


Real-Time Data Linkage via Linked Data Event Streams
Last Updated on March 21, 2023 by Editorial Team
Author(s): Samuel Van Ackere
Originally published on Towards AI.
Real-time interchanging data across domains and applications is challenging; data format incompatibility, latency and outdated data sets, quality issues, and lack of metadata and context.
Using Linked Data Event Stream (LDES), data can be fluently shared between different systems and organizations. In this way, companies and organizations can ensure that their data is well-structured, interoperable, and easily consumable by other systems and services. LDES has emerged as a standard for representing and sharing up-to-date data streams.
This proof of concept explores how LDES can interchange and combine three different data sets: address registers, parcels, and building units assuming different organizations publish them.
In this way, companies and organizations can ensure that their data is well-structured, interoperable, and easily consumable by other systems and services.
If you are not familiar with Linked Data Event Stream, you can find more information about it in this article:
Linked Data Event Streams explained in 8 minutes
What is a Linked data event stream, and how can it help you make your dynamic data accessible?
medium.com
Every data stream can finally be transformed into a Linked Data Event Stream with some conversions. In this example, we start from data streams outputted via Apache Kafka.

A data flow is configured in Apache Nifi that converts these Kafka topics to an LDES server. The LDES server is a configurable component used to ingest, store, transform, and (re-)publish a Linked Data Event Stream.
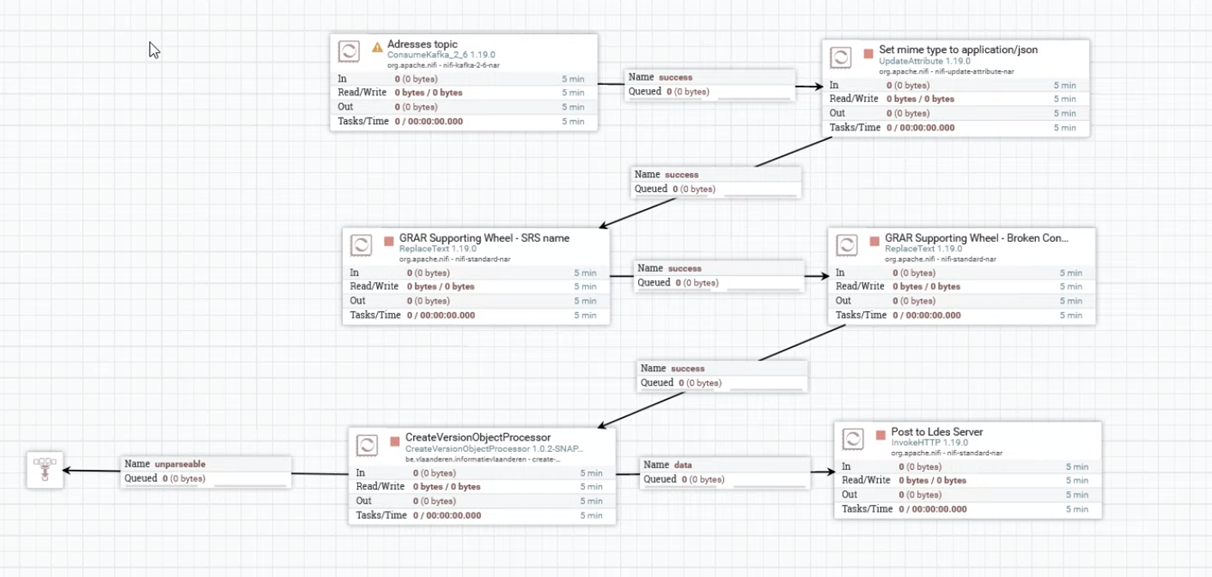
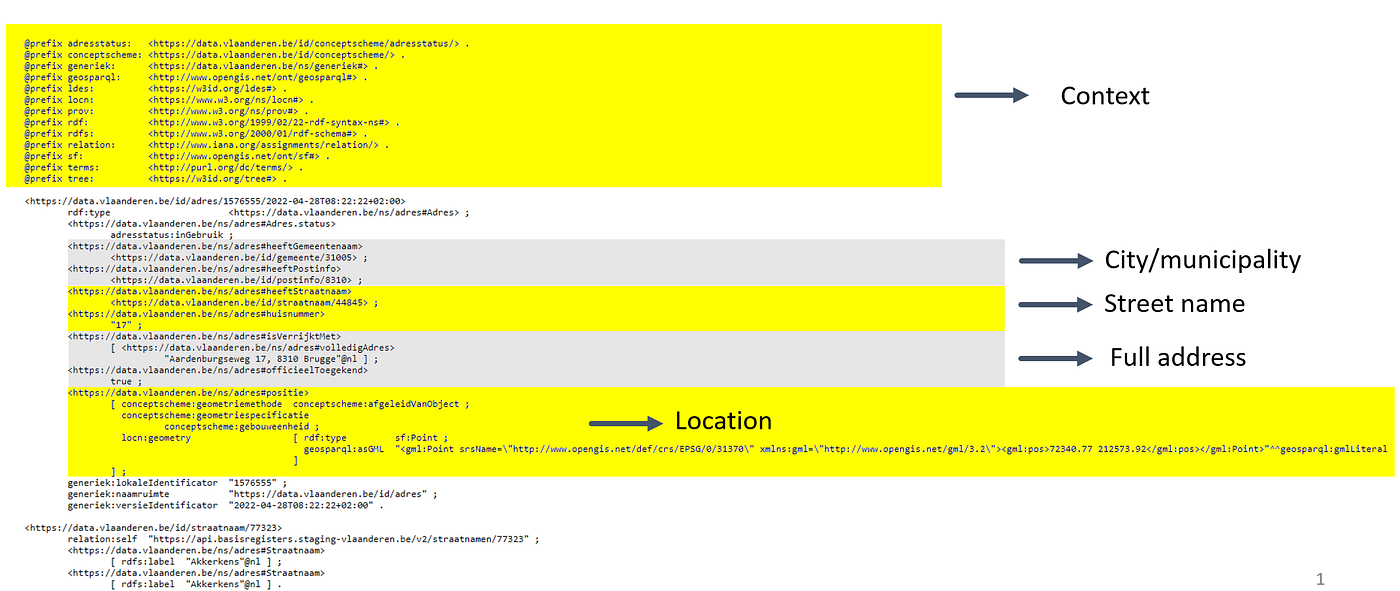
In this case, data streams from parcels, building units, and data registry from Flanders are converted into an LDES to interchange and combine afterward. These LDES all have the same structure, are always in sync with the source data, and are presented in a machine-readable format, including metadata and relationships, enabling automated discovery and integration of information across various domains and applications. The figure underneath shows one part of the address registry LDES fragment. It embeds the context of the data and information about the city or municipality, street name, full address, and location.
Interlink multiple Linked Data Event Streams
The value of publishing data sets through an LDES specification lies in the easy interlinking of data between companies and organizations over the Web. With this capability, data consumers can consume various data sets using an LDES Client, enabling a streamlined approach to accessing diverse data sources.
For this purpose, the three Linked Data Event streams are stored in a GraphDB to facilitate efficient and effective data consumption.

GraphDB supports complex semantic queries and inference, making discovering meaningful relationships between different data sources possible.
In this Github repo, you will find a docker file with the configuration of GraphDB and Apache NiFi. A data flow is configured in Apache NiFi to convert these data streams into GraphDB. You will find an Apache NiFi configuration file containing the necessary data flow.
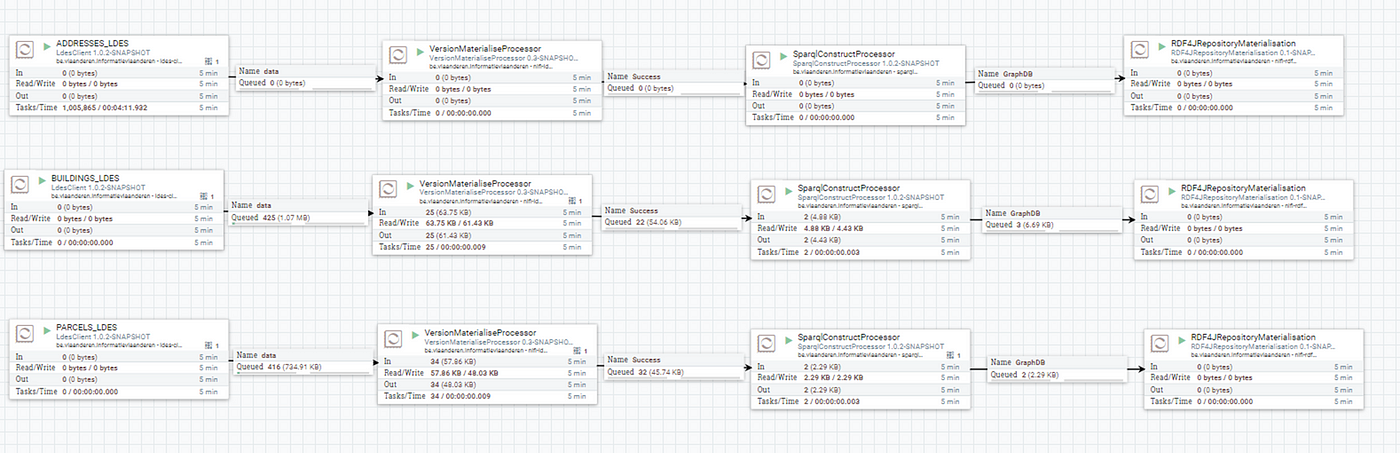
Once the Apache NiFi data flow is executed, the LDES members will flow into GraphDB. Subsequently, the data can be queried via SPARQL.

GraphDB is a powerful tool for storing and querying graph data. Still, it also offers a range of visualization possibilities that allow users to explore and understand their data in new and intuitive ways. One of the most popular visualization features in GraphDB is Graph Explorer, which provides an interactive view of a graph and allows users to navigate and search through it in real-time. This can be particularly useful for understanding complex relationships between entities, such as in social networks or biological systems.

SPARQL query
SPARQL is the standard query language and protocol for Linked Open Data on the web or for RDF triplestores. SPARQL enables the execution of semantic queries through data, offering a flexible and powerful method for searching, filtering, and retrieving structured information.
Below is an example of a SPARQL query is shown, which returns triples with information on parcels.
PREFIX gebouwregister: <https://basisregisters.vlaanderen.be/implementatiemodel/gebouwenregister#> PREFIX adres: <https://data.vlaanderen.be/id/adres/> PREFIX perceel: <https://data.vlaanderen.be/id/perceel/> PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX prov: <http://www.w3.org/ns/prov#> PREFIX ns: <https://data.vlaanderen.be/ns/generiek#>
CONSTRUCT{
?perceel rdf:type ?type .
?perceel prov:generatedAtTime ?generatedAtTime .
?perceel ns:lokaleIdentificator ?lokaleIdentificator .
?perceel ns:naamruimte ?naamruimte .
?perceel ns:versieIdentificator ?versieIdentificator .
} where {
?perceel gebouwregister:Adresseerbaar%20Object adres:2327687 .
OPTIONAL { ?perceel rdf:type ?type .
?perceel prov:generatedAtTime ?generatedAtTime .
?perceel ns:lokaleIdentificator ?lokaleIdentificator .
?perceel ns:naamruimte ?naamruimte .
?perceel ns:versieIdentificator ?versieIdentificator .}
# ?perceel gebouwenregister:Perceel%3Astatus ?status .}
}
Combining multiple data streams via their semantics
The three data streams contain unique address IDs linked respectively to the parcel, building unit, and address registry data streams. Through the use of SPARQL queries, we are able to link these data streams semantically.
In this way, developing a REST API that retrieves an RDF containing details on addresses, parcels, and building units becomes possible. Using LDES as an intermediate data format, this API ensures that the output always remains synchronized with the source database.


Full code
To replicate the whole proof of concept (LDES 2 GraphDB), please go to this Github repository. It describes how to set up the GraphDB and Apache NiFi via docker, after which the data flow can be started using the supplied Apache NiFi setup file.
GitHub – samuvack/ldes-grar
In this Proof of Concept, an Rest API is developed that makes it possible to harvest information of building units and…
github.com
Contributors to this article are ddvlanck (Dwight Van Lancker) (github.com), sandervd (Sander Van Dooren) (github.com) at Flanders Smart Data Space (Digital Flanders, Belgium). In a rapidly changing society, governments need to be more agile and resilient than ever. Digital Flanders realizes and supervises digital transformation projects for Flemish and local governments.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

