


Author(s): Flo
Originally published on Towards AI.
Using n_init and K-Means++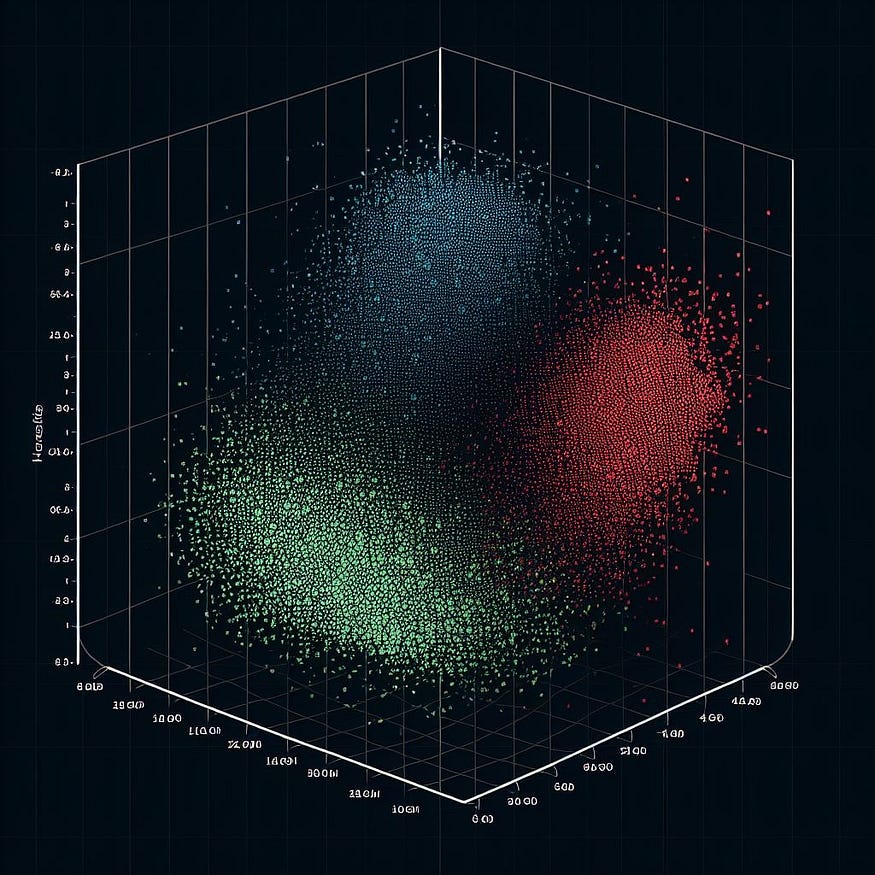
image by Flo
K-Means is a widely-used clustering algorithm in Machine Learning, boasting numerous benefits but also presenting significant challenges. In this article, we delve into its limitations and offer straightforward solutions to address them.
K-Means is a clustering algorithm that partitions data into K clusters. It initializes K centroids randomly and then assigns each data point to the nearest centroid. Centroids are recalculated based on the mean of assigned points, and the process repeats until convergence.
I illustrate it below with t-distributed stochastic neighbor embedding, a dimension reduction technique. Each cluster is represented by a color.
K-Means clusters via T-SNE, image by Flo
K-Means… Read the full blog for free on Medium.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI