


Author(s): Ankit Sirmorya
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Reinforcement Learning in Recommendation Systems
1. INTRODUCTION
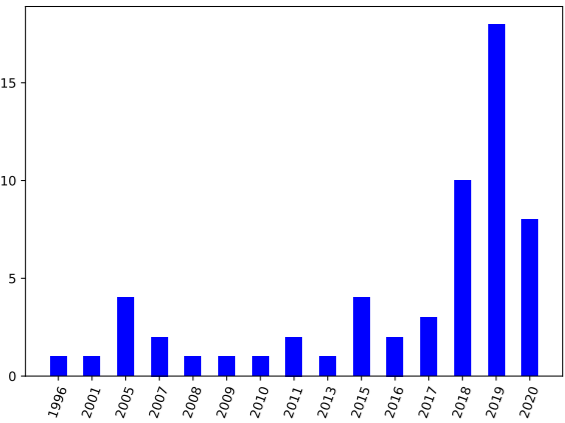
The recommendation systems (RS) are becoming an integral part of our daily lives. This means that we can obtain what we desire either through internet-accessible applications or on social media channels. Traditional views of the recommendation problem refer to it as a simple classification or prediction problem; however, recently new evidence indicates that it is essentially a sequential problem[1]. It can therefore be formulated as a Markov decision process (MDP) and reinforcement learning (RL) methods can be employed to resolve it [1]. RL algorithms play a crucial role as these algorithms are very advantageous to cope with the dynamic environment and large space [4]. In fact, recent advances in coupling deep learning with traditional RL methods i.e. Deep Reinforcement Learning (DRL), have enabled RL to be applied to the recommendation problem with massive states and action spaces. RL-based and DRL-based methods in a classified manner based on the specific RL algorithm, like Q-learning, SARSA, and REINFORCE, that is used to optimize the recommendation policy[2]. These technologies in RL may lead to an increase in the demand for recommender systems more than ever before. A hot topic for research, reinforcement learning-based recommender systems (RLRS) has become synonymous with huge amounts of data and the number of papers published on this subject every year in Fig 1 illustrates this.
2. RECOMMENDER SYSTEMS
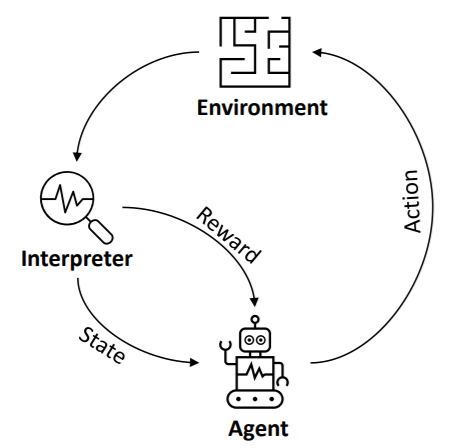
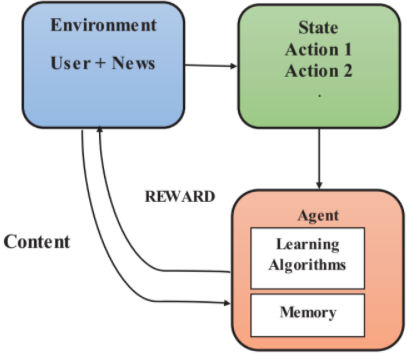
Frequently in our daily lives, we are faced with decisions without any prior knowledge of the options we have. Recommender systems (RS) aim to predict users’ interests and recommend product items that are likely to be of interest to them. RS is among the most powerful machine learning systems that online retailers implement in order to drive sales. A recommender system relies on explicit user ratings after a movie or a song has been watched or listened to. It is also derived from implicit search engine queries and purchase histories, or from other knowledge about the users/items themselves[17]. In general, recommendations speed up searches, help users find the content they’re interested in, and surprise them with offers they wouldn’t have otherwise found. It is all being possible with Machine Learning algorithms like Reinforcement Learning merging with Deep Learning concepts. RL refers to a field of machine learning that studies problems and their solutions by interacting with their environment in order to learn the most effective way to maximize a numerical reward. A typical interface to model an RL problem is the agent-environment interface, depicted in Fig. 2. Agents are usually learners or decision-makers while their environments are everything else around them.

