


Author(s): Zoheb Abai
Opinion
What’s in the Controversial Article that Forced Timnit Gebru Out of Google?
On the Dangers of Stochastic Parrots — Summarized

In short — Authors have raised global awareness on recent NLP trends and have urged researchers, developers, and practitioners associated with language technology to take a holistic and responsible approach.
Where lies the Issue?
Most notable NLP trend — the ever-increasing size (based on its number of parameters and size of training data) of Language models (LMs) like BERT and its variants, T-NLG, GPT-2/3, etc. Language Models (LMs) are trained on string prediction tasks: that is, predicting the likelihood of a token (character, word, or string) given either its preceding context or its surrounding context (in bidirectional and masked LMs). Such systems are unsupervised while training, later fine-tuned for specific tasks, and, when deployed, take a text as input, commonly outputting scores or string predictions. Increasing the number of model params/larger architecture did not yield noticeable increases for LSTMs; however, Transformers have continuously benefited from it. This trend of increasingly large LMs can be expected to continue as long as they correlate with an increase in performance. Even the models like DistilBERT and ALBERT, which are reduced form of BERT using techniques such as knowledge distillation, quantization, etc., still rely on large quantities of data and significant computing resources.

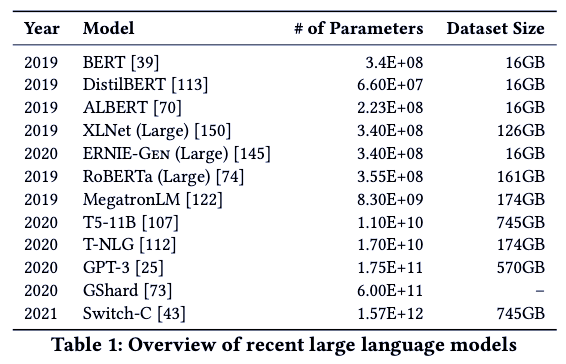
What are the Issues?
Environmental Costs
- Training a single BERT base model (without hyperparameter tuning) on GPUs was estimated to require as much energy as a trans-American flight (~1900 CO2e).

