
 Logo:
Logo:  Areas Served:
Areas Served: 
The NLP Cypher | 05.02.21
Last Updated on July 24, 2023 by Editorial Team
Author(s): Quantum Stat
NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER
The NLP Index
As an applied machine learning engineer (aka hacker ?? aka flying ninja ??), I’m consistently looking for better and faster ways to stay on top of the deep learning and software development circuit. After comparing various sources for research, code, and apps. I’ve discovered that a significant amount of awesome NLP code is not on arXiv and not all NLP research is on GitHub. To obtain a wider scope of current NLP research and code, I’ve created the NLP Index! A search-as-you-type search engine containing over 3,000 NLP repositories (updated weekly) ?. The index contains the research paper, a ConnectedPapers link for a graph of related papers, and its GitHub repo.
The intent of this platform is for researchers and hackers to obtain information quickly and comprehensively about all things NLP. And not just from research papers, but from awesome apps that are created on top of this research.
We’ve included the option of open search (as opposed to exclusively only serving pre-defined categories) because of inter-dependencies among subject areas. Meaning, sometimes a paper/repo can be both about “knowledge graphs” and “datasets” simultaneously and it’s difficult to discretize topics. We prefer giving the user the option of openly searching the database across all domains/sectors simultaneously. We also included pre-defined queries with dozens of topics in NLP via the sidebar for convenience.
The index has several attributes such as: search as you type, typo tolerance, and synonym detection.
Synonym Detection
For example, if you search for “dataset” the database will also search for “corpus” and “corpora” text simultaneously to make sure every asset is searched. ?
Typo Tolerance
If you search “gpt2" it will also include “gpt-2"
Search as you type
It will output results on every character as you type in real-time taking only a couple milliseconds. (thank you memory mapping ?)
Also want to mention that the Big Bad NLP Database has already been merged with the NLP Index! For the most up-to-date compendium of NLP datasets, you can go to the “data” section of the sidebar and click dataset or openly search for a specific dataset/task. Eventually, I will sunset the BBND URL and eventually redirect it to the Index.
Want to thank all of the support I’ve received over the past week after taking the NLP Index live. Thank you to Philip Vollet for sharing his dataset with hundred of NLP repos. You can find his posts in the “Uncharted” section.
More features coming soon. Stay tuned. ?
BERT, Explain Yourself!
Discover why BERT makes an inference using SHAP (SHapley Additive exPlanations); a game theoretic approach to explain the output of any machine learning model. It leverages the Transformers pipeline.

Colab of the Week
Explainable AI Cheat Sheet
Includes graphic, YouTube vid, and several links with papers/ books discussing the topic of explainable AI.
StyleCLIP is Too Much Fun!
Awesome introduction from Max Woolf on using StyleCLIP (via Colab notebooks) to manipulate headshot pics via text prompts. You can even add your own pictures, the quality is pretty good. For example, take a look at the generation after the text prompt: “Face after using the NLP index” ? ??

Easily Transform Portraits of People into AI Aberrations Using StyleCLIP | Max Woolf's Blog
Software Updates
AdapterHub
New version includes BART and GPT-2 models ?
Adapters for Generative and Seq2Seq Models in NLP
BERTopic
(semi-)supervised topic modeling by leveraging supervised options in UMAP
- model.fit(docs, y=target_classes)
Backends:
- Added Spacy, Gensim, USE (TFHub)
- Use a different backend for document embeddings and word embeddings
- Create your own backends with bertopic.backend.BaseEmbedder
- Click here for an overview of all new backends
Calculate and visualize topics per class
- Calculate: topics_per_class = topic_model.topics_per_class(docs, topics, classes)
Visualize: topic_model.visualize_topics_per_class(topics_per_class)
Release Major Release v0.7 · MaartenGr/BERTopic
Repo Cypher ??
A collection of recently released repos that caught our ?
Gradient-based Adversarial Attacks against Text Transformers
A general-purpose framework, GBDA (Gradient-based Distributional Attack), for gradient-based adversarial attacks, and apply it against transformer models on text data.
facebookresearch/text-adversarial-attack
Easy and Efficient Transformer
Pytorch inference plugin for transformers with large model sizes and long sequences. Currently supports GPT-2 and BERT models.
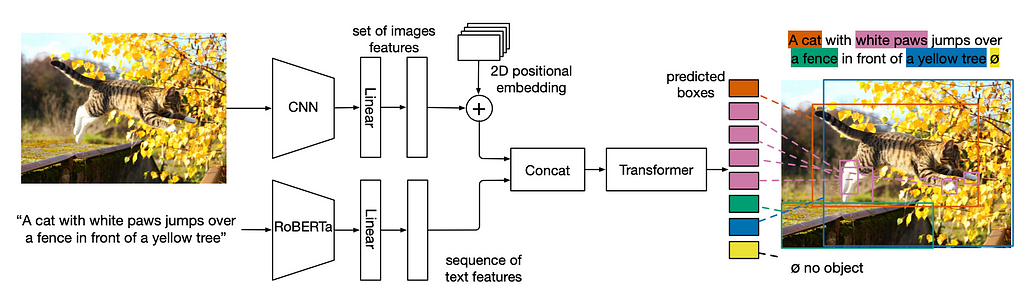
MDETR: Modulated Detection for End-to-End Multi-Modal Understanding
Code and links to pre-trained models for MDETR (Modulated DETR) for pre-training on data having aligned text and images with box annotations, as well as fine-tuning on tasks requiring fine grained understanding of image and text.
XLM-T — A Multilingual Language Model Toolkit for Twitter
Continues pre-training on a large corpus of Twitter in multiple languages on the XLM-Roberta-Base model. Includes 4 colab notebooks.
FRANK: Factuality Evaluation Benchmark
A typology of factual errors for fine-grained analysis of factuality in summarization systems.
Legal Document Similarity
A collection of state-of-the-art document representation methods for the task of retrieving semantically related US case law. Text-based (e.g., fastText, Transformers), citation-based (e.g., DeepWalk, Poincaré), and
hybrid methods were explored.
malteos/legal-document-similarity
Dataset of the Week: Shellcode_IA32 ??
What is it?
Shellcode_IA32 is a dataset containing 20 years of shellcodes from a variety of sources is the largest collection of shellcodes in assembly available to date. This dataset consists of 3,200 examples of instructions in assembly language for IA-32 (the 32-bit version of the x86 Intel Architecture) from publicly available security exploits. Dataset is used for automatically generating shell code (code generation task). Assembly programs used to generate shellcode from exploit-db and from shell-storm were collected.
Where is it?
Every Sunday we do a weekly round-up of NLP news and code drops from researchers around the world.
For complete coverage, follow our Twitter: @Quantum_Stat

The NLP Cypher | 05.02.21 was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Related posts
Popular posts

 for 2021")



Updates

Recent Posts