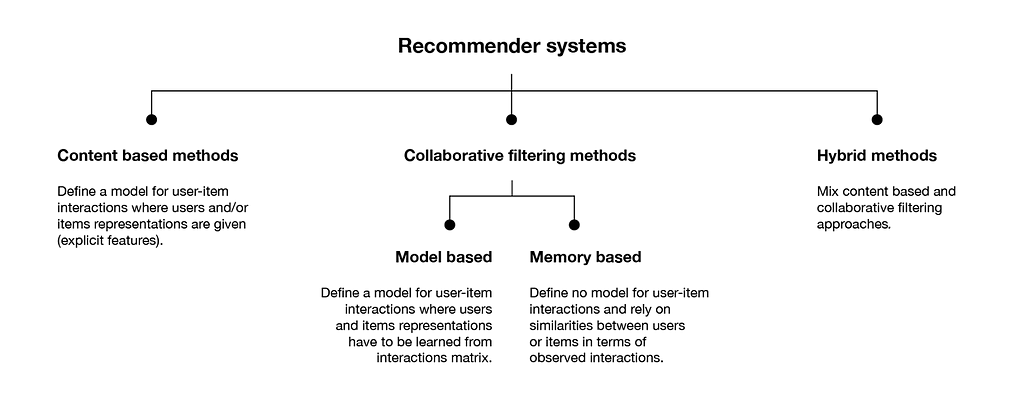
Traditional recommender systems are based on two paradigms[2], collaborative filtering and content-based systems. The Collaborative Filtering System does not require the features of the items as input[18]. This is based solely on the past interactions recorded between users and items in order to produce new recommendations[3]. These interactions are stored in the so-called “user-item interactions matrix”. A feature vector or embedding describes every user and item. This system is again sub-divided into Model-based and Memory based methods according to the model definition for user-item interactions. Unlike collaborative methods, content-based approaches use additional information about users and/or items. The user features and content features are fed into a model, which works like a traditional machine learning model with error optimization. As this model contains more descriptive information related to the content, it tends to have a high bias, but the lowest variance compared to other modeling methods. The hybrid method is another one that is a mixture of the above two algorithms[3]. In this method based on collected information in collaborative filtering methods, the user profile modeling was built. In general, these methods are called traditional RS as, because of their acute problems, namely cold start, serendipity, scalability, low quality and static recommendation, and great computational expense, it is unlikely that they are able to handle today’s recommendation problems with a huge number of users and items.

3. REINFORCEMENT LEARNING
Recommender Systems (RS), in conjunction with Reinforcement Learning(RL), is a powerful machine learning technique that can lead to advancements in user-item reciprocity. It can be used in uncertain environments. This enables an agent to learn in an interactive environment by trial and error using feedback from its own actions and experiences. RL algorithms actively explore their surroundings and exploit the acquired information to make decisions and predictions[4]. RL is concerned with how an agent performs actions within an environment to get maximum reward. The computer interacts with the environment and learns from the experience and then predicts the result. Reinforcement Learning(RL) is an unsupervised learning method that allows the optimization of a strategy in the “trial and error” process of continuously interacting with the environment[19]. Sutton and Barto [24] conclude that an RL problem has three distinguishing properties: (1) it is closed-loop, (2) the learner doesn’t have a teacher to instruct him but is required to figure it out on his own, and (3) actions affect not only the short-term results but also their long-term variations.
3.1 Diving Deeper into RL
- Agent: Agents always try to maximize the reward by taking input from the environment. That is, agents collect observation and reward from the environment and dispatch action on the environment.
- Environment: This is the place were based on a given policy agent will take action. For example, News articles and users are the environments for an agent.
- Action(A): The agent performs actions to get a reward in an environment.
- State(S): The state is an immediate situation in which an agent finds itself in relation to the other things in the surroundings of the environment such as tools, enemies.
- Reward(R): Feedback returned by environment based on the previous interaction between agent and environment.
- Policy(π): An agent uses a strategy to decide the action which should be taken on the basis of the present state. Basically, agents map states to actions. So, it decides the actions which are giving the highest rewards with regards to states.
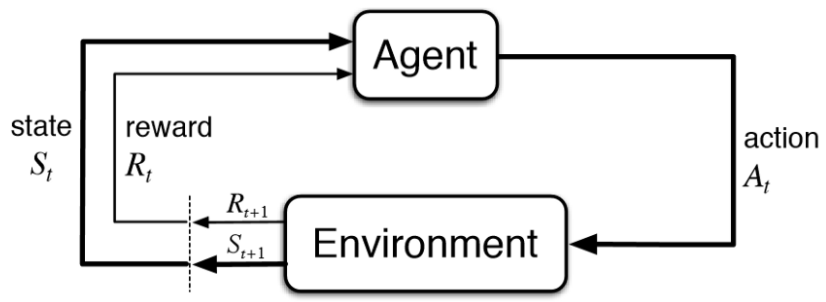
Reinforcement learning diagram interaction shown with environment and agent is shown in Fig 4.

3.2 Types of reinforcement learning
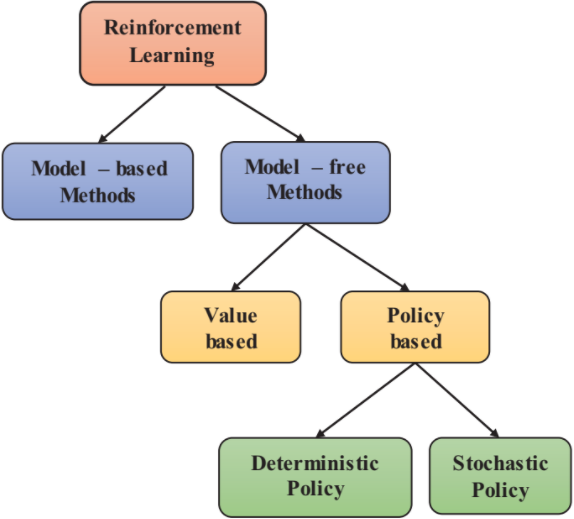
Reinforcement techniques are categorized into two methods[4] and these are Model-based and Model-free methods.
3.2.1 Model-based Reinforcement Learning:
In this learning technique, the agent estimates the optimal policy by using the transition function and reward function. Through this procedure, future states are attempted to be predicted. Model-based methods rely on planning as their primary component. This requires the use of initial states to predict the next state using the policy network. The most classic example of this learning is the Deep Q Network [14]. A DQN is currently used as the primary recommendation algorithm. Model-based reinforcement learning solutions can be applied to model user-agent interaction for offline policy learning via a generative adversarial network.