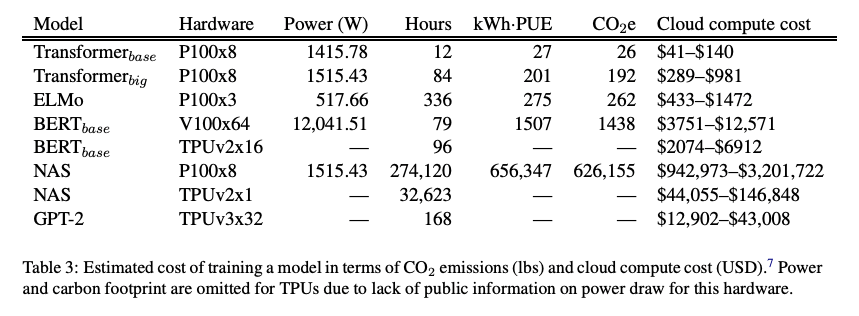
- For the task of machine translation where large LMs have resulted in performance gains, they estimate that an increase in 0.1 BLEU scores using neural architecture search for English to German translation results in an increase of $150,000 compute cost in addition to the carbon emissions.
- Most sampled papers from ACL 2018, NeurIPS 2018, and CVPR 2019 claim accuracy improvements alone as primary contributions to the field. None focused on measures of efficiency as primary contributions, which should be prioritized as the evaluation metric.
Financial Costs
- The amount of compute used to train the largest deep learning models (for NLP and other applications) has increased 300,000x in 6 years, increasing at a far higher pace than Moore’s Law. This, in turn, erects barriers to entry, limiting who can contribute to this research area and which languages can benefit from the most advanced techniques.
- Many LMs are deployed in industrial or other settings where the cost of inference might greatly outweigh that of training in the long run.
- While some language technology is genuinely designed to benefit marginalized communities, most language technology is built to serve the needs of those who already have the most privilege in society.
Risks associated with Large Training Data
- Starting with who is contributing to these Internet text collections, we see that Internet access itself is not evenly distributed, resulting in Internet data overrepresenting younger users and those from developed countries.
- A limited set of subpopulations continue to easily add data, sharing their thoughts and developing platforms that are inclusive of their worldviews; this systemic pattern, in turn, worsens diversity and inclusion within Internet-based communication, creating a feedback loop that lessens the impact of data from underrepresented populations.
- Thus at each step, from initial participation in Internet fora to continued presence there to the collection and finally the filtering of training data, current practice privileges the hegemonic viewpoint. In accepting large amounts of web text as ‘representative’ of ‘all’ of humanity, we risk perpetuating dominant viewpoints, increasing power imbalances, and further reifying inequality.
- An important caveat is that social movements that are poorly documented and do not receive significant media attention will not be captured at all. As a result, the data underpinning LMs stands to misrepresent social movements and disproportionately align with existing power regimes.
- Developing and shifting frames stand to be learned in incomplete ways or lost in the big-ness of data used to train large LMs — particularly if the training data isn’t continually updated. Given the compute costs alone of training large LMs, it likely isn’t feasible for even large corporations to fully retrain them frequently enough to keep up with the kind of language change discussed here.
- Components like toxicity classifiers would need culturally appropriate training data for each audit context, and even still, we may miss marginalized identities if we don’t know what to audit for.
- When we rely on ever-larger datasets, we risk incurring documentation debt, i.e., putting ourselves in a situation where the datasets are undocumented and too large to document post hoc. While documentation allows for potential accountability, undocumented training data perpetuates harm without recourse.
Risks due to misdirected Research Effort
(specifically around the application of LMs for tasks intended to test for Natural Language Understanding)
- The allocation of research effort towards measuring how well BERT and its kin do on both existing and new benchmarks brings with it an opportunity cost, on the one hand in terms of time not spent applying to meaning capturing approaches to meaning sensitive tasks, and on the other hand in terms of time not spent exploring more effective ways of building technology with datasets of a size that can be carefully curated and available for a broader set of languages.
- From a theoretical perspective, languages are systems of signs, i.e., pairings of form and meaning. But the training data for LMs is only a form; they do not have access to meaning. Therefore, claims about model abilities must be carefully characterized.
- LMs ties us to certain epistemological and methodological commitments. Either i) we commit ourselves to a noisy-channel interpretation of the task, ii) we abandon any goals of theoretical insight into tasks and treat LMs as “just some convenient technology,” or iii) we implicitly assume a certain statistical relationship — known to be invalid — between inputs, outputs, and meanings.
- From the perspective of work on language technology, it is far from clear that all of the effort being put into using large LMs to ‘beat’ tasks designed to test natural language understanding, and all of the effort to create new such tasks, once the LMs have bulldozed the existing ones, brings us any closer to long-term goals of general language understanding systems. If a large LM, endowed with hundreds of billions of parameters and trained on a very large dataset, can manipulate linguistic form well enough to cheat its way through tests meant to require language understanding, have we learned anything of value about building machine language understanding?
Risks and Harms of deploying LMs at Scale
Human language usage occurs between individuals who share common ground and are mutually aware of that sharing (and its extent), who have communicative intents that they use language to convey, and who model each others’ mental states as they communicate. As such, human communication relies on the interpretation of implicit meaning conveyed between individuals. The fact that human-human communication is a jointly constructed activity is most clearly true in co-situated spoken or signed communication. Still, we use the same facilities for producing language that is intended for audiences not co-present with us (readers, listeners, watchers at a distance in time or space) and in interpreting such language when we encounter it. It must follow that even when we don’t know the person who generated the language we are interpreting, we build a partial model of who they are and what common ground we think they share with us and use this in interpreting their words.
- Text generated by an LM is not grounded in communicative intent, any model of the world, or any model of the reader’s state of mind. It can’t have been because the training data never included sharing thoughts with a listener, nor does the machine have the ability to do that. This can seem counter-intuitive given the increasingly fluent qualities of automatically generated text. Still, we have to account that our perception of natural language text, regardless of how it was generated, is mediated by our own linguistic competence. Our predisposition to interpret communicative acts as conveying coherent meaning and intent, whether or not they do. The problem is, if one side of the communication does not have meaning, then the comprehension of the implicit meaning is an illusion arising from our singular human understanding of language (independent of the model). Contrary to how it may seem when we observe its output, an LM is a system for haphazardly stitching together sequences of linguistic forms observed in its vast training data, according to probabilistic information about how they combine, but without any reference to meaning: a stochastic parrot.
- LMs producing text will reproduce and even amplify the encoded biases in their training data. Thus the risk is that people disseminate text generated by LMs, meaning more text in the world that reinforces and propagates stereotypes and problematic associations, both to humans who encounter the text and future LMs trained on training sets that ingested the previous generation LM’s output.
- Miscreants can take advantage of the ability of large LMs to produce large quantities of seemingly coherent texts on specific topics on demand in cases where those deploying the LM have no investment in the truth of the generated text.
- Risks associated with large LMs during machine translation tasks to produce seemingly coherent text over larger passages could erase cues that might tip users off to translation errors in longer passages.
- Risks associated with the fact that LMs with huge numbers of parameters model their training data very closely and can be prompted to output specific information from that training data, such as personally identifiable information.
Recommended Paths Ahead!
We should consider our research time and effort a valuable resource to be spent to the extent possible on research projects that are built towards a technological ecosystem whose benefits are at least evenly distributed. Each of the below mentioned approaches take time and are most valuable when applied early in the development process as part of a conceptual investigation of values and harms rather than a post hoc discovery of risks.
- Considering Environmental and Financial Impacts: We should consider the financial and environmental costs of model development upfront before deciding on a course of an investigation. The resources needed to train and tune state-of-the-art models stand to increase economic inequities unless researchers incorporate energy and compute efficiency in their model evaluations.
- Doing careful data curation and documentation: Significant time should be spent on assembling datasets suited for the tasks at hand rather than ingesting massive amounts of data from convenient or easily-scraped Internet sources. Simply turning to massive dataset size as a strategy for being inclusive of diverse viewpoints is doomed to failure. As a part of careful data collection practices, researchers must adopt frameworks such as (Data Statements for Natural Language Processing, Datasheets for Datasets, Model Cards for Model Reporting) to describe the uses for which their models are suited and benchmark evaluations for a variety of conditions. This involves providing thorough documentation on the data used in model building, including the motivations underlying data selection and collection processes. This documentation should reflect and indicate researchers’ goals, values, and motivations in assembling data and creating a given model.
- Engaging with stakeholders early in the design process: It should note potential users and stakeholders, particularly those that stand to be negatively impacted by model errors or misuse. An exploration of stakeholders for likely use cases can still be informative around potential risks, even when there is no way to guarantee that all use cases can be explored.
- Exploring multiple possible paths towards long-term goals: We also advocate for a re-alignment of research goals: Where much effort has been allocated to making models (and their training data) bigger and to achieving ever higher scores on leaderboards often featuring artificial tasks, we believe there is more to be gained by focusing on understanding how machines are achieving the tasks in question and how they will form part of socio-technical systems. To that end, LM development may benefit from guided evaluation exercises such as pre-mortems.
- Keeping alert to dual-use scenarios: For researchers working with LMs, the value-sensitive design is poised to help throughout the development process in identifying whose values are expressed and supported through technology and, subsequently, how a lack of support might result in harm.
- Allocating research effort to mitigate harm: Finally, we would like to consider use cases of large LMs that have specifically served marginalized populations. We should consider cases such as: Could LMs be built in such a way that synthetic text generated with them would be watermarked and thus detectable? Are there policy approaches that could effectively regulate their use?
We hope these considerations encourage NLP researchers to direct resources and effort into techniques for approaching NLP tasks effectively without being endlessly data-hungry. But beyond that, we call on the field to recognize that applications that aim to mimic humans bring a risk of extreme harm believably. Work on synthetic human behavior is a bright line in ethical AI development, where downstream effects need to be understood and modeled to block foreseeable harm to society and different social groups.
Please find the complete article here and refer to its references not mentioned above. If this post saved your time, don’t forget to appreciate it.

What’s in the Controversial Article That Forced Timnit Gebru Out of Google? was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI