



Getting Started with OpenAI: The Lingua Franca of AI
Author(s): Abhinav Kimothi
Originally published on Towards AI.
30th November, 2022 will be remembered as the watershed moment in artificial intelligence. OpenAI released ChatGPT and the world was mesmerised. Interest in previously obscure terms like Generative AI and Large Language Models (LLMs), was unstoppable over the following 15 months. However, for developers, LLMs have been accessible for longer than that.
OpenAI has been at the forefront of developing Large Language Models and making them accessible to the developer community. With the release of GPT-3 in May of 2020 and the subsequent improvements in the following months, a whole new set of applications came to the forefront.
I started building Yarnit in the middle of 2022 using the ‘davinci’ variant of GPT3. Ever since then, accessing OpenAI LLMs has become simpler and easier. In this blog, I’ll provide a step-by-step guide for any developer trying to get hand-on with GPT3.5/GPT4 to generate text for their applications.
Yarnit U+007C Generative AI platform for personalized content creation
Discover the power of Yarnit.app, the generative AI driven digital content creation platform. Seamlessly ideate, write…
www.yarnit.app
We’ll look at —
- Installing the OpenAI Python library
- Creating an OpenAI account and Getting an API key
- Initialising OpenAI Client
- Making the first API Call
- Getting an Introduction to Large Language Models
- Understanding the available OpenAI LLMs
- Looking at the OpenAI Chat Messages (Prompt) Structure
- Study the Chat Completions API Parameters
- Decoding the Chat Completions Response Object
- Learning how to Stream responses
- Looking at JSON Response Format
- Learning about managing Tokens
So let’s get started
Installing the OpenAI python library
The first step is to install the openai library.
pip install openai --quiet
###You can remove '--quiet' to see the installation steps
Creating an OpenAI account and Getting an API key
You’ll also need an API key to make calls to the models. You’ll need to visit www.openai.com and follow the following steps

- Remember to copy and save your API key. You will not be able to see the key afterwords in your OpenAI account
- You may get some credits on your first sign-up. If you run out of credits, you will have to set billing and purchase more credits
Initialising OpenAI Client
OpenAI client serves as an interface to interact with OpenAI’s services and APIs. To initialize the OpenAI client, we need to pass the API key. There are many ways of doing it. To do this, you’ll need to import the libraries.
import openai #OpenAI python library
from openai import OpenAI #OpenAI Client
Option 1 : Creating a .env file for storing the API key and using it (Recommended)
Install the dotenv library
The dotenv library is a popular tool used in various programming languages, including Python and Node.js, to manage environment variables in development and deployment environments. It allows developers to load environment variables from a .env file into their application’s environment.
pip install python-dotenv
Then, create a file named .env in the root directory of their project. Inside the .env file, then define environment variables in the format VARIABLE_NAME=value. e.g. OPENAI_API_KEY=YOUR API KEY
from dotenv import load_dotenv
import os
load_dotenv()
openai_api_key=os.getenv("OPENAI_API_KEY")
The variable ‘openai_api_key’ now stores your API key
Option 2: Pasting the key within code (Not Recommended)
openai_api_key="<YOUR KEY HERE>"
You can also visit https://platform.openai.com/docs/quickstart?context=python for more options
A simple initialization of the client then follows
client = OpenAI(api_key=openai_api_key)
We will use this client to make all API calls
Making the first API Call
Now let’s test the API. We’ll call the Chat Completions API
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "Hello!"}
],
)
print(response.choices[0].message.content)
If you get a response like —
Hello! How can I assist you today?
— that means the API is working fine. Congratulations! You’re all set!
You may also get certain errors like (401 — Invalid Authentication, 401 — Incorrect API key provided, etc.) if there are issues with your account or with OpenAI servers
Checkout this page for error codes and how to address them — https://platform.openai.com/docs/guides/error-codes/api-errors
Brief Introduction to Large Language Models
This is also a good time to understand a few basics of large language models. Generative AI, and LLMs specifically, is a General Purpose Technology that is useful for a variety of applications
LLMs can be, generally, thought of as a next word prediction model
What is an LLM?
- LLMs are machine learning models that have learned from massive datasets of human-generated content, finding statistical patterns to replicate human-like abilities.