3.2.2 Model-free Reinforcement Learning:
With this learning method, optimal policies are built without estimating actions between states and reward functions. There is no prediction of future states or rewards. Model-free methods rely heavily on learning. This doesn’t require the use of initial states to predict the next state. The actor-critic approach is an example of Reinforcement Learning. A discrete mathematical approach to some kind of problem can lead to model-free RL[14].
Model-free learning is based on either a value-based or a policy-based approach. In value-based learning, we estimate how good it is to be in a certain state. We take actions for the next state that will collect the highest total rewards[15]. In a policy-based method, we directly try to optimize our policy function π without worrying about a value function. We’ll directly parameterize π (select an action without a value function)[16]. For a deterministic policy, it is the action taken at a specific state. For a stochastic policy, it is the probability of taking an action given the states[15].

4. DEEP REINFORCEMENT LEARNING
A productive machine learning technique toward the Recommender System is reinforcement learning, as we discussed before. Recommender systems have also benefited from deep learning’s success. In fact, today’s state-of-the-art recommender systems such as those at YouTube and Amazon are powered by complex deep learning systems, and less on traditional methods[29]. Deep Reinforcement Learning (DRL), a very fast-moving field, is the combination of Reinforcement Learning and Deep Learning and the most trending type of Machine Learning because it can solve a wide range of complex decision-making tasks that were previously out of reach for a machine to solve real-world problems with human-like intelligence[4]. In recent years, deep learning has garnered considerable interest in many research fields such as computer vision and natural language processing, owing not only to stellar performance but also to the attractive property of learning feature representations from scratch. The influence of deep learning(DL) is also pervasive, recently demonstrating its effectiveness when applied to information retrieval and recommender systems research. DRL is practically used in AI toolkits for training, manufacturing intelligent robots, automobile industry, finance, health care, etc. [49].
4.1 Examples of application of DRL for Recommendation (DRL):
To architect list-wise recommendation for example Ocean list-wise seafood where according to the list of seafood for each ocean demonstrated is the application of DRL [45]. In e-commerce also this list-wise recommendation is being used to raise the user experience during navigation and, consequently, generate good results for the business [46]. Therefore, in order to understand the benefits of this technology for e-commerce, the list gets benefited for the final consumer first. DRL-based recommender systems are superior to traditional algorithms in minimum error, and the application of tags has little effect on accuracy when making up for interpretability in examining the MovieLens dataset for tag-aware recommendation [47]. A principled approach to jointly generate a set of complementary items and the corresponding strategy to display them on a 2-D page and to propose a novel page-wise recommendation framework deep reinforcement learning is introduced as DeepPage, which can optimize a page of items with proper display based on real-time feedback from users [48].

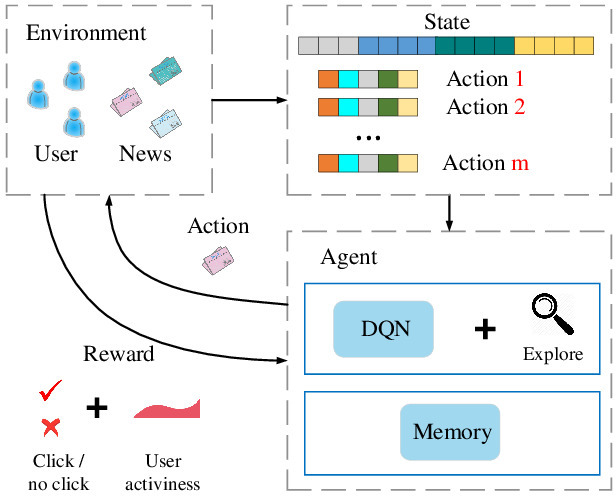
The deep reinforcement recommender system can be shown above in Fig 6. Here the common terminologies in reinforcement learning [30] are being followed to describe the system. In this system, the user pool and news pool make up the environment, and the recommendation algorithms play the role of agent. The state is defined as feature representation for users and action is defined as feature representation for news. Each time a user requests for news, a state representation (i.e., features of users) and a set of action representations (i.e., features of news candidates) are passed to the agent. The agent will select the best action (i.e., recommending a list of news to the user) and fetch user feedback as a reward. Specifically, the reward is composed of click labels and estimation of user activeness. All these recommendation and feedback logs will be stored in the memory of the agent. Every one hour, the agent will use the log in memory to update its recommendation algorithm[31].
5. REINFORCEMENT LEARNING FOR RECOMMENDER SYSTEM
Reinforcement learning is how to make the actions to maximize the reward we will receive based on the situation. It is exactly like the user reacts to a recommendation system[5]. The nature of user interaction with an RS is sequential [26] and the problem of recommending the best items to a user is not only a prediction problem but a sequential decision problem [27]. This suggests that the recommendation problem could be modeled as an MDP and solved by RL methods. Deploying RL for the design and implementation of recommender systems has two main advantages compared to alternative approaches. First, for finding an optimal strategy, RL takes account of the interacting nature of the recommendation process as well as probable changes in customers’ priorities over time. These systems consider the dynamics of changing tastes and personal preferences, hence they are able to behave more intelligently in recommending items [25]. Second, RL-based systems gain an optimal strategy by maximizing the expected accumulated reward over time. Thus, the system with small immediate rewards identifies an item to offer but provides an immense contribution to rewards for future recommendations [25].

