



Result
Last Updated on July 26, 2023 by Editorial Team
Author(s): Low Wei Hong
Originally published on Towards AI.
Web Scraping
Why you should use WebSocket to retrieve live crypto data
Life-saving hack in getting ever-changing data!
One of the greatest ways to automate the process of retrieving data from a website is to build a web crawler to handle the work. You can create a web crawler that scrapes data in a variety of methods. For example, if you want to retrieve data from a website once every few hours or once a week, you may write a program that could automatically send the HTTP request or open a browser to do so as it is less frequent. However, if you are thinking of crawling data within seconds, it is still best to connect through a web socket.
Before going through the practical part of coding a web scraper, let us briefly goes through what it is and normally when you are going to use it.
Let me put this in a real-life context…
One day, you told your friend that you will be calling her to discuss a concept that you do not understand. So, when you were calling your friend (handshake), your friend would check who is calling and then decide whether to receive the call (verify). After your friend completed the verification and picked up your call, he will be explaining the concept and keep the line open for your incoming queries (Data streaming from the server).

Normally, you should be thinking of using a web socket to retrieve data in cryptocurrencies, live stock price, live betting, live messaging, trading platform, and many more.
After knowing the concepts, let’s picture a real scenario and work from there. For instance, if you would want to build a live trading bot to trade cryptocurrencies, and you already have a set of rules ready to beat the market.
What’s next?
You will need to get a website that you can retrieve live data. You come across some APIs but are afraid that those API will fail which might eventually lead to losing money. Thus, you decide to find a website that provides live crypto prices. Let’s pick Cryptocompare (a global cryptocurrency market data provider) for illustration purposes.
Exploration
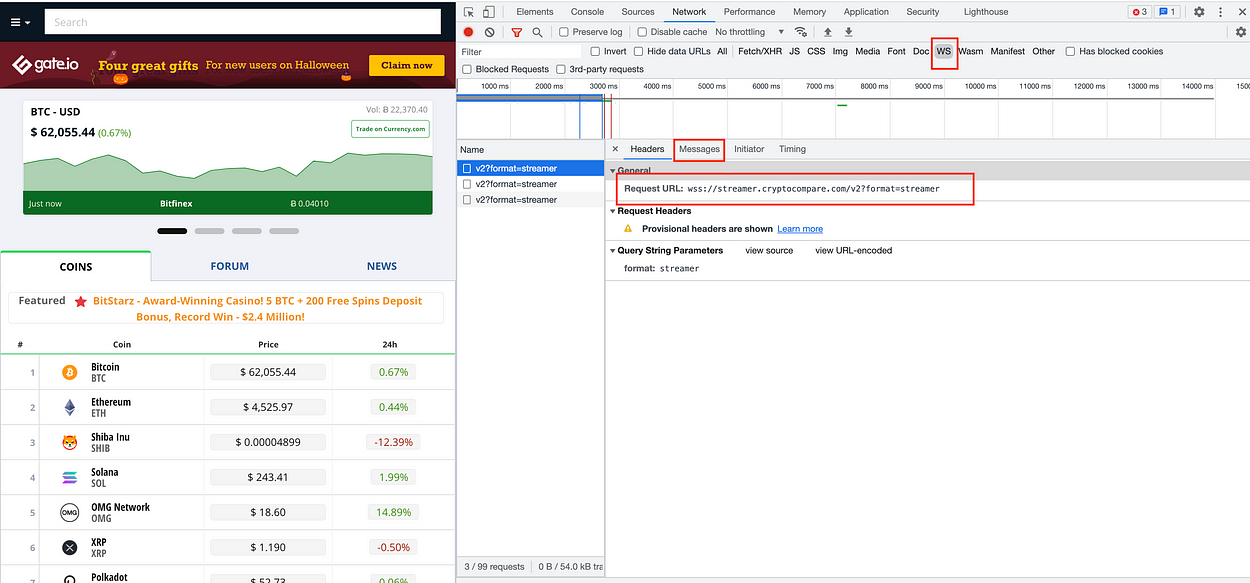
When you navigate to this website using chrome, right-click, and click on inspect, then click on the WS tab. You should be able to see a similar view as the screenshot above now. You will notice the request url for this web socket is wss://streamer.cryptocompare.com/v2?format=streamer .
Next, let’s navigate to the message tab to get the message needed to send to the server in order to complete the verification.

Now, you will see there are two types of arrows –
- The messages following the green color arrows indicate the outgoing messages that your browser is sending to the server.
- The messages after the red color arrows are the incoming data received by your browser from the server.
Till now you just need to copy down the green arrow’s message by right-clicking the message and selecting “copy message”. You would need these 5 green arrow messages in the coding part.
Coding
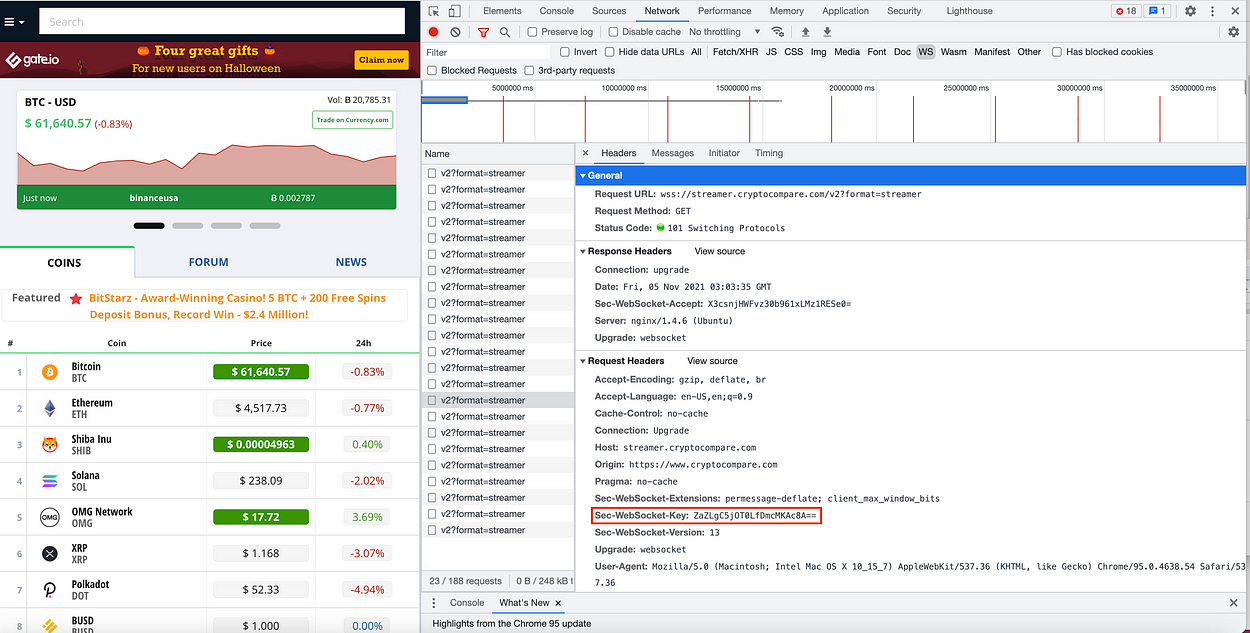
I have attached a code snippet for you to try on. Something that you would need to pay attention to is to change the WebSocket key (“Sec-WebSocket-Key”) to the key that you can get from your browser under the “Headers” tab. Example below:
Here is a summary of what does the code snippet above does:
- Create a connection with the request url
2. Send the 5 outgoing messages to the server
3. Sit down and relax to wait for the incoming messages, normally is within seconds.
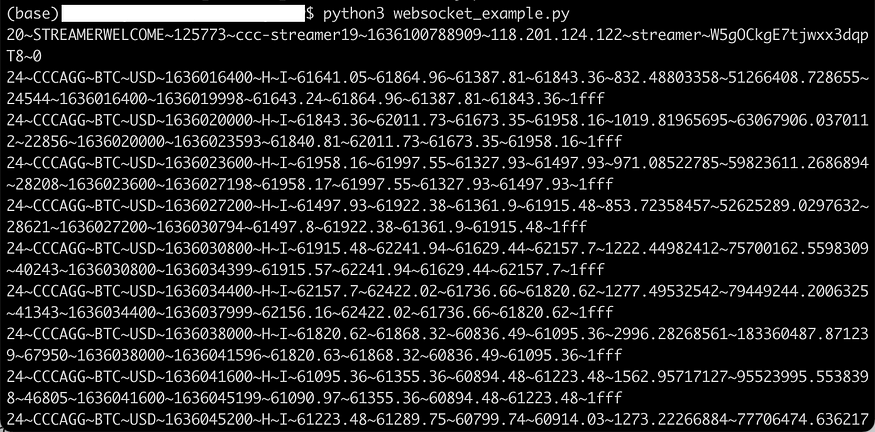
Save the code snippet to a python file and run it. You should see similar output.
Problems You Might Face
Here are some of the problems you might face and how you can solve it.
- Error Message: Connection is already closed
If you see this message, normally what it means is that the server is trying to stop you from connecting and the fastest way to solve it, is to change your proxies or VPN.
2. HTTP Status Code: 401 (Unauthorized)
A 401 response means that the server does not accept your connection request. If the server is working properly, then there is a problem with your connection request. In short, normally it means you are using the wrong credentials. To solve it, check the request headers and modify them accordingly.
3. HTTP Status Code: 403 (Forbidden)
Similar to 401, but in this case, re-authenticating will make no difference. This might mean that the original application logic change for instance the handshake process has changed. Thus, to make sure it runs smoothly, check your request headers and the messages that you need to send to the server.
Final Thought

This article is written as the previous old snippet code is not working. Thus I combine all the errors and questions that my readers raised and answer them accordingly.
If you find this code not working in the future, feel free to comment down below and I will answer them accordingly.
Thank you for reading until the end. See you in the next post!
About the Author
Low Wei Hong – Medium
Using data to make an informed decision Airbnb has grown 21% compared to August 2019 earning gross revenue…
medium.com
Low Wei Hong is a Data Scientist at Shopee. His experiences involved more in crawling websites, creating data pipelines,s and also implementing machine learning models on solving business problems.
He provides crawling services that can provide you with the accurate and cleaned data which you need. You can visit this website to view his portfolio and also to contact him for crawling services.
You can connect with him on LinkedIn and Medium.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

