Logo:
Logo:  Areas Served:
Areas Served: 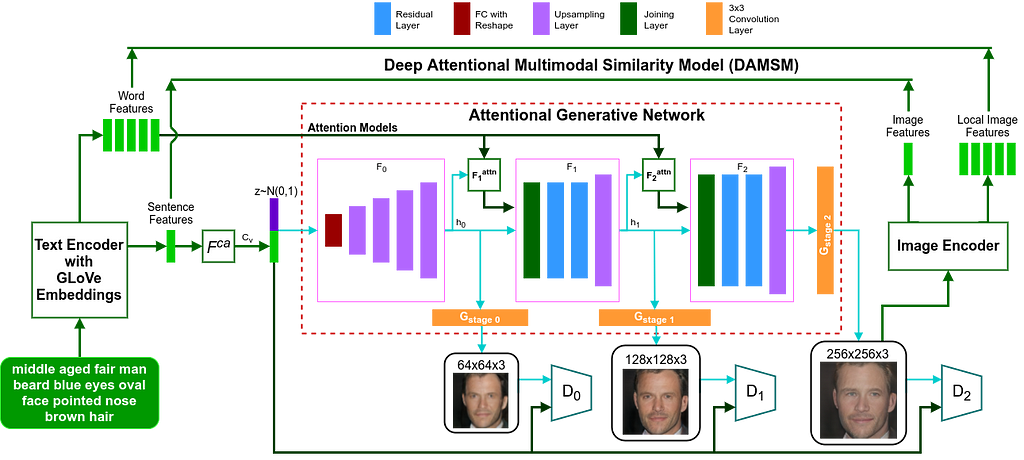
Synopsis: Multi-Attributed and Structured Text-to-Face Synthesis
Last Updated on March 24, 2022 by Editorial Team
Author(s): ROHAN WADHAWAN
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Byte-size Information to Chew on
Title: Multi-Attributed and Structured Text-to-Face Synthesis (2020)
Authors: Rohan Wadhawan, Tanuj Drall, Shubham Singh, Shampa Chakraverty
Publication Link: https://ieeexplore.ieee.org/abstract/document/9557583
Pre-Print Link: https://arxiv.org/abs/2108.11100
Keywords: Generative Adversarial Networks, Image Synthesis, Text-to-face Synthesis, MAST dataset, Multimodal Learning, Fréchet Inception Distance
Summary
The article is structured as follows:
- Problem Statement
- Paper Contribution
- Overview of Methodology
- Conclusion
- Limitations
- Future Work
- Applications
- References
- Additional Resources
Detailed analysis of topics like Generative Adversarial Network (GAN) [1] and image synthesis are beyond the scope of this article. But I have provided links to relevant resources, which will come in handy while reading the paper. Further, the visualizations shared here are taken from the original manuscript.
Problem Statement
Develop a technique for generating faces of high fidelity and diversity using textual description as input.
Paper Contribution
- Proposed the use of Generative Adversarial Network for synthesizing faces from structured textual descriptions.
- Demonstrated that increasing the number of facial attributes in textual annotations enhances the diversity and fidelity of generated faces.
- Consolidated a Multi-Attributed and Structured Text-to-Face (MAST)[2] dataset by supplementing 1993 face images taken from the CelebA-HQ [3] dataset with textual annotations.
Overview of Methodology
- Each annotation in the MAST dataset consists of 15 or more facial attributes out of possible 30 attributes. Amongst them, the following seven: face shape, eyebrows size, eyebrows shape, eye color, eyes size, eyes shape, skin complexion, were obtained via data crowdsourcing conducted by the authors [4]. Additionally, eight or more attributes like facial hair, age, gender, and accessories, were taken from the CelebA-HQ and Microsoft API [5], out of a total of 23 possibilities.
- Structured textual descriptions consist only of facial attributes and are devoid of punctuations, prepositions, and helping verbs. The authors generate five descriptions per image by randomly concatenating these attributes to simulate processed free-flowing text, as shown below.
Free flowing description -
An old man with gray hair and blue eyes. He is smiling
Processed description that resembles description in MAST dataset -
old man gray hair blue eyes smiling
- AttnGan [6] has been employed for conditional face generation from structured text data. The authors replace the pre-trained text-encoder used in the original technique with GLoVe vectors [7] in the embedding layer. These vectors cover an extensive vocabulary and render semantic relationships among the words. The GAN architecture is shown below.
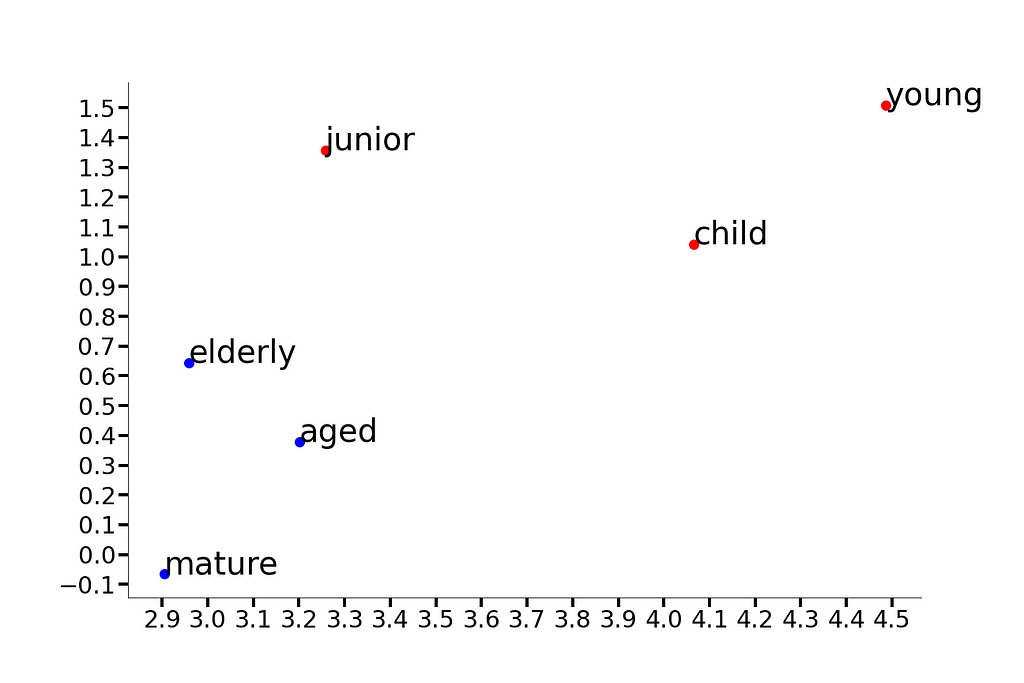
- GloVe embeddings also help sample unseen attribute values from the word cluster in the embedding space. For instance, a model trained on age attribute values like “elderly” and “aged” will be able to understand a new similar value like “mature”, as shown below.
- During GAN training, one side label smoothing [8] and alternate epoch weight updation of the discriminator has been used to tackle the gradient diminishing problem caused by the discriminator learning faster than the generator.
- Fréchet Inception Distance (FID) [9] has been used to measure the quality of generated faces, and Face Semantic Distance (FSD) and Face Semantic Similarity (FSS) [10] have been used to measure the similarity of the generated faces with the real ones.
Conclusions
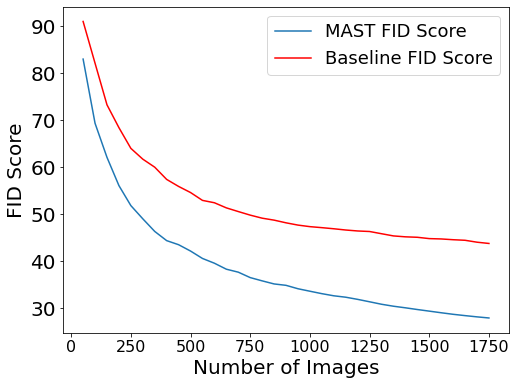
- The authors empirically prove and illustrate that increasing the number of facial attributes in a textual description, 15 or more out of possible 30 attributes, helps improve the fidelity and diversity of faces generated using that text.



- They demonstrate that the FID metric calculation is dependent on the dataset size, and it is advised to use a large testing set to report accurate values.
Limitations
The GAN network learns to correlate textual attributes with the face images in the training set. A smaller training set can be a source of potential bias and limit the variety of faces the model can generate.
Future Work
- New GAN architectures for text-to-face synthesis.
- A metric to directly measure cross-modal generation.
- A larger and more diverse dataset to further improve face generation.
Applications
- Robust and detailed facial generation of suspects from eye-witness accounts.
- Augmenting the reading experience with visual cues.
References
- I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” in Advances in neural information processing systems, 2014, pp. 2672– 2680.
- MAST dataset
- T. Karras, T. Aila, S. Laine, and J. Lehtinen, “Progressive growing of gans for improved quality, stability, and variation,” arXiv preprint arXiv:1710.10196, 2017.
- MAST dataset Crowdsourcing Website
- Microsoft Azure Face API
- T. Xu, P. Zhang, Q. Huang, H. Zhang, Z. Gan, X. Huang, and X. He, “Attngan: Fine-grained text to image generation with attentional generative adversarial networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 1316–1324.
- GloVe: Global Vectors for Word Representation
- T. Salimans, I. Goodfellow, W. Zaremba, V. Cheung, A. Radford, and X. Chen, “Improved techniques for training gans,” Advances in neural information processing systems, vol. 29, pp. 2234–2242, 2016.
- M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,” in Advances in neural information processing systems, 2017, pp. 6626–6637.
- X. Chen, L. Qing, X. He, X. Luo, and Y. Xu, “Ftgan: A fully- trained generative adversarial networks for text to face generation,” arXiv preprint arXiv:1904.05729, 2019.
Additional Resources
- Introduction to GANs, NIPS 2016 by Ian Goodfellow
- https://github.com/rohan598/Researsh-Papers-Artificial-Intelligence
- Online learning resource on Coursera-GANs Specialization
Thank you for reading this article! If you feel this post added a bit to your exabyte of knowledge, please show your appreciation by clicking on the clap icon and sharing it with whomsoever you think might benefit from this. Leave a comment below if you have any questions or find errors that might have slipped in.
Follow me in my journey of developing a Mental Map of AI research and its impact, get to know more about me at www.rohanwadhawan.com, and reach out to me on LinkedIn!
Synopsis: Multi-Attributed and Structured Text-to-Face Synthesis was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts



Popular posts

 for 2021")



Updates

Recent Posts