Logo:
Logo:  Areas Served:
Areas Served: 
Learn State-of-the-art Deep Learning Directly from MIT for Free and More!
Last Updated on November 10, 2021 by Editorial Team
Author(s): Towards AI Team
AI news, research, and updates, an exciting and free-to-access state-of-the-art AI data management platform, and our monthly editorial picks!
If you have trouble reading this email, see it on a web browser.
Welcome back, Towards AI family! It has been a little while since we sent our last newsletter. In this edition, we are bringing you some exciting goodies we think you will love. To get started, check out this excellent NLP app created by Kunal Marwaha that makes word clouds from arXiv abstracts (based on our tests, it is very accurate!).
Collecting, labeling, and delivering high-quality datasets is probably taking you weeks, if not months. With Superb AI, train our transfer learning auto-label model within an hour with a small ground-truth dataset, bulk label massive datasets in minutes, audit for quality, and deliver — all in a matter of days! What are you waiting for? Sign up for free.
We recently launched our book on descriptive statistics with Python. If you haven’t checked it out yet, this article or this PDF provides a sample of the first 36 pages of the book. Please don’t forget that you can access this work, many more books, and other goodies by becoming a member.
Next, if you are currently interested in pursuing a Ph.D. in machine learning or a related field, we recommend checking out this piece by machine learning at Carnegie Mellon, which highlights which questions you should consider asking a prospective Ph.D. advisor to make out the best possible match for your research interests.
What properties of datasets drive modeling innovation? This talk by Stanford Professor Percy Liang highlights taming deep models and shaping their development with two novel approaches.
Transformer networks have revolutionized the NLP landscape, this excellent post by Salesforce Research written by Cameron Wolfe discusses what they can do to improve graphical neural modeling.
Now into the monthly picks! We pick these articles based on readers, fans, and views a specific piece gets. We hope you enjoy reading them as much as we did. Also, we started doing something new! We will pick our top-performing articles, and our editors will choose a couple of essays that didn’t have outstanding performance, but due to their quality — they made the cut for the month.
If you can, please share the newsletter or our subscription link with your friends, colleagues, and acquaintances. One email per month; unsubscribe anytime! If you have any feedback on how we can improve, please feel free to let us know.
📚 Editor’s choice featured articles of the month ↓ 📚

The Ultimate Guide to Acing Machine Learning Interviews for Data Scientists and Machine Learning Engineers by Emma Ding and Ziheng Lin
The internet is flooded with top 10, top 20, and even top 200 machine learning interview questions covering many concepts from bias vs. variance to deep neural networks. While those concepts are important to master to ace machine learning interviews, you may feel underprepared and are often caught off-guard during interviews when you are only prepared to solve those problems. The truth is that machine learning interviews are more comprehensive than just a Q&A of basic machine learning concepts. Machine learning interviews evaluate a candidate’s capacity to work with a team to solve complex real-world problems using machine learning methodologies.
[ Read More ]

3 Reasons Why the New MIT Deep Learning Course is Ideal for Beginners by Ahmar Shah, Ph.D. (Oxford)
This course is getting released now, as we speak (rather, … as you read). This is MIT’s “Introduction to Deep Learning” (MIT 6.S191), and it is now in its fifth year. This is a 2-week intensive course that introduces the topic and goes into a decent amount of detail, covering both the fundamentals and applications. MIT has been exceptionally generous to have all the material available online for free for anyone to learn from. The 2021 edition is getting released to the wider public now. The first lecture was only released on…
[ Read More ]
K-Nearest Neighbors (KNN) Algorithm Tutorial — Machine Learning Basics by Sujan Shirol, Husna Sayedi, Roberto Iriondo
The k-nearest neighbor algorithm, commonly known as the KNN algorithm, is a simple yet effective classification and regression supervised machine learning algorithm. This article will be covering the KNN Algorithm, its applications, pros and cons, the math behind it, and its implementation in Python. Please make sure to check the entire implementation from this tutorial on either Google Colab or Github to aid with your reading.
[ Read More ]

Perceptron Is Not SGD: A Better Interpretation Through Pseudogradients by Francesco Orabona
There is a popular interpretation of the Perceptron as a stochastic (sub)gradient descent procedure. I even found slides online with this idea. The thought of so many young minds twisted by these false claims was too much to bear. So, I felt compelled to write a blog post to explain why this is wrong… Moreover, I will also give a different and (I think) much better interpretation of the Perceptron algorithm.
[ Read More ]

Deploy a Python Machine Learning Model on your iPhone by Patrick Long
This article describes the shortest path from training a python machine learning model to a proof of concept iOS app you can deploy on an iPhone. The goal is to provide the basic scaffolding while leaving room for further customization suited to one’s specific use case. We will overlook some tasks such as model validation and building a fully polished user interface (UI) in the spirit of simplicity. By the end of this tutorial, you will have a trained model running on iOS that you can showcase as a prototype and load to your device…
[ Read More ]
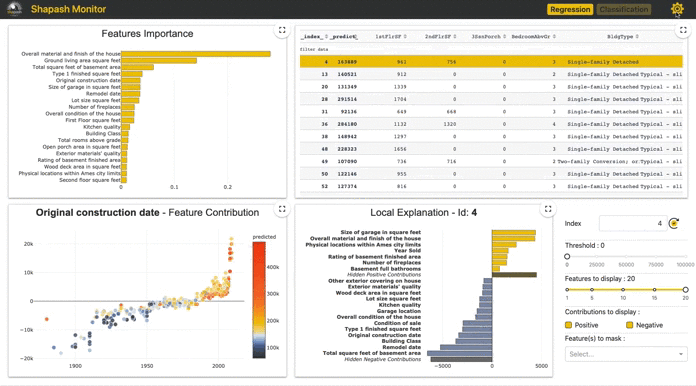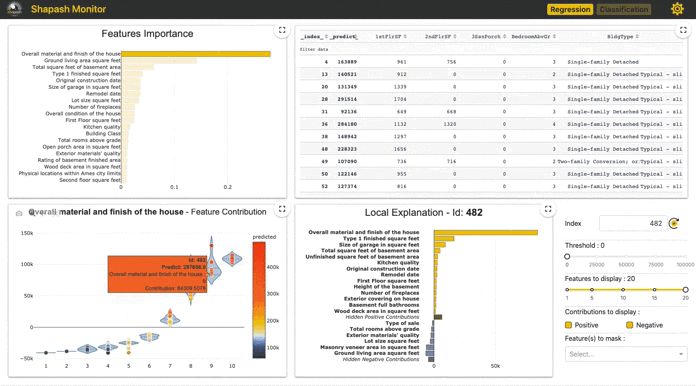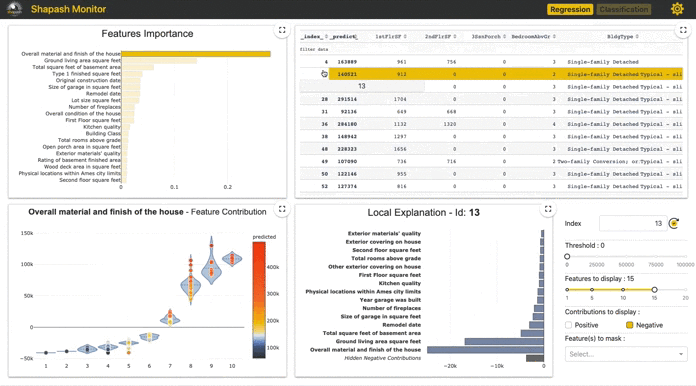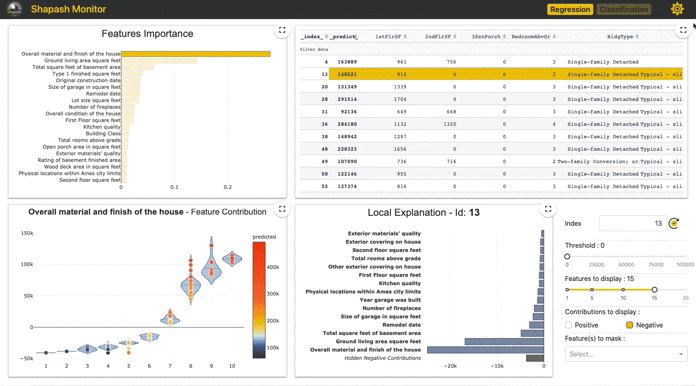
Shapash: Making ML Models Understandable by Everyone by Yann Golhen
Shapash by MAIF is a Python Toolkit that facilitates the understanding of Machine Learning models to data scientists. It makes it easier to share and discuss the model interpretability with non-data specialists: business analysts, managers, end-users. Concretely, Shapash provides easy-to-read visualizations and a web app…
[ Read More ]

How to Build a Prometheus Exporter for Sensor Monitoring by Guillaume Vincent
In this article, we will set up a DHT22/AM2302 sensor on a Raspberry Pi. This sensor connects to a GPIO pin and reports temperature and humidity data. We’ll see how to connect it to the Raspberry Pi and confirm the data acquisition. Wouldn’t it be better to centralize all our metrics in one place? Well, we’ll code a Prometheus exporter using the Golang language. Prometheus is an open-source project for monitoring and alerting using a time-series database…
[ Read More ]

Must-have Chrome Extensions For Machine Learning Engineers And Data Scientists by Himanshu Ragtah
Browser extensions are the secret weapons that most hackers and developers keep in their arsenal to be more productive. Since a good portion of machine learners use chrome (given chrome’s massive market share), I’ve compiled a list of must-have Chrome extensions for machine learning engineers and data scientists.
[ Read More ]

NLP using Deep Learning Tutorials: Understand the Activation Function by Abdelkader Rhouati
This article is a first of a series that I’m writing, and where I will try to address the topic of using Deep Learning in NLP. First of all, I was writing an article for an example of text classification using a perceptron, but I thought it would be better to review some basics before, as activation and loss functions…
[ Read More ]
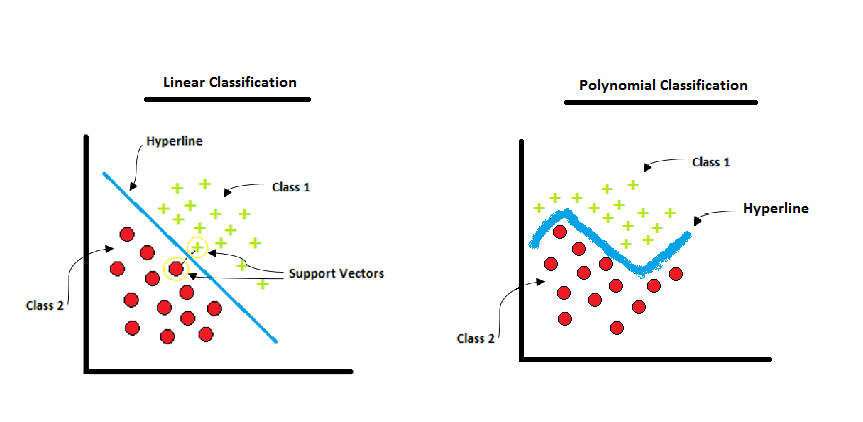
Fully Explained SVM Classification with Python by Amit Chauhan
In this article, we will discuss the most used machine learning algorithm in classification problems. The support vector machine (SVM) algorithm is used for regression, classification, and outlier detection. The decision points or support vectors separate the hyper line or hyperplane. The support vectors are the sample points that provide maximum margin between the closest different class points. This separation…
[ Read More ]

Uber AresDB is an Open Source, GPU-Powered Database for Large-Scale Analytics Workloads by Jesus Rodriguez
Uber has to rank among the greatest contributors to open source data science infrastructure and frameworks. From machine learning frameworks like Horovod or Pyro to time-series infrastructures such as M3, the Uber engineering team has been incredibly active in open-sourcing different stacks that are key building blocks of Uber’s data science pipeline. Earlier this week, Uber unveiled yet another super cool technology to enable modern analytics solutions. AresDB is a database and runtime for massively scalable, real-time analytics workloads.
[ Read More ]

Genetic Algorithm — Stop Overfitting Trading Strategies by Louis Chan
In a previous blog, we have talked about how the Genetic Algorithm can optimize parameters of a trading strategy, hence parameters of any non-linear functions given an appropriate fitness/cost function. The arguably most important part that we have not touched on is how do we make sure that the GA is well-fitted but not overfitted.
[ Read More ]
Finding Time-shift Between Two Time-series for Maximum Correlation by Rahul Bhadani
Several engineering and science applications deal with time-series data. For example, in autonomous driving, several augmented and on-board sensors collect information about speed, acceleration, fuel usages, etc., in the form of time-series data. Usually, the same kind of information is gathered from multiple sensors that involve some sensor fusion to build confidence around the gathered dataset…
[ Read More ]

How to Use MongoDB to Store and Retrieve ML Models by Chetan Ambi
If you are looking for a database for storing your machine learning models, this article is for you. You can use MongoDB to store and retrieve your machine learning models. Without further adieu, let’s jump to the main topic. MongoDB is a viral NoSQL database. In MongoDB, the data is stored in the form of JSON-like documents. More specifically, documents are stored in a BSON object which is nothing but binary data represented in…
[ Read More ]

Microsoft Azure Synapse Analytics Workspace vs. Snowflake Data Cloud by Karthikeyan Siva Baskaran
Organizations started moving towards data-driven business decisions as a part of digital transformation. To build a data-driven culture, data mobilization is vital to retrieve actionable insights. As data proliferates, there is a need to build an Enterprise Data Warehouse or Data Lake to do analytics on top of it. To create a single source of truth for enterprise data, businesses tend to focus more on storing and managing data on a robust platform that can scale as the volume of data grows.
[ Read More ]
A Simple and Scalable Clustering Algorithm for Data Summarization by Haris Angelidakis
In the era of big data, the need for designing efficient procedures that summarize millions of data points in a meaningful way is more pressing than ever. One of the most successful ways to do so falls into the unsupervised learning framework is clustering. Roughly speaking, assuming that there is some notion of distance between points that captures how similar or dissimilar two points are, the goal of a clustering algorithm is the following…
[ Read More ]
🙏 Thank you for being a subscriber with Towards AI! 🙏
Follow us ↓
[ Facebook ] |[ Twitter ]| [ Instagram ]| [ LinkedIn ] | [ Github ] | [ Google News ]
Learn State-of-the-art Deep Learning Directly from MIT for Free and More! was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Related posts
Popular posts

 for 2021")



Updates

Recent Posts