



Introduction to Deep Learning Part 2: RNNs and LTSM
Last Updated on July 17, 2023 by Editorial Team
Author(s): Koza Kurumlu
Originally published on Towards AI.
Welcome to Part 2 of my Introduction to Deep Learning series. In the last article, we covered the perceptron, neural networks, and how to train them.
In this blog post, we will introduce different neural network architectures and, more specifically, Recurrent Neural Networks and LSTM.
- Sequence modeling
- Neurons with recurrence
- Backpropagation through time
- Gradient issues
- Long short-term memory (LSTM)
- RNN applications
This series of articles is influenced by the MIT Introduction to Deep Learning 6.S191 course and can be viewed as a summary.
Recurrent Neural Networks
Recurrent Neural Networks (RNNs) are a powerful type of artificial neural network that excels at handling sequential data. This makes them particularly useful for a variety of applications, such as natural language processing, speech recognition, and time series prediction. In this beginner-friendly explanation, we’ll explore the inner workings of RNNs, their architecture, and how they can be built from scratch.
Let’s start by discussing what makes sequential data unique. Unlike other types of data, sequential data consists of a series of elements arranged in a specific order. Examples include text, speech signals, and time series data. RNNs have been specifically designed to handle this kind of data by processing each element in the sequence one at a time, while keeping track of previous elements in the sequence through a hidden state.
The architecture of RNNs is what sets them apart from other types of neural networks. They consist of a series of interconnected nodes, with each node responsible for processing one element in the sequence. These nodes are organized in a chain-like structure, allowing information to flow from one node to the next. The hidden state is the key feature of RNNs, as it captures information from previous nodes in the chain and uses it to influence the processing of future elements in the sequence. See the structure below.
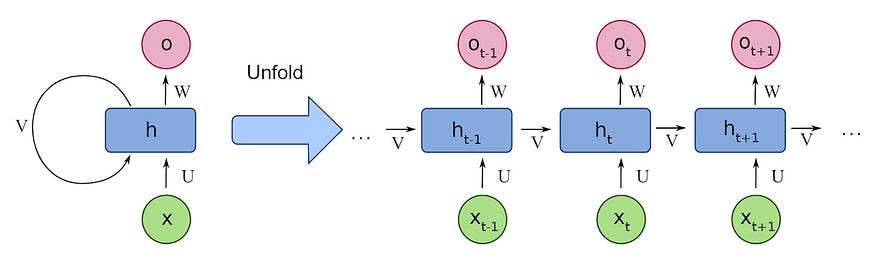
As the information flows through the network, the nodes process the data and update the hidden state. This hidden state then influences how the next node processes its input.
In this way, RNNs can “remember” previous elements in the sequence and use this memory to make predictions or decisions based on the entire sequence, rather than just the current input.
Training
So how do we train RNNs? The solution is the backpropagation through time (BPTT) algorithm. BPTT is a modification of the standard backpropagation algorithm, see previous post, designed to handle the unique structure of RNNs. The main difference is that BPTT takes into account the temporal dependencies between the nodes in the network, allowing the error to be propagated back through the entire sequence.
Now let’s break that down.
The general algorithm is as follows:
- Present a training input pattern and propagate it through the network to get an output.
- Compare the predicted outputs to the expected outputs and calculate the error.
- Calculate the derivatives of the error with respect to the network weights.
- Adjust the weights to minimize the error.
- Repeat.
The Backpropagation training algorithm is suitable for training feed-forward neural networks on fixed-sized input-output pairs, but what about sequence data that may be temporally ordered?
BUT a recurrent neural network is shown one input each timestep and predicts one output.
Conceptually, BPTT works by unrolling all input timesteps. Each timestep has one input timestep, one copy of the network, and one output. Errors are then calculated and accumulated for each timestep. The network is rolled back up and the weights are updated.
Spatially, each timestep of the unrolled recurrent neural network may be seen as an additional layer given the order dependence of the problem and the internal state from the previous timestep is taken as an input on the subsequent timestep.
We can summarize the algorithm as follows:
- Present a sequence of timesteps of input and output pairs to the network.
- Unroll the network, then calculate and accumulate errors across each timestep.
- Roll-up the network and update weights.
- Repeat.
BPTT can be computationally expensive as the number of timesteps increases. If input sequences are comprised of thousands of timesteps, then this will be the number of derivatives required for a single update weight update.
This can cause weights to vanish or explode (go to zero or overflow) and make slow learning and model skill noisy.
Fixing vanish gradients: LSTM
Long Short-Term Memory (LSTM) networks are a type of Recurrent Neural Network (RNN) specifically designed to tackle the problem of vanishing gradients.
The vanishing gradient problem occurs when gradients become smaller and smaller as they propagate backward through the network during backpropagation, resulting in slower learning or even preventing the network from learning altogether.
LSTM networks tackle this issue by introducing a memory cell, which allows the network to selectively remember or forget information over time. The memory cell is controlled by three gates: the input gate, the forget gate, and the output gate.
These gates are responsible for controlling the flow of information into, within, and out of the memory cell. They work together to decide what information to store, update, or discard at each time step. See the memory cell below.

Specifically, the input gate controls whether or not new information should be added to the memory cell. The forget gate controls whether or not old information should be removed from the memory cell. And the output gate controls how much of the memory cell should be output to the next layer of the network. In the diagram, ht-1 is the previous state, ht is the new state and xt is the input at the current step.
Applications in real life
Now we understand the structure of RNNs, let’s check out what they’re used for. They have numerous applications in real life, particularly in domains involving sequential data such as time series, natural language, speech, and audio.
Some examples of real-life applications of RNNs are:
- Language Modeling: RNNs are used for language modeling tasks such as speech recognition, machine translation, and text generation.
Large Language Models such as ChatGPT use a developed form of RNNs called Transformers
- Time Series Analysis: RNNs can be used for time series forecasting, where the goal is to predict future values based on past observations.
- Image Captioning: RNNs can be used for image captioning, where the goal is to generate a natural language description of an image.
And that’s it! In the next article, we will look at Attention Transformers and the new craze around natural language processing. Is it worth the hype?
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