- Foundation models, also known as base models, have been trained on trillions of words for weeks or months using extensive computing power. These models have billions of parameters, which represent their memory and enable sophisticated tasks.
- Interacting with LLMs differs from traditional programming paradigms. Instead of formalized code syntax, you provide natural language prompts to the models.
- When you pass a prompt to the model, it predicts the next words and generates a completion. This process is known as inference.

Recommendation : An excellent course “Generative AI using Large Language Models" is offered by DeepLearning.ai and AWS via Coursera.
I’ve prepared notes on this course that you can download.
Generative AI with Large Language Models (Coursera Course Notes)
Generative AI with Large Language ModelsThe arrival of the transformers architecture in 2017, following the publication…
abhinavkimothi.gumroad.com
Available OpenAI LLMs
Over the course of time, OpenAI has developed, released and improved several models. Details around all the current and legacy models can be viewed here — https://platform.openai.com/docs/models
GPT 4 and GPT 3.5 models are the most popular and most advanced LLMs offered by OpenAI
GPT 4
- gpt-4 with a context window of 8,192 tokens has knowledge up to Sep 2021
- gpt-4–32k with a context window 32,768 tokens has knowledge up to Sep 2021
Apart from these, OpenAI has also released preview versions of the more advanced GPT4 series of models
- gpt-4-turbo-preview has a context window of 128,000 tokens and has knowledge up to Dec 2023
- gpt-4-vision-preview is a multi-modal model that works on both text and images. It has a context window of 128,000 tokens and has knowledge up to Apr 2023
GPT 3.5
GPT 3.5 series is still used in the free version of ChatGPT
- gpt-3.5-turbo with a context window of 16,385 tokens has knowledge Up to Sep 2021
- gpt-3.5-turbo-instruct with a context window of 4,096 tokens has knowledge Up to Sep 2021
Note : ”model” is passed as a required parameter in the chat completions API
OpenAI Chat Messages (Prompt) Structure
Messages are passed to the models in the form of a dictionary with keys “role” and “content”. Recall that when we tested the API above and made our first call, the message parameter was passed as a dictionary with the role of “user” and the content as hello.
messages=[
{"role": "user", "content": "Hello!"}
]
OpenAI allows for three roles/personas –
- System : The overarching constraints/definitions/intructions of the system that the LLM should “remember”
- User : Any instruction a user wants to pass to the LLM
- Assistant : The response from the LLM
Any message or “prompt” of these personas are passed as “Content”
Why is this important? : Makes it easier to adapt an LLM to store conversation history.
Note : ”role” and ”content” are passed as a dictionary in the ”messages” parameter in the chat completions API
Now let’s call the Chat Completions API.
Let’s talk to the LLM about the beautiful game of Cricket.
Remember “System” is the overarching instruction that you can give to the LLM. Here let’s ask the LLM to be a helpful assistant who has a knowledge of cricket.
Then will ask it a question about cricket.
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant knowledgeable in the field of Cricket."}, ### The overarching instruction
{"role": "user", "content": "When did Australia win their first Cricket World Cup?"} ### Our Question
]
)
Note that we used the gpt-3.5-turbo model. This is the same model used in the free version of ChatGPT.
Let’s look at the response that the LLM generated. We’ll look at the response object later in detail. The response text is found under choices->message->content in the response object
print(response.choices[0].message.content)
Australia won their first Cricket World Cup in the year 1987.
They defeated England in the final to clinch their maiden title.
Great! We got a response from the LLM. The response also seems fairly accurate. Remember that there is no guarantee that the response will be factually correct.
Now, let’s ask a follow-up question — “How much did they score?”
This question implies that we are chatting with the LLM and the LLM has the context of the previously asked questions and responses. To the API we will have to pass all of the previous prompts and responses.
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant knowledgeable \
in the field of Cricket."}, ### The overarching instruction
{"role": "user", "content": "When did Australia win their first Cricket \
World Cup?"}, ### Our Question
{"role": "assistant", "content": "Australia won their first
Cricket World Cup in the year 1987. They defeated England in the final
to clinch their maiden title in the tournament."}, ### LLM Response
{"role": "user", "content": "How much did \
they score?"} ### Our followup question
]
)
In the final of the 1987 Cricket World Cup, Australia scored 253
runs for the loss of 5 wickets in their 50 overs. England, in
response, were bowled out for 246 runs, resulting in Australia
winning by 7 runs and claiming their first World Cup title.
Great, we can see that the model considers all the previous context while answering the latest question.
Chat Completion API Parameters
Now that we understand how prompts and responses work, let’s deep dive into the API parameters.
”model” and ”messages” , as we saw above, are the two required API parameters
There are several other optional parameters that help configure the response.
- n: Number of responses you want the LLM to generate for the instruction
- max_tokens : Maximum number of tokens you want to restrict the Inference to (This includes both the prompt/messages and the completion)
- temperature : Temperature controls the “randomness” of the responses. Higher value increases the randomness; lower value makes the output deterministic (value between 0 and 2)
- top_p : The model considers the results of the tokens with top_p probability mass (value between 0 and 1)

Note : It is recommended to configure either one of “temperature” and “top_p” but not both
- frequency_penalty: Penalize new tokens based on their existing frequency in the text so far (Value between -2 and 2)
- presence_penalty: Penalize new tokens based on whether they appear in the text so far (Value between -2 and 2)
- log probs: Flag to return log probability of the generated tokens (True/False)
- logit_bias: Parameter to control the presence of particular tokens in the output (Value between -100 and 100)
- response_format: Response of the model can be requested in a particular format (Currently : JSON and Text)
- seed: Beta feature for reproducible outputs (setting a seed value may produce the same output repeatedly)
- stop: End of Sequence tokens that will stop the generation
- stream: To receive partial message deltas (True/False)
- user: ID representing end user (This helps OpenAI detect abuse. May be mandatory for higher rate limits)
- tools: used in function calling
- tool_choice: used in function calling
Let’s create a function to make the API calls.
def gpt_call(model:str="gpt-3.5-turbo",prompt:str="Have \
I provided any input",n:int=1,max_tokens:int=100,
temperature:float=0.5,presence_penalty:float=0):
response = client.chat.completions.create(
model=model,
messages=[
{"role": "user", "content": prompt}
],
max_tokens=max_tokens,
temperature=temperature,
presence_penalty=presence_penalty,
n=n
)
if len(response.choices)>1:
output=''
for i in range(0,len(response.choices)):
output+='\n\n-- n = '+str(i+1)+' ------\n\n'+
str(response.choices[i].message.content)
else:
output=response.choices[0].message.content
return output
First, let’s call the function with n=2 and a high temperature
print(gpt_call(prompt="Write a title for a workshop on /
openai API",n=2,temperature=1))
You’ll get two responses because ’n’ is set to 2
-- n = 1 ------
"Unlocking the Power of AI: A Deep Dive into OpenAI's API"
-- n = 2 ------
"Unlocking the Power of OpenAI: A Workshop on Leveraging the OpenAI
API for Innovation and Insight"
Now, let’s change the temperature to 0 (a more deterministic result)
print(gpt_call(prompt="Write a title for a workshop /
on openai API",n=3,temperature=0))
You’ll notice that the response for all three options is the same.
-- n = 1 ------
"Unlocking the Power of AI: A Deep Dive into OpenAI's API"
-- n = 2 ------
"Unlocking the Power of AI: A Deep Dive into OpenAI's API"
-- n = 3 ------
"Unlocking the Power of AI: A Deep Dive into OpenAI's API"
This is because the probability distribution of the tokens when the temperature is low is strongly peaked
You can try with different parameters to see the kind of responses you achieve.
Decoding the Chat Completions Response Object
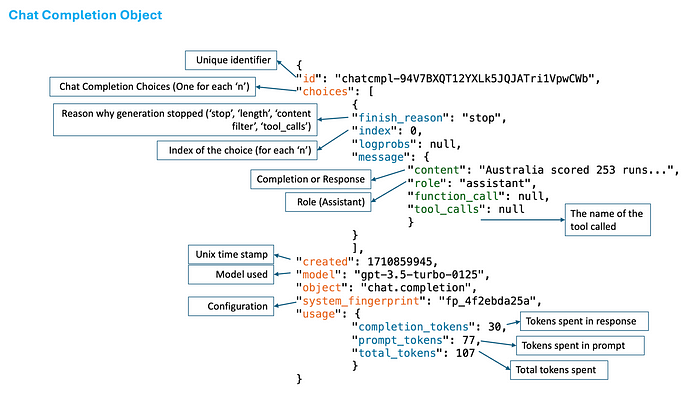
You may have noticed that we used “response.choices[0].message.content” to obtain the generated text. The response object, however, has much more information. Let’s take a look at the entire response object first.
