
 Logo:
Logo:  Areas Served:
Areas Served: 
Next-Gen Search powered by Jina
Last Updated on May 3, 2021 by Editorial Team
Author(s): Shubham Saboo
Technology
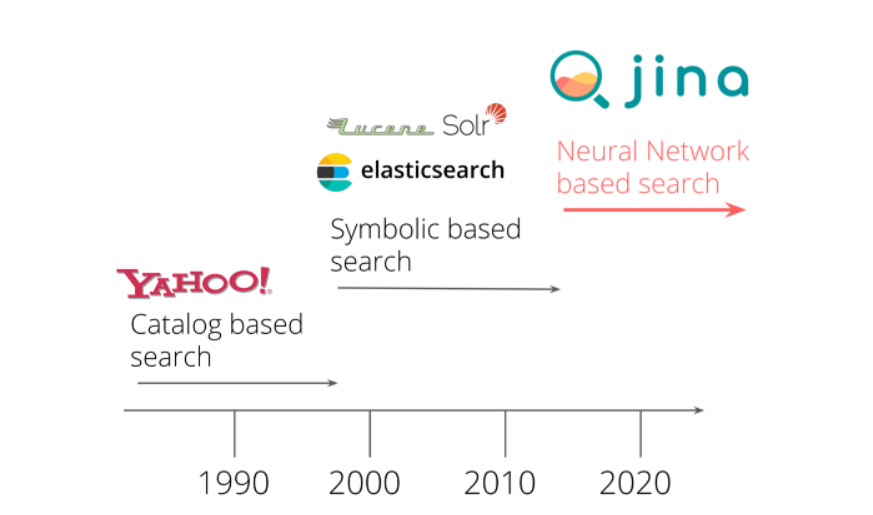
Since the inception of online search, the world has changed dramatically, but the “curiosity” that fuels the business remains constant…
What is Neural Semantic Search?
A neural search is an intelligent approach towards retrieving contextual and semantically relevant information. Instead of telling a machine a set of rules to understand what data is what, neural search does the same thing with a pre-trained neural network. This means developers don’t have to write every little rule, saving them time and headaches, and the system trains itself to get better as it goes along.
Conventional Search v/s Neural Search

Conventional search
- Conventional search is symbolic and keyword-driven due to which it lacks the necessary context.
- Conventional search is fragile due to its hard-coded rule engines.
- Conventional search requires updating of rules with the new addition of data, making it non-scalable and time-consuming.
- Conventional search requires a level of domain knowledge to implement.
Neural/Semantic Search
- Neural search is context-driven enabling it to find semantically relevant information.
- Neural search is flexible in adapting to all the corner cases and resilient to noise.
- Neural search on the other hand can train itself on the new data using the past inferences/context making it highly scalable and efficient.
- Neural search requires little to no domain knowledge to implement.
What is Jina?
Jina is a cloud-native neural search platform. It can be deployed in containers, clod, or on-prem servers. It offers anything-to-anything search ranging from Text-to-text, image-to-image, video-to-video, or any other data type that you can feed as input to the engine. Jina operates on its primitive data type known as a document. Documents are pieces of data in any dataset you want to search, and the input queries you use to find what you want.
Basically, they are the input and output data for the Jina search workflows. Jina core comprises of two main flows, which are the heart and soul of the semantic search engine:
- Indexing Flow: An indexing Flow makes the whole corpus searchable by sentence. The indexing flow prepares and pre-processes the data to be searched. The input documents are fed in, processed, and output at the other end is stored as searchable indexes.

- Querying Flow: A querying flow takes the user query as an input document (primitive Jina data type) and returns a list of ranked matches based on the similarity score within the word embeddings.

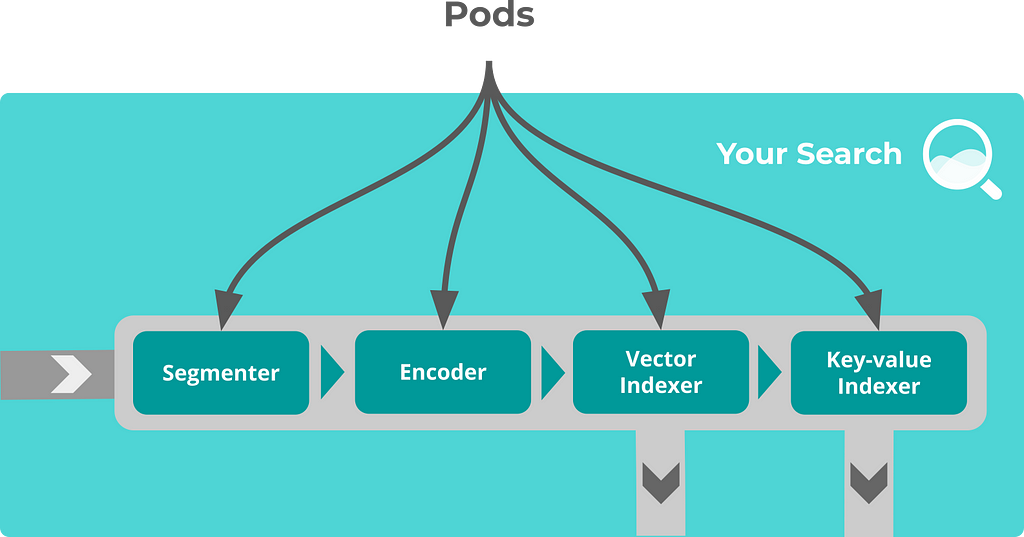
Jina Components
Flow represents a high-level task, e.g. indexing, searching, training. It consists of a group of pods, orchestrating them to accomplish one task. A pod is a group of executors sharing the same properties, it allows parallel execution of multiple executors and adds context and control to the executors.
Executor represents an algorithmic unit in Jina. Algorithms such as encoding images into vectors, storing vectors on the disk, ranking results, can all be formulated as Executors. Executor provides useful interfaces, allowing AI developers and engineers to really focus on the algorithm. Some common executors are as follows:
- Crafter: Crafter is used for pre-processing and the documents into chunks.
- Encoder: Encoder takes the input pre-processed chuck of documents from the crafter and encodes them into embedding vectors.
- Indexer: Indexer takes the encoded vectors as input and indexes and stores the vectors in a key-value fashion.
- Ranker: Ranker runs on the indexed storage and sorts the results based on a certain ranking.
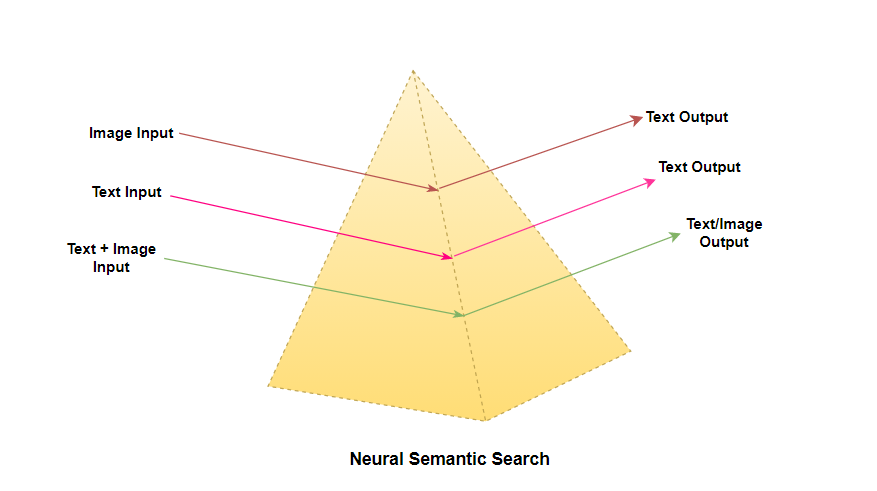
Search Modalities
Jina is a data type-agnostic framework, that lets you work with any type of data and run cross-modal and multi-modal search Flows.
- Single Modality: In this type of search the type of input and the type of output remains the same, it includes text-to-text search, image-to-image search, audio-to-audio search, etc. In a single modality, the search is designed to deal with a single data type making it less flexible and fragile to the input of different data types.
- Cross Modality Search: It enables you to effectively find relevant documents of modality A (let's say — “image”) by querying with documents from modality B (let's say — “text”). Cross Modality refers to a set of applications where you can look for documents of one modality (e.g. images) with queries from another one (e.g. text).
- Multi-Modality Search: It enables you to project documents of different modalities into a common embedding space, and find relevant documents with respect to the fusion of multiple modalities Multi-Modality is when you merge information in a query from different modalities as in providing an infused input consisting of (text+image) to get the output which can be flexible depending on the interpretation by the model.
Support to different types of modalities unlocks a lot of powerful patterns and makes Jina fully flexible and agnostic to what can be searched.
Jina in Action
For showcasing a live demo, I have designed a simple neural semantic search for textual data. The model is trained on the data taken from a random Wikipedia page. Jina takes the input document and follows through the internal Jina flows (Indexing followed by Querying) to come up with a search engine.
Frameworks/Tools Used:
- Jina Core: It enables the indexing and querying workflows for the respective application.
- Language Model: The language model used here comes from the BERT(Bi-directional Encoder representation for Transformers) family, here we have used “distilbert-bert-cased” for understanding the context under the querying flow of Jina.
- Jina Box: Jina Box is an easy-to-use, lightweight, customizable front-end web component for data type agnostic search (be it text, audio, video, etc.) that can be easily connected to the Jina backend providing the user with a simple and efficient interface to interact with the search engine.
- Python 3.7: It is used as the development environment for the Jina Application.
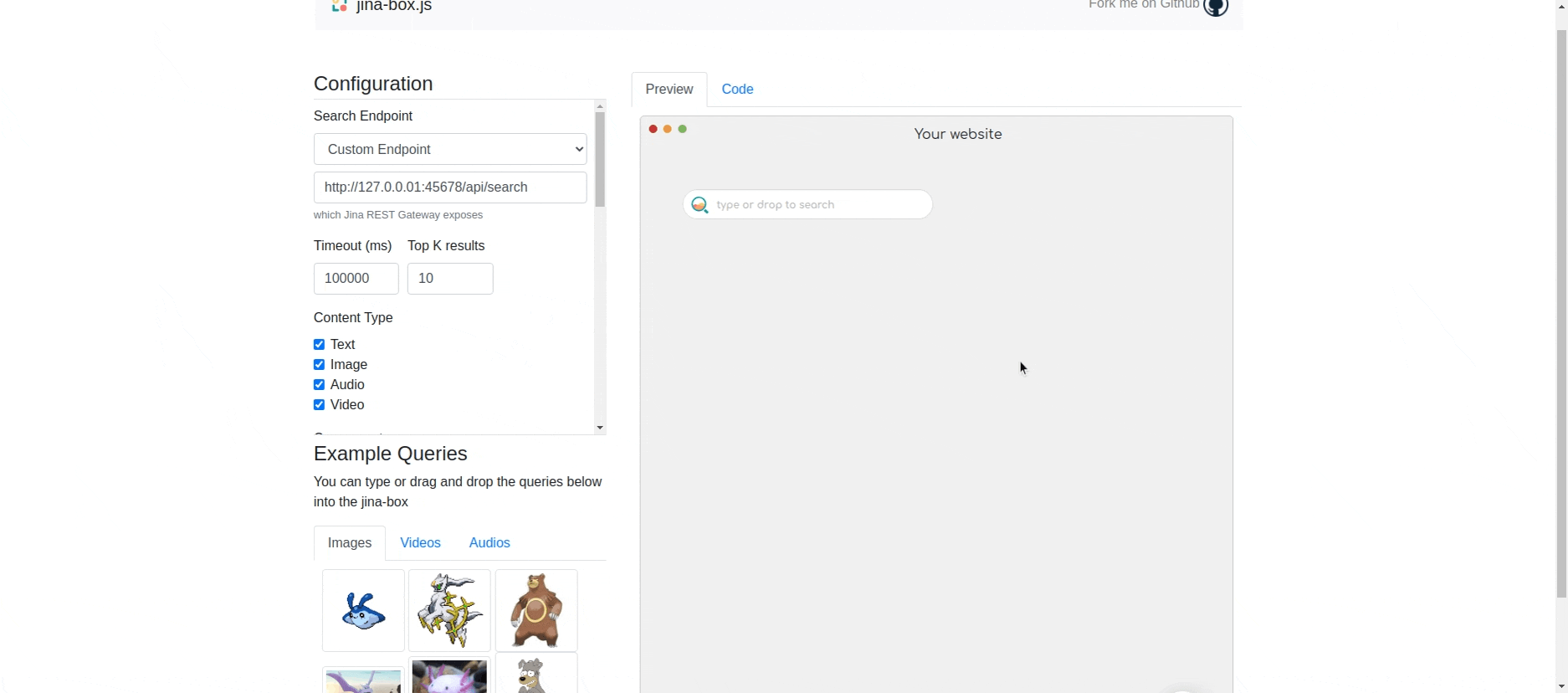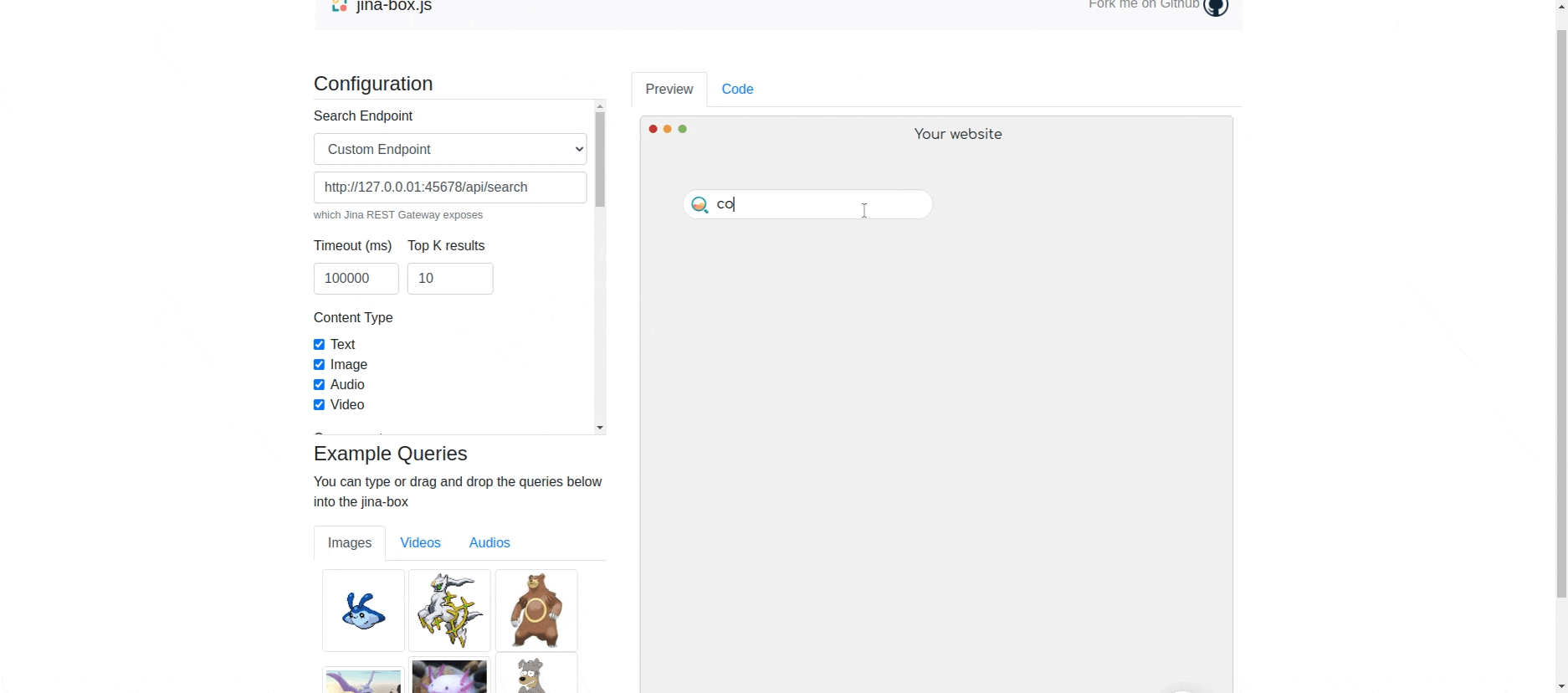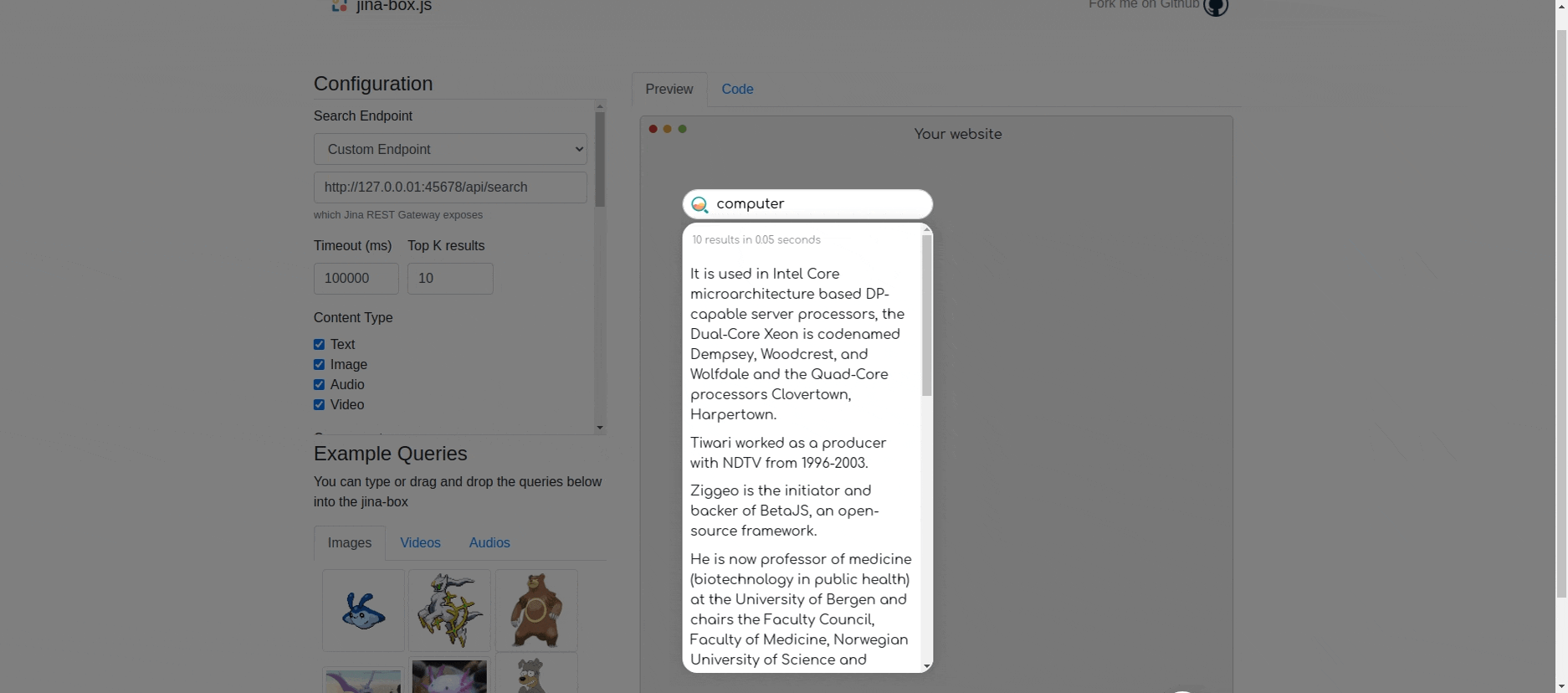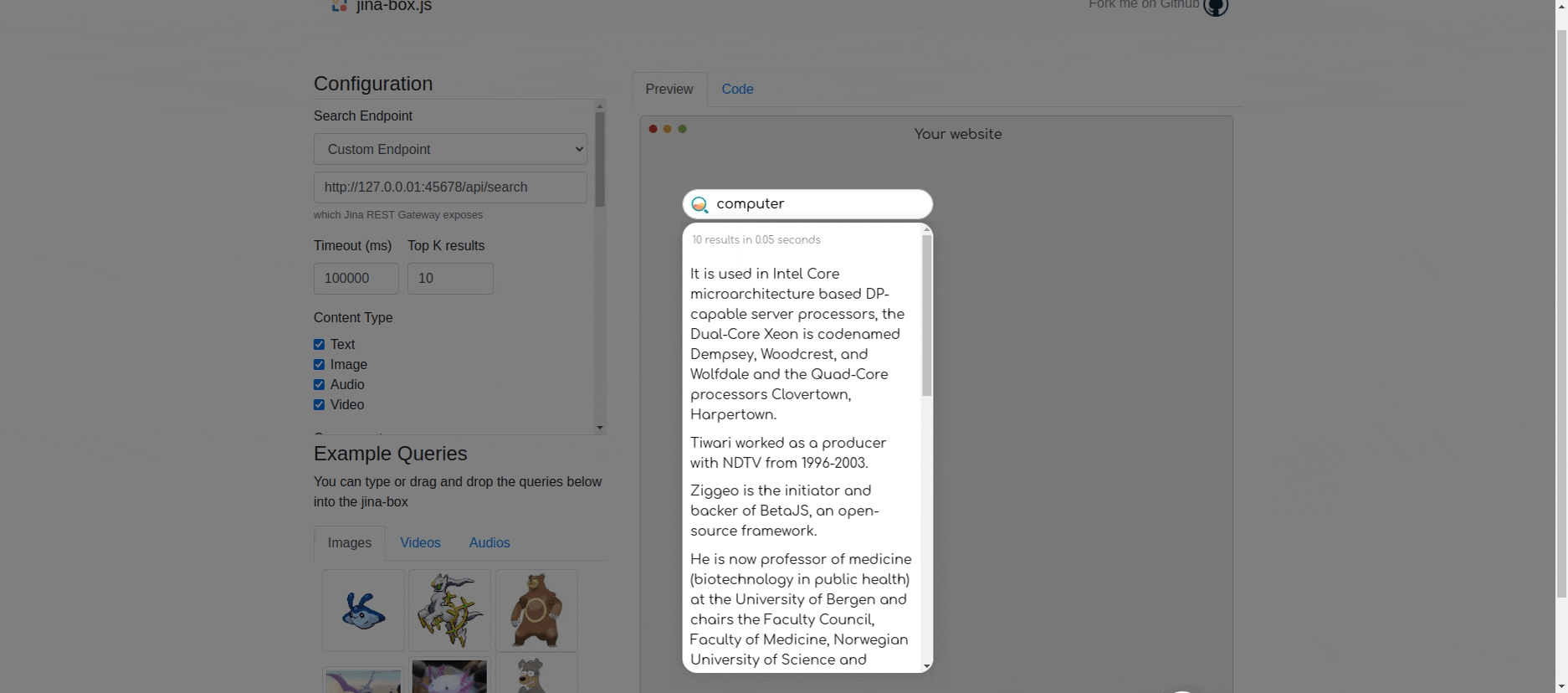
Example: Here in the search box we try to search for “computer” and get the following results. It's interesting to see that there is no mention of the exact word “computer” anywhere in the indexed document, still the model figures out the sentence which are contextually or semantically related computer.
References
If you would like to learn more or want to me write more on this subject, feel free to reach out.
My social links: LinkedIn| Twitter | Github

If you liked this post or found it helpful, please take a minute to press the clap button, it increases the post visibility for other medium users.
Next-Gen Search powered by Jina was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Related posts
Popular posts

 for 2021")



Updates

Recent Posts