Information retrieval (IR) techniques, such as search, recommendation, and online advertising, satisfying users’ information needs by suggesting users personalized objects (information or services) at the appropriate time and place, play a crucial role in mitigating the information overload problem. There have been increasing interests in developing DRL-based information retrieval techniques, which could continuously update the information retrieval strategies according to users’ real-time feedback, and optimize the expected cumulative long-term satisfaction from users[28]. Like this application, RSRL is being used for various technologies. Instead, with the development of DRL algorithms, it is becoming an emerging trend among the RS community to employ RL techniques.
5.1 Algorithms of RL and DRL for Recommendation

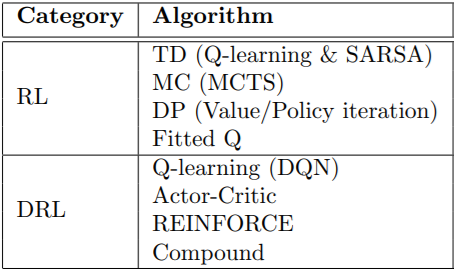
In this section, algorithms used for recommendation are presented in a classified manner. After scrutinizing all the algorithms, it can be recognized that the research on RLRS has been significantly changed with the emergence of DRL. Thus, RLRS methods are divided into two general groups: RL- and DRL-based algorithms. Table 1 provides a quick overview of the algorithms. We first target RL-based methods.
5.1.1 RL-based Methods:
RL-based methods mean those RLRS that use an RL algorithm for recommendation policy optimization where DL is not used for parameter estimation. RL-based methods include RL algorithms from both tabular and approximate approaches, including TD, DP, MC, and Fitted Q [1].
TD Methods
Temporal Difference(TD) learning, as the name suggests, focuses on the differences the agent experiences in time [33]. It is an approach to learning how to predict a quantity that depends on the future values of a given signal. TD(0) [58] is the simplest form of TD learning where, after every step, the value function is updated with the value of the next state, and along the way reward is obtained. Other important examples of TD methods are discussed below.
- Q-Learning
Q-learning has been a popular RL algorithm among the RS community [34]. It seeks to learn a policy that maximizes the total reward [62]. WebWatcher [34] is probably the first RS algorithm that uses RL to enhance the quality of recommendations. This web page was simply modeled as an RL problem and adopted Q-learning to improve the accuracy of their basic web RS, which uses a similarity function (based on TF-IDF) to recommend pages similar to the interest of the user. Q-learning is used instead of a policy iteration algorithm to optimize the policy. In particular, the idea is to cluster songs based on similar user’s performances and then replace songs with song clusters in the learning phase. A Popular K-means algorithm is used to cluster the songs. RPMRS [35] utilizes effective methods, like WaveNet [36] and Word2Vec [37], to extract features from the audio and lyrics of songs. These features are used by a CBF module [57] to shortlist an initial set of recommendations and are then refined by Q-learning.
- SARSA
SARSA is another TD algorithm used by some RSs [38]. SARSA (λ) is an approximate solution version of the original SARSA algorithm and is used in [39] to develop a personalized ontology-based web RS. The main goal of the work is to recommend the best concepts on a website to the user using RL techniques and epistemic logic programs. The goal of the RS in RL for online learning [40] is to provide the learning path for students, adapted to their specific requirements and characteristics. This model is following SARSA. There are also some works that test both Q-learning and SARSA for their policy optimization [38].
DP methods
Dynamic programming (DP) is a method for solving complex problems by breaking them down into sub-problems [39] where we have the perfect model of the environment (i.e. probability distributions of any change happening in the problem setup are known) and where an agent can only take discrete actions. The two required properties of dynamic programming are; (1) Optimal substructure: optimal solution of the sub-problem can be used to solve the overall problem, (2) Overlapping subproblems: sub-problems recur many times. Solutions of sub-problems can be cached [39] and reused and being an example of DP, Markov Decision Processes (MDP) satisfy both of these properties.
- Markov Decision Process (MDP)
Markov decision process (MDP) is a mathematical framework to delineate an environment in reinforcement learning [6] and reinforcement learning (RL) methods can be employed to decode it. One of the early valuable attempts trying to model the recommendation problem as an MDP is Decision-Theoretic Planning of Recommendation Sequences [6]. An MDP-based recommender lacks the parameters and deploying it on the real to learn them would be very expensive, thus they propose a predictive model which can provide the MDP with initial parameters. This predictive model is a Markov chain in which they model the state and transition function based on the observations in the dataset. The basic version of this Markov chain uses maximum likelihood to estimate the transition function, but they argue that it faces the data sparsity problem. Accordingly, using three techniques, skipping, clustering, and mixture modeling [1], the basic version is improved. Then, this is used to initialize the MDP-based recommender.