{
"id": "chatcmpl-99vyDS2agqm7zz8ZB3WJ960QWPp9B",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"message": {
"content": "In the final of the 1987 Cricket World Cup,
Australia scored 253/5 in their 50 overs.
This formidable total proved to be too much
for England, who managed to score 246/8 in
their allotted overs, resulting in
Australia winning the match by 7 runs.",
"role": "assistant",
"function_call": null,
"tool_calls": null
}
}
],
"created": 1712154817,
"model": "gpt-3.5-turbo-0125",
"object": "chat.completion",
"system_fingerprint": "fp_b28b39ffa8",
"usage": {
"completion_tokens": 59,
"prompt_tokens": 77,
"total_tokens": 136
}
}
There are several other keys and values in the response object. The meaning of each of them is in the image below.
Streaming Responses
Sometimes when the model is expected to generate a large piece of text like an email or a story or a blog, etc., it takes a significant amount of time. This may lead to bad user experience. To address this issue, OpenAI API provides the ability to stream responses back to a client in order to allow partial results for certain requests. This is done by setting the “stream” parameter as True.
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant knowledgeable in the field of Cricket."},
{"role": "user", "content": "When did Australia win their first Cricket World Cup?"},
{"role": "assistant", "content": "Australia won their first Cricket World Cup in the year 1987. They defeated England in the final to clinch their maiden title in the tournament."},
{"role": "user", "content": "How much did they score?"}
],
stream=True ###Streaming is set to true here.
)
The response is received in chunks which can be printed as and when they arrive.
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
JSON response format
Sometimes responses are needed in a set format for us to retrieve relevant sections from them. JSON becomes a very handy format and LLMs have the ability to return text in JSON format. In the previous versions of GPT series of models, sometimes the JSON returned was not valid. Therefore, OpenAI recently released this functionality. To avail this, the “response_format” parameter is used.
prompt="generate the entire text for a blog
on a cricket match. \"Title\" is a catchy and attractive
title of the blog. The \"Heading\" is the heading for each point
in the blog and the \"Body\" is the text for that heading.Output
in a json structure"
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": prompt}
],
response_format={ "type": "json_object" }
)
print((response.choices[0].message.content))
The response can now be expected in a valid JSON format.
{
"Title": "Thrilling Victory: A Nail-biting Finish in the Cricket Match",
"Heading": [
{
"Heading": "Introduction",
"Body": "The cricket match between Team A and Team B had fans on the edge of their seats as both teams fought tooth and nail for victory. The match was filled with twists and turns, keeping the spectators entertained till the last ball."
},
{
"Heading": "Team A's Dominant Start",
"Body": "Team A got off to a flying start with their opening batsmen scoring quick runs and building a solid foundation for the team. Their middle-order batsmen continued the momentum, and Team A set a formidable total for Team B to chase."
},
{
"Heading": "Team B's Counterattack",
"Body": "Despite the daunting target set by Team A, Team B's batsmen showed great determination and skill as they went about their chase. They played aggressive cricket, hitting boundaries and rotating the strike to keep the scoreboard ticking."
},
{
"Heading": "The Rollercoaster Middle Overs",
"Body": "The middle overs of the match were filled with drama as both teams fought fiercely for control. Team A's bowlers made crucial breakthroughs, but Team B's batsmen didn't back down, staging counterattacks and keeping the match finely balanced."
},
{
"Heading": "The Final Overs Drama",
"Body": "As the match entered its final overs, the tension was palpable in the air. Team B needed a few runs to win, but Team A's bowlers didn't make it easy for them. It all came down to the last ball, with the match hanging in the balance."
},
{
"Heading": "The Last Ball Finish",
"Body": "In a nail-biting finish, Team B managed to score the required runs off the last ball, clinching a thrilling victory against Team A. The players and fans erupted in joy as Team B celebrated their hard-fought win."
