



AI in Medicine
Last Updated on July 26, 2023 by Editorial Team
Author(s): Dhruv Gangwani
Originally published on Towards AI.
Artificial Intelligence
Automating medical tests using Artificial Intelligence
Artificial Intelligence, in recent years, has automated several processes in almost every domain all over the globe. Specifically, AI has embraced Medical science in recent times when the world was struck with the COVID pandemic. From predicting the virus’s spread to examing the chest and lung’s X-ray, AI helped the human race in every possible manner.
But, Medical Science is still considered the most sensitive domain when it comes to relying on AI and Data Science. The reasons are pretty much straightforward: a small mistake by AI can cost a life.
Two major scenarios can occur:
- The patient is diagnosed with the disease and he/she is not affected.
- The patient is not diagnosed with the disease and he/she is affected.
Both scenarios will result in big disasters. One solution to the issue is that AI models must be fed with large volumes of quality data that covers all the unique test scenarios and exceptions as well. Secondly, we should let AI come to play but not at the risk of cutting down human involvement. This is to monitor and observe the nature of AI functioning and tune it accordingly. Once, AI models reach a stage where they are considered fully reliable then they should be tested on real patients. Mostly, industry-level practitioners don’t believe in relying on the accuracy of AI models in such sensitive scenarios. Rather, they trust metrics such as recall, precision, and F1 score.
This blog will depict the end-to-end process of building a web app that accepts skin images as input and detects skin disease followed by sending medical reports to patients and doctors through WhatsApp messenger.
Table of Content:
- Data Source
- Exploratory Data Analysis
- Model Training
- Whatsapp Configuration
- Creating Web App
- Conclusion
Data Source
The dataset used for the training model is Skin Cancer MNIST: HAM10000. It comprises 10015 images over 7 classes of cancer. More than 50% of lesions are confirmed through histopathology and the ground truth for the rest of the cases is either follow-up examination (followup), expert consensus (consensus), or confirmation by in-vivo confocal microscopy (confocal). One issue with the dataset is that it does not have a class “No disease” which is necessary for our application. I have opted for another way to deal with such a scenario which you’ll find in the next sections.
Exploratory Data Analysis
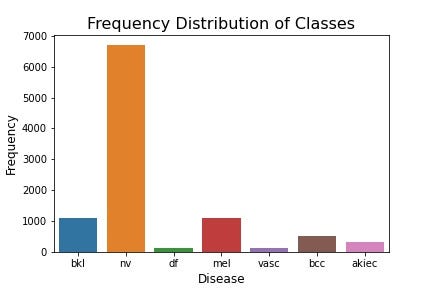
- Frequency of Classes
It is very evident that the dataset is highly imbalanced where the frequency of melanocytic nevi (nv) is roughly seventy times the class with minimum frequency (melanoma). This brings the need of balancing the dataset by oversampling the ones except for the class with maximum frequency.
2. Distribution of Skin disease over Gender
The pie chart depicts that the probability of disease is gender-neutral. There are some specific kinds of cancer that are more likely to happen to a specific gender but not in this case. Further analysis might include gender distribution for an individual classes of cancer.

3. Histogram of the age of patients
Using the seaborn’s histplot to plot the histogram of patient’s age. This will disclose the group of age which is most affected. It is clear from the plot that people aged 40 to 60 are most affected by cancer.

4. Location of disease over Gender
This plot will depict the body parts which are most frequently affected by these types of cancer for all genders. It is clear that “back” is the most affected for males and “lower extremity” for females.

Model Training
Before the model is trained, we need to fix imbalanced data. I have used oversampling technique which creates duplicates of the data points who belong to the minority class (except for the class with the highest frequency).
Also, make sure to oversample the dataset (training dataset) after splitting the dataset into train and test. During splitting the dataset, training is allocated 90% of data while the rest is kept for testing the model once it is trained on the training dataset. Oversampling is performed only on the training dataset.
The model architecture can be developed using two techniques: Custom architecture and Finetuning the pre-trained model. Some of the famous pre-trained models are VGG-16, Resnet50 and InceptionV3. While using the pre-trained model, the few last layers are altered to make it adaptable according to the current dataset. In this project, I have created a custom architecture that comprises several stacks of convolutional layer, max-pooling layer, and dense layer. Each layer performs a specific role in extracting features from images.
Convolutional Layer: It applies a kernel over an image to extract features such as vertical lines, horizontal lines, etc. The kernel can be imagined as a window of size K x K where K is usually an odd integer. It moves over an image with stride S and padding P can be laid at the boundary of the image to extract important features at the boundaries of the image. The output of the convolutional layer on Image I can be computed as :
Output size = (I-K+2P)/S+1
Max Pooling Layer: It moves a kernel over an image to extract the feature with the max value. For example, the kernel of size 3*3 will cover nine pixels. It pixel with maximum value will be considered.
Dense Layer: Dense Layer is a simple layer of neurons in which each neuron receives input from all the neurons of the previous layer. It is the same as one used in Artificial neural networks. This layer is used for classification.
Though I have created a custom architecture, I believe that in most cases pre-trained models outperform the custom architectures. Additional details of model performance are provided in the Github repository mentioned at the end of this article.
Whatsapp Configuration
Whatsapp message is configured to send medical reports to the patient and doctor. Twilio is a platform that provides a set of APIs to send programmable SMS through multiple mediums. It provides a basic balance of $15 for every new user.
Steps to configure WhatsApp messenger:
a. Login to Twilio and go to ‘Programmable SMS’
b. Go to ‘Setup Whatsapp’
c. Follow the set of steps mentioned on the platform.
Note: Copy and save the token and account ID mentioned on the home page.
Twilio library is used to send medical reports through Whatsapp. Token and account ID is stored in a separate file named credentials.py

Creating Web App
To create a web app, I have used Streamlit’s open-source framework. For the ones who are unaware of streamlit, It turns python scripts into the web app in minutes. It is especially for the ones like me, who have less or no experience with frontend technology. Install it using,
pip install streamlit
I have created a basic web app that has a form and that has to be filled in to see the results. It asks the user for details such as skin photo, patient’s name, and contact number, doctor’s name, and contact number. As mentioned in the “dataset” section, this dataset does not have a class named “No disease” which is very necessary. So if the confidence of the model drops below 80%, then it is considered as “No disease class”.

The web app would return the status of the process whether “Success” or “Failed” on the screen. Plus, it would send the report to the contact number of the patient and doctor through WhatsApp messenger. A snapshot of the message can be seen in the below attached image.

Conclusion
In this article, you must have learned that how deep learning has embraced medical science by automating the medical skin test. This is a basic prototype of such an application, whereas there is a lot to consider. For data science enthusiasts, Streamlit is a very easy and flexible open-source enabling us to develop a web app without explicit knowledge of front-end technologies.
You can find the demo video and all the resources here.
GitHub — DhruvGangwani/Streamlit-web-app: Skin disease detection using image classification…
Content app.py :: Flask API test_images :: Contains images for testing Model/best_model.h5 :: Trained model to classify…
github.com
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

