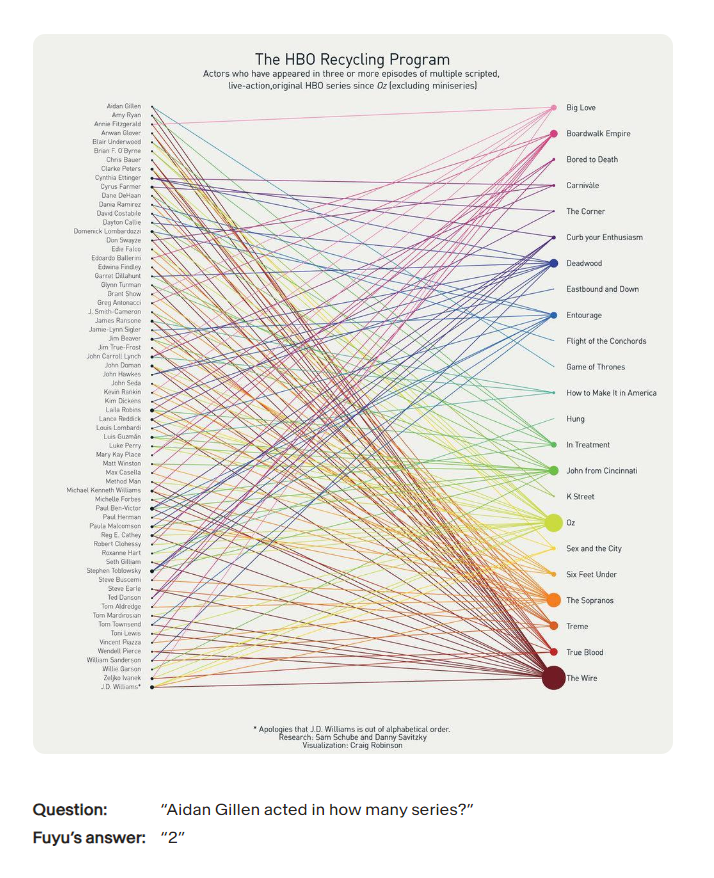
Chart Comprehension
When faced with complex visual data, such as the chart depicted below, Fuyu excels at discerning intricate relationships, tracing connections between various elements, and counting to provide insightful answers:
Document Mastery
Fuyu’s competence extends to deciphering a wide range of documents, whether they involve intricate infographics or aging PDFs:

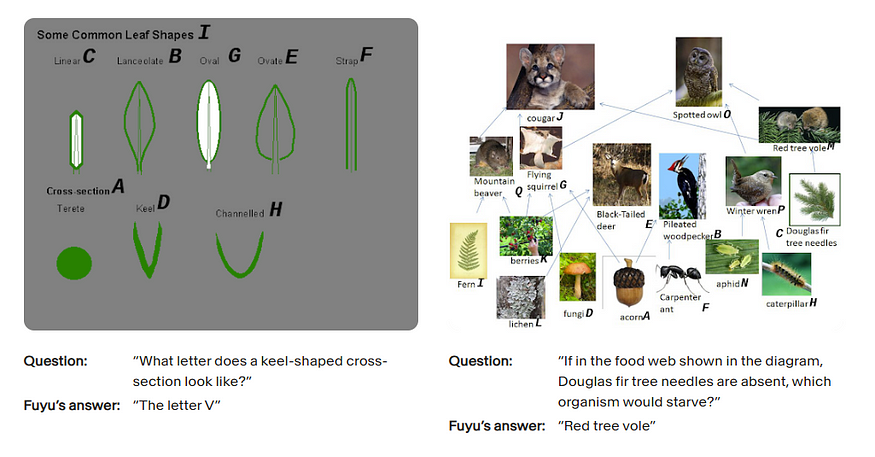
Diagram Interpretation
The model’s expertise also extends to deciphering complex scientific diagrams, addressing intricate relational queries with finesse:
OCR Proficiency
In addition to these skills, Adept has honed its internal models to excel in two essential tasks when presented with an image of a user interface (UI):
· bbox_to_text: Given a bounding box, Adept can precisely identify the text contained within that bounding box.
· text_to_bbox: Conversely, when provided with text, Adept can skillfully return the bounding box that encompasses the specified text.
Fuyu-8B is certainly one of the most interesting recent releases in open source foundation models. The simplicity of its architecture and the unique set of capabilities makes it one of the models to track in the space.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")