},
{
"Heading": "Conclusion",
"Body": "The cricket match between Team A and Team B was a test of skill, determination, and nerve. Both teams showcased their fighting spirit and never-say-die attitude, making it a memorable match for everyone involved."
}
]
}
This becomes very handy when building applications. There are a few points to note here —
- This is still a beta feature.
- To use the JSON mode, instruction to the model to produce JSON needs to be present in the prompt/message, otherwise an error occurs.
Tokens
Before we wrap up, a word on tokens is necessary. Tokens are the fundamental units of NLP. These units are typically words, punctuation marks, or other meaningful substrings that make up the text
Counting the number of tokens becomes important because –
- The number of Tokens determine the amount of computation required and hence the cost you incur both in terms of money and latency
- Context Window or the maximum number of tokens an LLM can process in one go is limited
To count the number of tokens, a library called tiktoken is recommended by OpenAI.
pip install tiktoken --quiet
import tiktoken
def num_tokens_from_string(string: str, encoding_name="cl100k_base") -> int:
encoding = tiktoken.get_encoding(encoding_name) #### Initialize encoding ####
return len(encoding.encode(string)) #### Return number of tokens in the text string ###
Now let’s try counting tokens
num_tokens_from_string("Hello! how are you?")
6
A sentence, “Hello! how are you?” has 6 tokens i.e. ‘Hello’, ‘!’, ‘how’, ‘are’, ‘you’, ‘?’
If you were to look at a story like Alice In Wonderland, it would have more than 38,000 tokens.
Pricing of OpenAI models is token based
- For gpt-3.5-turbo OpenAI will charge 50 cents per million tokens in prompt and 150 cents per million tokens in response
- For gpt-4 the charges are $30 per million tokens in prompt and $60 per million tokens in response
- For gpt-4-turbo the charges are $10 per million tokens in prompt and $30 per million tokens in response
gpt-4 is aroud 60X — 45X pricier than gpt-3.5-turbo
It, therefore, becomes important that you assess beforehand how many tokens your application is built to process.
Working with OpenAI’s language models like GPT-3.5 and GPT-4 opens up a world of possibilities for developers. However, getting started can seem daunting with APIs, tokens, model configurations, and pricing considerations. I hope this blog helped in demystifying the process to an extent.
The possibilities are endless when you can interface with a model imbued with broad knowledge that can articulate responses like a human. The future of software development is here, and it’s generative.

I write about #AI #MachineLearning #DataScience #GenerativeAI #Analytics #LLMs #Technology #RAG.
If you’re interested in this space, please read my e-books.
Retrieval Augmented Generation – A Simple Introduction
How to make a ChatGPT or a Bard for your own dataU+2753 The answer is in creating an organisation "knowledge brain" and use…
abhinavkimothi.gumroad.com
Generative AI Terminology – An evolving taxonomy to get you started with Generative Artificial…
In the realm of Generative AI, newcomers may find themselves daunted by the technical terminology. To alleviate this…
abhinavkimothi.gumroad.com
Generative AI with Large Language Models (Coursera Course Notes)
Generative AI with Large Language ModelsThe arrival of the transformers architecture in 2017, following the publication…
abhinavkimothi.gumroad.com
Let’s connect on LinkedIn -> https://www.linkedin.com/in/abhinav-kimothi/
If you’d like to talk to me, please feel free to book a slot -> https://topmate.io/abhinav_kimothi
Please read my other blogs on Medium
Progression of Retrieval Augmented Generation (RAG) Systems
The advancements in the LLM space have been mind-boggling. However, when it comes to using LLMs in real scenarios, we…
pub.towardsai.net
Generative AI Terminology — An evolving taxonomy to get you started
Being new to the world of Generative AI, one can feel a little overwhelmed by the jargon. I’ve been asked many times…
pub.towardsai.net
Getting the Most from LLMs: Building a Knowledge Brain for Retrieval Augmented Generation
The advancements in the LLM space have been mind-boggling. However, when it comes to using LLMs in real scenarios, we…
medium.com
Gradient Descent and the Melody of Optimization Algorithms
If you work in the field of artificial intelligence, Gradient Descent is one of the first terms you’ll hear. It is the…
pub.towardsai.net

Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")