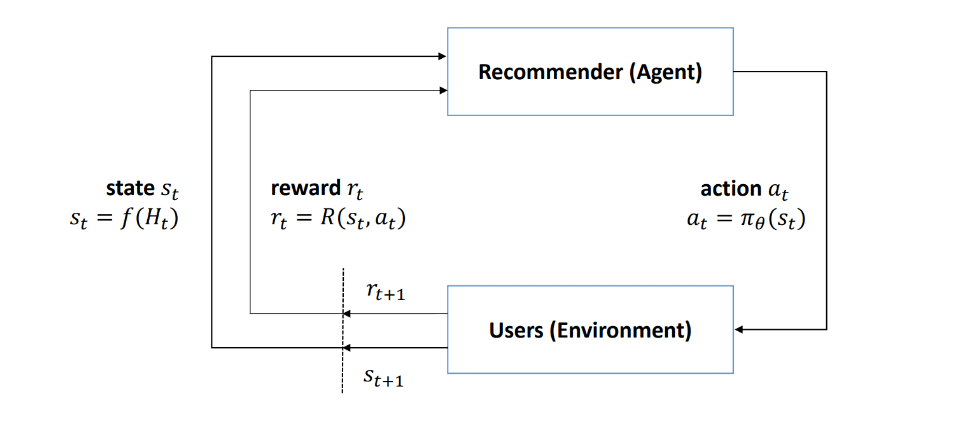
Fig 8 illustrates the recommender-user interactions in MDP formulation. Considering the current user state and immediate reward to the previous action, the recommender takes an action. In this model, an action corresponds to neither recommending an item nor recommending a list of items. Instead, an action is a continuous parameter vector. Taking such an action, the parameter vector is used to determine the ranking scores of all the candidate items, by performing inner product with item embeddings. All the candidate items are ranked according to the computed scores and Top-N items are recommended to the user. Taking the recommendation from the recommender, the user provides her feedback to the recommender, and the user state is updated accordingly. The recommender receives rewards in accordance with the user’s feedback. Without loss of generalization, a recommendation procedure is a T timestep2 trajectory expressed as (s0,a0,r0,s1,a1,r1,…,sT−1,aT−1,rT−1,sT) according to the user’s feedback. If a recommendation episode terminates in less than T timesteps, then the length of the episode is the actual value.
MC Methods
MC is the last tabular method and has been employed in some RLRS’s [40]. DJ-MC [40] is an RL-based music playlist recommender. The planning is for selecting the best song to recommend. To do this, MCTS is employed.
- Monte Carlo Tree Search(MCTS)
Monte Carlo Tree Search (MCTS) is a search technique in the field of Artificial Intelligence (AI). It is a probabilistic and heuristic-driven search algorithm that combines the classic tree search implementations alongside machine learning principles of reinforcement learning [41]. In MCTS, nodes are the building blocks of the search tree. These nodes are formed based on the outcome of a number of simulations. The process of Monte Carlo Tree Search can be broken down into four distinct steps, viz., selection, expansion, simulation, and back-propagation. These types of algorithms are particularly useful in turn-based games where there is no element of chance in the game mechanics, such as Tic Tac Toe, Connect 4, Checkers, Chess, Go, etc. For best song recommendation [40] mainly MCTS is preferred.
Fitted Q Method
The fitted Q method is a flexible framework that can fit any approximation architecture to Q-function but its limitation is high computational and memory overhead [59]. In a clinical application [63], RL is used to recommend treatment options for lung cancer patients with the objective of maximum survival for patients. They consider the treatment for patients with advanced non-small-cell lung cancer (NSCLC) as a two-line treatment, where the task of an RL agent is to recommend the best treatment option in every treatment line as well as the optimal time to initiate the second-line therapy. For the RL agent, support vector regression (SVR) is used to fit the Q-function. Since the original SVR cannot be applied to censored data, they modify SVR with -insensitive loss function [64]. Ref. [39] utilizes RL to recommend the best treatment options for schizophrenia patients. First, they use multiple imputations to address the missing data problem, which can introduce bias and increase variance in the estimates of Q-values and is caused in light of patient dropout or item missingness. The second problem they address is the fact that the clinical data is highly variable with few trajectories and makes function approximation difficult. Accordingly, they use fitted Q-iteration (FQI) with a simple linear regression model to learn the Q-function [32].
5.1.2 DRL-based Methods:
The foundation of DRL was a turning point in the field of RLRSs. DRL-based RSs in which DL is used to approximate the value function or policy. These methods use three important RL algorithms for their policy optimization, including Q-learning, actor-critic, and REINFORCE. There are also some works that test several RL algorithms for their policy optimization and compare their performance [1].
Deep Q Network (DQN)
This method modified the original Q-learning algorithm in three aspects to improve stability. Firstly, it uses experience replay and a method keeping agent’s experiences over various time steps in a replay memory, then uses them to update weights in the training phase. Secondly, to reduce the complexity in updating weights, currently updated weights are kept fixed and fed into a duplicate network whose outputs are used as the Q-learning targets. Third, to limit the scale of error derivatives, the reward function is simplified. However, DQN has three problems. Firstly, it overestimates action values in some certain cases, making learning inefficient and leading to suboptimal policies. Secondly, DQN selects experiences randomly uniformly to replay without considering their significance, making the learning process slow and inefficient. Third, DQN cannot handle continuous, which has computational expense and high infeasibility. The key features of the DQN algorithm are i. DQN has a memory buffer that stores past experience. ii. The next action is determined by the greatest output of the Q-Network. iii. The loss value was minimized compared to the Q-learning [43].

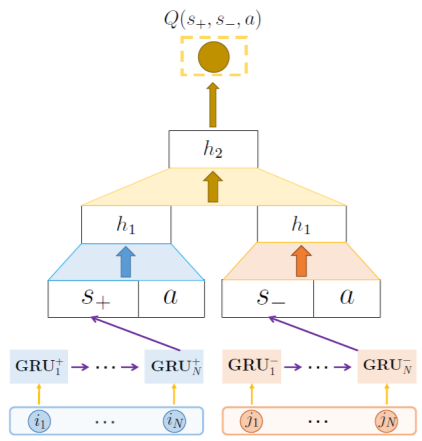
Since the number of negative feedback, like skipping items, is much larger than that of positive feedback in dosage recommendation, [54] a DRL framework is proposed, called DEERS and depicted in Fig. 9, to incorporate both feedbacks into the system. In fact, they modify the loss function of DQN such that it incorporates the effect of both feedbacks. Also, a regularization term is added to the loss function such that it maximizes the difference of Q-values of items from the same category with different feedbacks. In [44], DQN was used for optimal advertisement and finding the optimal location to interpolate an ad in a recommendation list. A socially attentive version of DQN was used in [1], which benefits from the preferences of both users and their social neighbors for estimating action values.
REINFORCE
Valuable work in the field of video recommendation using RL is presented in [50]. The main contribution of the work is to adapt the REINFORCE algorithm to a neural candidate generator with a very large action space. For each user, a sequence of user historical interactions are considered with the system, recording the actions taken by the recommender, i.e., videos recommended, as well as user feedback, such as clicks and watch time [1]. Given such a sequence, the next action to take is predicted, i.e., videos to recommend, so that user satisfaction metrics, e.g., indicated by clicks or watch time, improve. In an online RL setting, the estimator of the policy gradient can be expressed as:

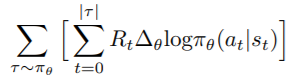
where πθ is the parametrized policy, τ = (s0, a0, s1, …), and Rt is the cumulative reward. Since in the RS setting, unlike classical RL problems, the online or real-time interaction between the agent and environment is infeasible, and usually only logged feedback is available.
Actor-Critique Methods

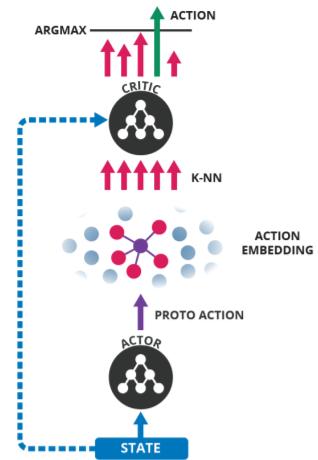
Wolpertinger [51] is an actor-critic framework that is able to handle large action spaces (up to 1 million). The idea is to provide a method that has sub-linear complexity with respect to action space and is generalizable over actions. As depicted in Fig. 10, Wolpertinger consists of two parts: action generation and action refinement. In the first part, proto-actions are generated by the actor in continuous space and then are mapped to discrete space using the k-nearest neighbor method. In the second part, outlier actions are filtered using a critic, which selects the best action that has the maximum Q value. Also, DDPG is used to train their method. Wolpertinger is not specifically designed for RSs, but they show in a simulation study that it can handle a recommendation task.
Compound Methods
A cyber-physical-social system is built that monitors the learning status of students, through collecting their multi-modal data like test scores, heartbeat, and facial expression, and then recommends a learning activity suitable for them [1]. The main contribution in [52] is to propose SlateQ, a slate-based RS. In order to decompose the Q-value of a slate into a combination of item-wise Q-values, they assume: (1) only one item from the slate is consumed by the user, (2) the reward depends only on the item consumed. Using this decomposition, they show that TD methods, like SARSA and Q-learning, can be used to maximize long-term user engagement. They also propose a flexible environment simulator, called RecSim, which simulates the dynamics of both users and RSs. In an interesting RS application that is based on SlateQ, Fotopoulou et al. [53] design an RL-like framework for an activity recommender for social-emotional learning of students.
6. LIMITATIONS OF REINFORCEMENT LEARNING
Reinforcement Learning (RL) can become a near-perfectly proficient player [32]. Since then, RL has received a lot of attention due to its ability to master well-defined tasks, such as games and NLP. But, as with any machine learning algorithm, it has its limitations over recommendation systems; these are [13] RL doesn’t generalize well. If new features or decisions are introduced, it often struggles to adapt. RL doesn’t scale well on combinatorial decision spaces. So, if we have lots of possible decisions, such as recommending lots of movies on Netflix’s home screen, RL struggles to handle the volume of possible configurations. Archiving the RL algorithm for an offline recommendation could lead to difficulties [55]. RL doesn’t handle low signal-to-noise ratio data. RL is a very powerful model that can learn intricate rules and relationships from the data. If there are noisy features, RL will fit the noise. RL doesn’t handle long time horizons. Similar to the points mentioned above, if we’re looking to optimize a long-term decision, there are a lot of opportunities to fit noise so RL can overfit if it’s given a complex optimization task [13].
7. CONCLUSION
Recommender systems consider RL to be a powerful primitive. As a branch of machine learning, RL is concerned with finding a solution to problems through the approach of assigning punishment or reward [11], and in practice, it doesn’t handle complex problems. For this, the pivotal role of DRL is being highlighted in changing the research direction in the RLRS field. By merging this technique with the recommender system there will be an appreciable success in the real-world applications of RS. The RLRS field is classified into two general groups [1] i.e., RL- and DRL-based methods. Subsequently, each general group was divided into subcategories regarding the specific RL algorithm used, such as Q-learning and actor-critic, etc. We believe that the research on RLRSs is in its infancy and needs plenty of advancements. Both RL and RS’s are hot and ongoing research areas and are of particular interest to giant companies and businesses. The enhanced learning recommendation algorithms can also be applied to recommend information on news or e-commerce websites, such as today’s headlines, JD, and Amazon, in addition to information retrieval[11]. A deep impact of RLRS is also seen in the most addictive field, the entertainment world, as it recommends music, movies, shows to viewers based on their viewing history and searches [56]. As being seen, reinforcement learning is leading a vital role in suggestions and in the vast future will be used to create recommendations for a variety of scenarios.
8. REFERENCES
- https://arxiv.org/pdf/2101.06286.pdf
- https://medium.com/ibm-data-ai/recommendation-systems-using-reinforcement-learning-de6379eecfde
- https://towardsdatascience.com/introduction-to-recommender-systems-6c66cf15ada
- https://www.google.com/url?q=https://drive.google.com/drive/folders/1lZFy9KDnW-8Ru2OD6wFgP1GXpZHf7QAy&sa=D&source=docs&ust=1643043550121570&usg=AOvVaw2ZDr6mtmPCmH6I1W4czIBj
- https://www.neurond.com/blog/reinforcement-learning-based-recommendation-system-part-2
- https://towardsdatascience.com/understanding-the-markov-decision-process-mdp-8f838510f150
- https://www.researchgate.net/publication/338190060/figure/fig19/AS:941670417825859@1601523131879/Proposed-recommendation-system-with-Q-Learning.png
- https://www.analyticsvidhya.com/blog/2020/11/reinforcement-learning-markov-decision-process/
- Y.Song, J. Wang, T. Łukasiewicz, Z. Yu and M. Xu, “Diversity — Driven Extensible Hierarchical Reinforcement Learning” Proc. AAAI conf. Artef. Intell. , 01.33, PD. 4992–4999, 2019. doi: 10.1609/aai v 33 iol . 3301 4992
- Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. 2013. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602 (2013)
- Li Yiqun; Zhang Wensheng; Yang Liu; Liu Yanqiong. “Research and application of tag-based recommendation algorithms based on reinforcement learning”, Application Research of Computers, vol.27, 2010, pp. 2845–2847,2852.
- G. Gupta and R. KAtarya, “A Study of Recommender System Using Markov Decision Process,” Proc. 2nd Int. Conf. Intell . Comput. Control Syst. ICICCS 2018, pp . 1279–1283, 2019, doi: 10. 1109/ICCONS . 2018 . 8663161.
- https://towardsdatascience.com/how-to-use-reinforcement-learning-to-recommend-content-6d7f9171b956
- https://neptune.ai/blog/model-based-and-model-free-reinforcement-learning-pytennis-case-study
- https://jonathan-hui.medium.com/rl-value-learning-24f52b49c36d
- https://www.freecodecamp.org/news/diving-deeper-into-reinforcement-learning-with-q-learning-c18d0db58efe
- https://tryolabs.com/blog/introduction-to-recommender-systems
- https://towardsdatascience.com/introduction-to-recommender-systems-1-971bd274f421#:~:text=Collaborative%20filtering%20System%3A%20Collaborative%20does,and%20items%20on%20its%20own.&text=It%20considers%20other%20users'%20reactions%20while%20recommending%20a%20particular%20user.
- Chen M, Beutel A, Covington P, et al. Top-k off-policy correction for a REINFORCE recommender system[C]//Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining. 2019: 456–464.
- J Ben Schafer, Joseph Konstan, and John Riedl. Recommender systems in e-commerce. In Proceedings of the 1st ACM conference on Electronic commerce, pages 158–166, 1999.
- Mozhgan Karimi, Dietmar Jannach, and Michael Jugovac. News recommender systems– survey and roads ahead. Information Processing & Management, 54(6):1203–1227, 2018.
- Aleksandra Klaˇsnja-Mili´cevi´c, Mirjana Ivanovi´c, and Alexandros Nanopoulos. Recommender systems in e-learning environments: a survey of the state-of-the-art and possible extensions. Artificial Intelligence Review, 44(4):571–604, 2015.
- Emre Sezgin and Sevgi Ozkan. A systematic literature review on health recommender ¨ systems. In 2013 E-Health and Bioengineering Conference (EHB), pages 1–4. IEEE, 2013.
- Richard S Sutton and Andrew G Barto. Introduction to reinforcement learning, volume 2. MIT press Cambridge, 2017.
- X. Zhao, L. Zhang, Z. Ding, D. Yin, Y. Zhao, and J. Tang, “Deep reinforcement learning for list-wise recommendations,” arXiv preprint arXiv:1801.00209, 2017.
- A. Zimdars, D. M. Chickering, and C. Meek. Using temporal data for making recommendations. In 17th Conference in Uncertainty in Artificial Intelligence, pages 580–588,2001.
- Guy Shani, David Heckerman, and Ronen I Brafman. An mdp-based recommender system. Journal of Machine Learning Research, 6(Sep):1265–1295, 2005.
- https://dl.acm.org/doi/abs/10.1145/3397271.3401467
- https://towardsdatascience.com/deep-learning-based-recommender-systems-3d120201db7e
- Richard S Sutton and Andrew G Barto. 1998. Reinforcement learning: An introduction . Vol. 1. MIT press Cambridge.
- https://dl.acm.org/doi/fullHtml/10.1145/3178876.3185994
- https://medium.com/r/?url=https%3A%2F%2Fwww.researchgate.net%2Fpublication%2F282299000_Reinforcement_learning_based_techniques_in_uncertain_environments_Problems_and_solutions
- https://www.lancaster.ac.uk/stor-i-student-sites/jordan-j-hood/2021/04/12/reinforcement-learning-temporal-difference-td-learning/
- Thorsten Joachims, Dayne Freitag, Tom Mitchell, et al. Webwatcher: A tour guide for the world wide web. In IJCAI (1), pages 770–777. Citeseer, 1997.
- Jia-Wei Chang, Ching-Yi Chiou, Jia-Yi Liao, Ying-Kai Hung, Chien-Che Huang, KuanCheng Lin, and Ying-Hung Pu. Music recommender using deep embedding-based features and behavior-based reinforcement learning. Multimedia Tools and Applications, pages 1–28, 2019.
- Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu. Wavenet: A generative model for raw audio. arXiv preprint arXiv:1609.03499, 2016.
- Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems, pages 3111–3119, 2013.
- Chung-Yi Chi, Richard Tzong-Han Tsai, Jeng-You Lai, and Jane Yung-jen Hsu. A reinforcement learning approach to emotion-based automatic playlist generation. In 2010 International Conference on Technologies and Applications of Artificial Intelligence, pages 60–65. IEEE, 2010.
- https://towardsdatascience.com/planning-by-dynamic-programming-reinforcement-learning-ed4924bbaa4c
- Elad Liebman, Maytal Saar-Tsechansky, and Peter Stone. Dj-mc: A reinforcementlearning agent for music playlist recommendation. arXiv preprint arXiv:1401.1880, 2014.
- https://www.geeksforgeeks.org/ml-monte-carlo-tree-search-mcts/#:~:text=Monte%20Carlo%20Tree%20Search%20(MCTS)%20is%20a%20search%20technique%20in,learning%20principles%20of%20reinforcement%20learning.
- Susan M Shortreed, Eric Laber, Daniel J Lizotte, T Scott Stroup, Joelle Pineau, and Susan A Murphy. Informing sequential clinical decision-making through reinforcement learning: an empirical study. Machine learning, 84(1–2):109–136, 2011.
- Nguyen, Ngoc Duy, Thanh Nguyen, and Saeid Nahavandi. “System design perspective for human-level agents using deep reinforcement learning: A survey.” IEEE Access 5 (2017): 27091–27102.
- X. Zhao, C. Gu, H. Zhang, X. Liu, X. Yang, and J. Tang, “Deep reinforcement learning for online advertising in recommender systems,” 2019.
- https://seafood.ocean.org/seafood/
- https://www.smarthint.co/en/What-is-a-recommendation-system%3F/
- https://www.hindawi.com/journals/mpe/2021/5564234/
- https://dl.acm.org/doi/abs/10.1145/3240323.3240374
- https://towardsdatascience.com/drl-01-a-gentle-introduction-to-deep-reinforcement-learning-405b79866bf4
- Minmin Chen, Alex Beutel, Paul Covington, Sagar Jain, Francois Belletti, and Ed H Chi. Top-k off-policy correction for a reinforce recommender system. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, pages 456–464, 2019.
- Gabriel Dulac-Arnold, Richard Evans, Hado van Hasselt, Peter Sunehag, Timothy Lillicrap, Jonathan Hunt, Timothy Mann, Theophane Weber, Thomas Degris, and Ben Coppin. Deep reinforcement learning in large discrete action spaces. arXiv preprint arXiv:1512.07679, 2015.
- Eugene Ie, Vihan Jain, Jing Wang, Sanmit Narvekar, Ritesh Agarwal, Rui Wu, Heng-Tze Cheng, Morgane Lustman, Vince Gatto, Paul Covington, et al. Reinforcement learning for slate-based recommender systems: A tractable decomposition and practical methodology. arXiv preprint arXiv:1905.12767, 2019.
- Eleni Fotopoulou, Anastasios Zafeiropoulos, Michalis Feidakis, Dimitrios Metafas, and Symeon Papavassiliou. An interactive recommender system based on reinforcement learning for improving emotional competences in educational groups. In International Conference on Intelligent Tutoring Systems, pages 248–258. Springer, 2020.
- Xiangyu Zhao, Liang Zhang, Zhuoye Ding, Long Xia, Jiliang Tang, and Dawei Yin. Recommendations with negative feedback via pairwise deep reinforcement learning. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 1040–1048, 2018.
- https://arxiv.org/abs/2005.01643
- http://ijettjournal.org/2018/volume-61/IJETT-V61P229.pdf
- https://xcpengine.readthedocs.io/modules/cbf.html#cbf
- https://towardsdatascience.com/temporal-difference-learning-47b4a7205ca8
- https://www.neurond.com/blog/reinforcement-learning-based-recommendation-system-part-3
- https://medium.com/r/?url=https%3A%2F%2Fmiro.medium.com%2Fmax%2F3000%2F1*rCK9VjrPgpHUvSNYw7qcuQ%402x.png
- https://web.stanford.edu/class/psych209/Readings/SuttonBartoIPRLBook2ndEd.pdf
- https://medium.com/r/?url=https%3A%2F%2Ftowardsdatascience.com%2Fsimple-reinforcement-learning-q-learning-fcddc4b6fe56
- Yufan Zhao, Donglin Zeng, Mark A Socinski, and Michael R Kosorok. Reinforcement learning strategies for clinical trials in nonsmall cell lung cancer. Biometrics, 67(4):1422– 1433, 2011.
- Vladimir Vapnik. The nature of statistical learning theory. Springer science & business media, 2013.

Natural Language Processing was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI